
上次我们已经搭建了Hadoop的伪分布式环境,并且运行了一下Hadoop自带的例子–WordCount程序,展现良好。但是大多数时候还是得自己写程序,编译,打包,然后运行的,所以做一次自编译打包运行的实验。
编辑程序
在Eclipse或者NetBeans中编辑WordCount.java程序,用IDE的好处就是我们可以更方便的选择各种依赖的jar包,并且它会帮我们编译好,我们只需要去workspace中拿出class文件打包就好了,或者直接打包就行。而不用在命令行输入很多依赖jar包去打包,这样更加省事。
1.新建Java Project,名为WordCount,然后建立一个叫test的package,新建WordCount.java,编辑好。结构如下:
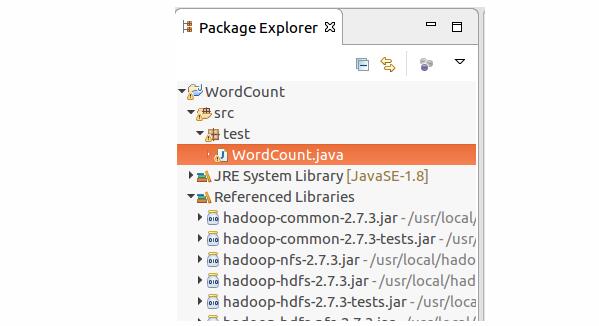
2.这时候我们的workspace/WordCount/bin/test目录下自动生成了编译好的三个class文件。
![]()
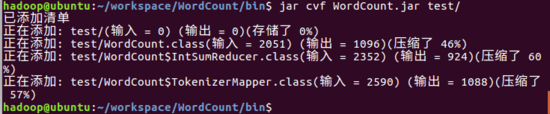
3.将class文件打包。如下图所示,在bin/test目录下输入
- $ jar cvf WordCount.jar test/
即可将class文件打包为WordCount.jar.
4.运行hdfs:
- $ cd /usr/local/hadoop
- $ ./sbin/start-dfs.sh
- $ jps //检查是否启动NameNode,DataNode等
5.往HDFS上的input文件夹中put一个文本文件或者xml文件,上篇文章有讲。比如:
- $ hadoop fs -put /usr/local/hadoop/etc/hadoop/*.xml input
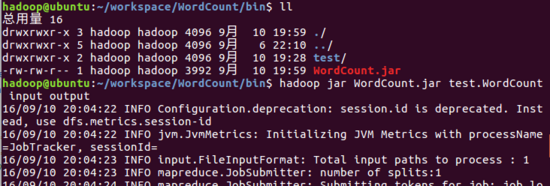
6.运行WordCount.jar
- $ cd ~/workspace/WordCount/bin //进入到WordCount.jar所在目录
- $ hadoop jar WordCount.jar test.WordCount input output
- $ hadoop fs -cat output/part-r-00000 //查看输出
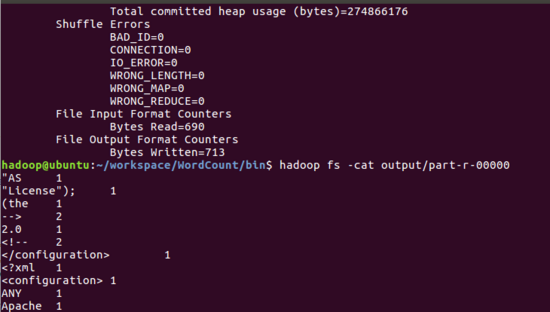
7.关闭hdfs
- $ cd /usr/local/hadoop
- $ ./sbin/stop-dfs.sh
下次运行时须将output目录删除。
到此,我们就编译运行成功了。还是挺简单的。毕竟WordCount是hadoop界的Helloworld啊。
以后我们编写hadoop程序,只需要按这个过程编译打包运行一下就可以了。
一个错误
之前没有指定包,而是放在默认包内的时候,运行
- hadoop jar WordCount.jar WordCount input output
会出现:
- Exception in thread "main" java.lang.ClassNotFoundException: WordCount
的错误,后来将WordCount.java重新写在一个package(test)中就不再有这个问题了。
即第三个参数一定要是入口类,比如程序属于包test,那么第三个参数须是 test.WordCount 。
WordCount 代码
下面的代码下载自网上,我看他还写了很多注释,就直接拿来用了。
- package test;
- import java.io.IOException;
- import java.util.StringTokenizer;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapred.JobConf;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- public class WordCount {
- /**
- * MapReduceBase类:实现了Mapper和Reducer接口的基类(其中的方法只是实现接口,而未作任何事情)
- * Mapper接口:
- * WritableComparable接口:实现WritableComparable的类可以相互比较。所有被用作key的类应该实现此接口。
- * Reporter 则可用于报告整个应用的运行进度,本例中未使用。
- *
- */
- public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
- /**
- * LongWritable, IntWritable, Text 均是 Hadoop 中实现的用于封装 Java 数据类型的类,这些类实现了WritableComparable接口,
- * 都能够被串行化从而便于在分布式环境中进行数据交换,你可以将它们分别视为long,int,String 的替代品。
- */
- private final static IntWritable one = new IntWritable(1);
