原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://dgd2010.blog.51cto.com/1539422/1566359
坚持不是胜利,坚持住才是胜利。
问题:比如现在有一需求,提取某个配置文件里面的ip地址,能立刻想到的就是根据字符串的规律合理的利用awk和sed来操作。
应用场景:做一套软件时,某个配置文件需要批量填写或更改已经填写好了的默认IP地址等信息(尽管在填写时IP地址可以简单的从某些文件或变量中获得,例如在Linux(CentOS6)等平台中可以借助source network congfig文件的方式)。
示例:配置文件中有这么一段,“<porttest host="192.168.0.142" application="video/portTest" timeout="10000" />”,如何取得IP地址呢?
字符串特征,该行中有两组数字,或5段数字,IP地址被“””括起来,可直接用awk截取第二段获取IP地址。
方法1,使用sed:
|
1 |
|
方法1分析:假设只有第一次匹配只匹配到一行,否则可以用head -n或tail -n来截断行,当然sed也有类似的功能。此处sed中采用了多个字命令,首先查找porttest的行,再将“host=””前的字符串换成空,再把“””后面的字符串换成空,再打印出来。
方法2,使用awk:
|
1 |
|
方法2分析,同字符串特征一样,IP地址被“””括起来,可直接用awk截取第二段获取IP地址。
处理速度测试:
|
1 2 |
|
测试结果:

sed的速度略微大于awk的速度,原因分析,可能由于awk处理的行中增加了grep和管道操作的原因。
本着测试的单一变量原则,处理一个相同的操作来比较一下。
|
1 2 |
|
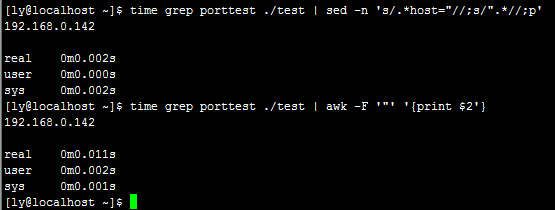
在多次测试的情况下,两者基本相似,可以说是相差并不大。
因此在实际中哪种方便就使用哪种,哪种熟练就使用哪种。
补充:sed使用正则表达式较多,擅长行处理,awk擅长列处理,更多用法可以参考《awk and sed》一书。
end
本文出自 “通信,我的最爱” 博客,请务必保留此出处http://dgd2010.blog.51cto.com/1539422/1566359