1.5 为什么要学TensorFlow
首先,TensorFlow的一大亮点是支持异构设备分布式计算(heterogeneous distributed computing)。
何为异构?信息技术当中的异构是指包含不同的成分,有异构网络(如互联网,不同厂家的硬件软件产品组成统一网络且互相通信)、异构数据库(多个数据库系统的集合,可以实现数据的共享和透明访问[8])。这里的异构设备是指使用CPU、GPU等核心进行有效地协同合作;与只依靠CPU相比,性能更高,功耗更低。
那何为分布式?分布式架构目的在于帮助我们调度和分配计算资源(甚至容错,如某个计算节点宕机或者太慢),使得上千万、上亿数据量的模型能够有效地利用机器资源进行训练。
图1-9给出的是开源框架TensorFlow的标志。

图1-9
TensorFlow支持卷积神经网络(convolutional neural network,CNN)和循环神经网络(recurrent neural network,RNN),以及RNN的一个特例长短期记忆网络(long short-term memory,LSTM),这些都是目前在计算机视觉、语音识别、自然语言处理方面最流行的深度神经网络模型。
下面参考《The Unreasonable Effectiveness of Recurrent Neural Networks》[9]这篇文章梳理了一个有效框架应该具有的功能。
Tensor库是对CPU/GPU透明的,并且实现了很多操作(如切片、数组或矩阵操作等)。这里的透明是指,在不同设备上如何运行,都是框架帮用户去实现的,用户只需要指定在哪个设备上进行哪种运算即可。
有一个完全独立的代码库,用脚本语言(最理想的是Python)来操作Tensors,并且实现所有深度学习的内容,包括前向传播/反向传播、图形计算等。
可以轻松地共享预训练模型(如Caffe的模型及TensorFlow中的slim模块)。
没有编译过程。深度学习是朝着更大、更复杂的网络发展的,因此在复杂图算法中花费的时间会成倍增加。而且,进行编译的话会丢失可解释性和有效进行日志调试的能力。
在我看来,在目前的深度学习的研究领域主要有以下3类人群。
学者。主要做深度学习的理论研究,研究如何设计一个“网络模型”,如何修改参数以及为什么这样修改效果会好。平时的工作主要是关注科研前沿和进行理论研究、模型实验等,对新技术、新理论很敏感。
算法改进者。这些人为了把现有的网络模型能够适配自己的应用,达到更好的效果,会对模型做出一些改进,把一些新算法改进应用到现有模型中。这类人主要是做一些基础的应用服务,如基础的语音识别服务、基础的人脸识别服务,为其他上层应用方提供优良的模型。
工业研究者。这类人群不会涉及太深的算法,主要掌握各种模型的网络结构和一些算法实现。他们更多地是阅读优秀论文,根据论文去复现成果,然后应用到自己所在的工业领域。这个层次的人也是现在深度学习研究的主流人群。
我相信本书的读者也大都是第二类和第三类人群,且以第三类人群居多。
而在工业界,TensorFlow将会比其他框架更具优势。工业界的目标是把模型落实到产品上,而产品的应用领域一般有两个:一是基于服务端的大数据服务,让用户直接体验到服务端强大的计算能力(谷歌云平台及谷歌搜索功能);二是直接面向终端用户的移动端(Android系统)以及一些智能产品的嵌入式。
坐拥Android的市场份额和影响力的谷歌公司,在这两个方向都很强大。此外,谷歌力推的模型压缩和8位低精度数据存储(详见第 19 章)不仅对训练系统本身有优化作用,在某种程度上也能使算法在移动设备上的部署获益,这些优化举措将会使存储需求和内存带宽要求降低,并且使性能得到提升,对移动设备的性能和功耗非常有利。
如果一个框架的用户生态好,用的人就会很多,而用的人多会让用户生态更繁荣,用的人也就会更多。这庞大的用户数就是TensorFlow框架的生命力。
截至2017年1月,与Caffe、Theano、Torch、MXNet等框架相比,TensorFlow在GitHub上Fork数和Star数都是最多的,如图1-10所示。
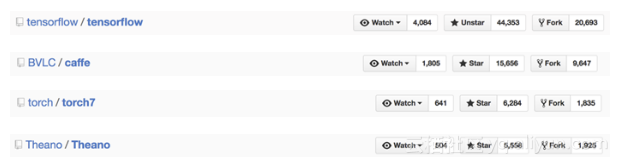
图1-10
