“数据是新的石油吗?”
在《福布斯》杂志2012年的一篇文章中,大数据的支持者曾这样问道。
到了2016年,随着深度学习的崛起——它可以说是大数据的“表亲”,有着更强劲的发展动力——我们已经变得更加确定:“数据就是新的石油。”至少《财富》杂志是这样说的。
亚马逊的尼尔·劳伦斯(Neil Lawrence)提出了一个稍有不同的比喻,他说,数据是新的煤炭。不过,他所指的并非如今的煤炭,而是18世纪初期的煤炭。那时候,托马斯·纽科门刚刚发明了蒸汽机,目的是用它从从锡矿矿井里抽水。
劳伦斯指出,这种机器的问题在于,它只对那些拥有大量煤炭的人更有用,对其他人则不然:机器很好,但并不值得专门购买煤炭来维持它的运转。事实的确如此,第一台纽科门蒸汽机并没有出现在锡矿中,而是用在了一处煤矿。

伦敦帝国学院的数据科学研究院。
那么,为什么劳伦斯把数据比喻成煤炭呢?
因为深度学习遇到的问题是类似的:这个领域当中存在很多“纽科门”,伦敦的Magic Pony和SwiftKey等初创公司正在提出革命性的方法来训练人工智能,让它们可以完成了不起的认知任务,比如基于模糊的图像重建面部数据,以及学习人类的写作风格,以便更准确地预测他们接下来会输入什么词汇。

纽科门的草垛形锅炉,它于18世纪30年代建造,是首批使用纽科门蒸汽机的设备之一。
然而,就像纽科门蒸汽机一样,这些公司的创新成果只有对真正掌握大量原始数据的人更有用。于是,Magic Pony被Twitter收购了,SwiftKey被微软收归旗下——而劳伦斯本人也是刚刚被亚马逊从英国谢菲尔德大学挖走。
不过,蒸汽机的故事还有后话:69年后,詹姆斯·瓦特对纽科门的设计做了一处精彩的改动,在蒸汽机上增加了冷凝器。按劳伦斯的话说,这一改动“让蒸汽机的效率大幅提升,并由此引发了工业革命。”
不管数据是石油还是煤炭,这种比喻在另一个层面上也能成立:我们正在开展大量工作,希望可以用更少的资源来做更多的事。
相比起让人工智能战胜人类围棋高手,这些工作可能并不那么引人注目,但如果深度学习要超越目前的境界——即“吞下”海量数据,再“吐出”尽可能准确的相关性分析——那么“数据效率”就是至关重要的一步。
“如果你看看深度学习获得成功应用的领域,你就会发现,这些领域全都拥有海量的数据。”劳伦斯指出。如果你只是想教会人工智能识别猫咪图像,现在的技术已经非常不错,但如果你想用它来诊断疑难杂症,它可就难了,因为没有多少数据可供它学习。总不能为了获得相关数据而故意让人生病吧。
AI仍然是个蠢东西
现在的问题是,尽管一些人工智能研究机构取得了种种成绩,比如谷歌旗下的DeepMind,但就真正的学习而言,计算机的表现仍然非常糟糕。如果我给你看一张陌生动物的照片,比如短尾矮袋鼠,你完全可以从另一张照片中认出它来。但是目前的技术条件,即使是经过预先训练的神经网络,你给它看第一张照片,它也万万不可能生成这种动物的识别模型。
当然,另一方面,如果你向一个深度学习系统展示几百万张短尾矮袋鼠的照片以及数百万张其他现存哺乳动物的照片,你最终很有可能得到一套哺乳动物识别系统。在识别这些毛茸茸的小动物方面,它的表现只会逊色于少数顶尖专家。
“深度学习需要海量数据来建立一幅统计图。”伦敦帝国学院的穆雷·沙纳汉(Murray Shanahan)说,“它的学习速度其实非常慢,还不如幼儿园的小孩子。”
深度学习专家已经提出多种方法来解决数据效率的问题。和这个领域的很多研究一样,这些方法的最佳思路就是模仿人类自己的大脑。
其中有一种方法涉及“渐进式神经网络”,它旨在解决很多深度学习模型在进入全新领域时都会遇到的问题:要么忽略已经学到的信息,从头开始;要么可能“遗忘”已经掌握的信息,被新的信息覆盖。
我们可以设想在以下情况中该如何抉择:当学习识别短尾矮袋鼠时,你是打算独立重新学习头部、身体、四肢和毛皮的整个概念,还是试图整合自己现有的知识,但也许会忘掉猫长什么样子?