- private Text word = new Text(); //Text 实现了BinaryComparable类可以作为key值
- /**
- * Mapper接口中的map方法:
- * void map(K1 key, V1 value, OutputCollector<K2,V2> output, Reporter reporter)
- * 映射一个单个的输入k/v对到一个中间的k/v对
- * 输出对不需要和输入对是相同的类型,输入对可以映射到0个或多个输出对。
- * OutputCollector接口:收集Mapper和Reducer输出的<k,v>对。
- * OutputCollector接口的collect(k, v)方法:增加一个(k,v)对到output
- */
- public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
- /**
- * 原始数据:
- * c++ java hello
- world java hello
- you me too
- map阶段,数据如下形式作为map的输入值:key为偏移量
- 0 c++ java hello
- 16 world java hello
- 34 you me too
- */
- StringTokenizer itr = new StringTokenizer(value.toString()); //得到什么值
- while (itr.hasMoreTokens()) {
- word.set(itr.nextToken());
- context.write(word, one);
- }
- }
- }
- public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
- private IntWritable result = new IntWritable();
- /**
- * reduce过程是对输入数据解析形成如下格式数据:
- * (c++ [1])
- * (java [1,1])
- * (hello [1,1])
- * (world [1])
- * (you [1])
- * (me [1])
- * (you [1])
- * 供接下来的实现的reduce程序分析数据数据
- *
- */
- public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
- int sum = 0;
- for (IntWritable val : values) {
- sum += val.get();
- }
- result.set(sum);
- context.write(key, result);
- }
- }
- public static void main(String[] args) throws Exception {
- /**
- * JobConf:map/reduce的job配置类,向hadoop框架描述map-reduce执行的工作
- * 构造方法:JobConf()、JobConf(Class exampleClass)、JobConf(Configuration conf)等
- */
- Configuration conf = new Configuration();
- String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
- //这里需要配置参数即输入和输出的HDFS的文件路径
- if (otherArgs.length != 2) {
- System.err.println("Usage: wordcount <in> <out>");
- System.exit(2);
- }
- Job job = new Job(conf, "word count"); // Job(Configuration conf, String jobName)
- job.setJarByClass(WordCount.class);
- job.setMapperClass(TokenizerMapper.class); // 为job设置Mapper类
- job.setCombinerClass(IntSumReducer.class); // 为job设置Combiner类
- job.setReducerClass(IntSumReducer.class); // 为job设置Reduce类
- job.setOutputKeyClass(Text.class); // 设置输出key的类型
- job.setOutputValueClass(IntWritable.class); // 设置输出value的类型
- FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
- FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
本文作者:佚名
来源:51CTO