图1-11展示了截至2017年2月,近些年几大机器学习框架的流行程度。
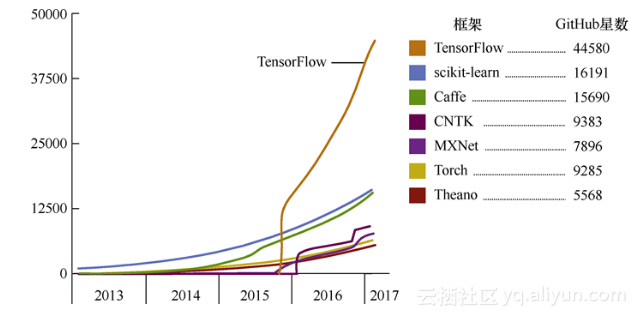
图1-11
1.5.1 TensorFlow的特性
在TensorFlow官方网站[10]上,着重介绍了TensorFlow的6大优势特性。
高度的灵活性(deep flexibility)。TensorFlow是一个采用数据流图(data flow graph),用于数值计算的开源软件库。只要计算可以表示为一个数据流图,就可以使用TensorFlow,只需要构建图,书写计算的内部循环即可。因此,它并不是一个严格的“神经网络库”。用户也可以在TensorFlow上封装自己的“上层库”,如果发现没有自己想要的底层操作,用户也可以自己写C++代码来丰富。关于封装的“上层库”,TensorFlow现在有很多开源的上层库工具,极大地减少了重复代码量,在第7章中会详细介绍。
真正的可移植性(true portability)。TensorFlow可以在CPU和GPU上运行,以及在台式机、服务器、移动端、云端服务器、Docker容器等各个终端运行。因此,当用户有一个新点子,就可以立即在笔记本上进行尝试。
将科研和产品结合在一起(connect research and production)。过去如果将一个科研的机器学习想法应用到商业化的产品中,需要很多的代码重写工作。现在TensorFlow提供了一个快速试验的框架,可以尝试新算法,并训练出模型,大大提高了科研产出率。
自动求微分(auto-differentiation)。求微分是基于梯度的机器学习算法的重要一步。使用TensorFlow后,只需要定义预测模型的结构和目标函数,将两者结合在一起后,添加相应的数据,TensorFlow就会自动完成计算微分操作。
多语言支持(language options)。TensorFlow提供了Python、C++、Java接口来构建用户的程序,而核心部分是用C++实现的,如图1-12所示。第4章中会着重讲解TensorFlow的架构。用户也可以使用Jupyter Notebook[11]来书写笔记、代码,以及可视化每一步的特征映射(feature map)。用户也可以开发更多其他语言(如Go、Lua、R等)的接口。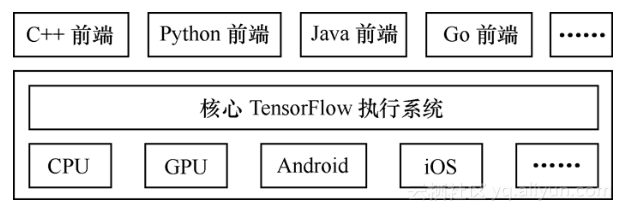
图1-12
最优化性能(maximize performance)。假如用户有一台32个CPU内核、4个GPU显卡的机器,如何将计算机的所有硬件计算资源全部发挥出来呢?TensorFlow给予线程、队列、分布式计算等支持,可以让用户将TensorFlow的数据流图上的不同计算元素分配到不同的设备上,最大化地利用硬件资源。关于线程和队列,将在4.9节中介绍;关于分布式,将在第14章介绍。
1.5.2 使用TensorFlow的公司
除了谷歌在自己的产品线上使用TensorFlow外,国内的京东、小米等公司,以及国外的Uber、eBay、Dropbox、Airbnb等公司,都在尝试使用TensorFlow。图1-13是摘自TensorFlow官方网站的日益壮大的公司墙。

图1-13
1.5.3 TensorFlow的发展
2016年4月,TensorFlow的0.8版本就支持了分布式、支持多GPU运算。2016年6月,TensorFlow的0.9版本改进了对移动设备的支持。2017年2月,TensorFlow的1.0正式版本中,增加了Java和Go的实验性API,以及专用编译器XLA和调试工具Debugger,还发布了tf.transform,专门用来数据预处理。并且还推出了“动态图计算”TensorFlow Fold,这是被评价为“第一次清晰地在设计理念上领先”[12]。
用户还可以使用谷歌公司的PaaS TensorFlow产品Cloud Machine Learning来做分布式训练。现在也已经有了完整的TensorFlow Model Zoo。
另外,TensorFlow出色的版本管理和细致的官方文档手册,以及很容易找到解答的繁荣的社区,应该能让用户用起来相当顺手。
截至2017年3月,用TensorFlow作为生产平台和科研基础研发已经越来越坚实可靠。