一只六个月大的短尾矮袋鼠……很可爱,但如果没有海量数据,机器很难识别它。
莱娅·哈德塞尔(Raia Hadsell)在DeepMind负责为深度学习开发一套更好的系统,如果该公司想打造一种通用人工智能,这样的系统将必不可少。
“没有模型,没有神经网络,在通用人工智能的世界里,它既可以被训练来识别物品,也可以玩游戏,还可以学习聆听音乐。”哈德塞尔说,“我们希望做到的是,让它学习一项任务,达到专业水平,然后接着学习第二项,接着还有第三项、第四项和第五项。”
“我们希望它可以在不忘掉固有知识的前提下,做到这一切,并具备从一项任务转移到另一项任务的能力:如果我学会了一项任务,我希望学到的东西能帮助自己学习下一项任务。”这正是哈德塞尔的团队在DeepMind所从事的研究。
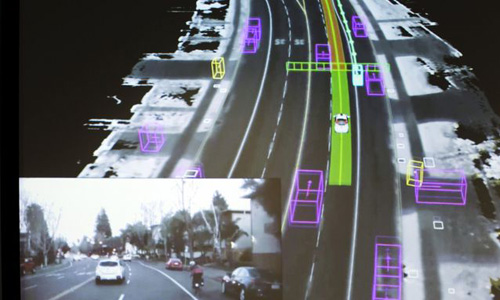
下方小图是谷歌自动驾驶汽车拍摄的视频,大图则是汽车对同一街景进行的视觉化呈现。
显然,DeepMind距离真正利用这项技术来训练一种通用人工智能还有几步之遥,这同样意味着他们离偶然间创造出一种超级人工智能也只有几步之遥了。不过,哈德塞尔表示,在提升数据效率方面,渐进式神经网络的确有一些更直接的用途。
以机器人为例。
“数据对机器人来说是一个问题,因为机器人会损坏,它们需要看管,而且成本高昂。”哈德塞尔说。一种方法是利用蛮力来解决问题:比如,谷歌的自动驾驶汽车行驶了200万英里,就是为了学会如何驾驶。起初,这种行驶只能在高速公路上进行,甚至需要司机时刻准备接管方向盘。现在,它已经可以完全抛开方向盘上路了。
另一种方法是通过模拟来教导机器人。把近似于现实世界的数据馈入机器人的传感器,它们很大程度上仍然可以正确学习:然后,你可以通过真实的训练对这种教育进行“补充”。哈德塞尔表示,这么做的最佳方式就是使用渐进式神经网络。
举一个简单的例子:使用机械臂抓起一个浮球。“我们只用一天时间就通过模拟方式完成了训练。如果要使用真正的机器人进行这种训练,需要55天时间。” 哈德塞尔说道。
教会它们思考
或者,还有另一种方法。伦敦帝国学院的沙纳汉从事人工智能研究已有相当长的时间,他依然记得人工智能第一次成为媒体焦点时的情景。那时,人工智能领域流行的方法还不是深度学习。只有当计算机的处理能力、存储空间以及数据可用性都发展成熟之后,这种方法才成为可能。当时流行的方法是“符号人工智能”:创建可以被推而广之的逻辑范式,然后馈入关于现实世界的信息,并教导它更多的东西。沙纳汉指出,符号人工智能中的‘符号’“有点像英语中的句子,描述了现实世界或某些领域的事实。”
可惜,这种方法无法规模化,人工智能研究也因此低迷了好些年。但沙纳汉认为,把两种方法结合起来能带来好处。这样不仅有助于解决数据效率问题,还可以在透明度问题上有所帮助。“对于机器做出的决策,人类很难理解其中的道理。”他说。你没法去问人工智能,它为什么认定短尾矮袋鼠就是短尾矮袋鼠。
沙纳汉的想法是建立一个符号型数据库,但并不是通过手工编码来录入信息,而是把它与另一种名为“深度强化学习”的方法结合起来。这时,人工智能就可以通过试错法进行学习,而不是通过暴力检索海量数据。DeepMind的AlphaGo在学习下围棋时,就是以此为核心方法。

世界顶级围棋手李世石与AlphaGo对弈。
为了验证概念,沙纳汉的团队开发了一个可以玩简单游戏的人工智能系统。从本质上说,这个系统接受的训练并不是直接去玩游戏,而是把游戏规则以及现状教给另一套系统,这样它就能以更抽象的方式思考正在发生的事情。
结果,当游戏规则略有变化之后,这套人工智能的表现令人眼前一亮。当传统的深度学习系统乱了手脚时,沙纳汉那套更抽象的系统却能对问题进行一般化的思考,琢磨出它与此前所用方法之间的相似处,并继续玩下去。
智能地思考
在某种程度上,数据效率的问题可能被夸大了。比如说,相对于典型的深度学习系统,你的学习速度的确可以快很多。但是,你的起点是多年以来积累的知识——那可不是一点点的数据——而且,你还存在深度学习系统所没有的弱点:你会遗忘,会忘掉很多很多东西。
这或许是高效思考系统所要付出的代价。你也许会忘了之前学会的事情,也许在检索自己掌握的知识时,耗费越来越多的资源。但如果要让深度学习走出互联网巨头的研究中心,就必须付出此番代价的话,那它或许是值得的。
本文作者:佚名
来源:51CTO