背景说明
最近处理的企业大客户问题中,出现好几例都是客户通过购买ECS进行自建Redis服务,并且在使用过程中碰到一些因云环境的内部限制等原因导致客户使用中碰到服务异常或者产品性能上无法满足业务需求的情况。每次处理过程都费时费力,TAM同学一直不辞辛苦的跟进,也拉动了ECS/Redis 研发,网络,存储等同学进去排查,又是抓包又是电话会议,最终可能排查下来都是因为场景使用上的不合理,导致客户在该过程用的不爽,我们支持得也累。
这里根据目前客户通常采用的Redis主备Sentinel架构模式,在ECS 上构建Redis环境进行性能压测,提炼出一些客户自建Redis可能潜在的一些注意事项。原则上我们建议客户都采用阿里云KVStore服务,但客户非要通过自建Redis服务,我们则需要把一些注意事项说明清楚,也尽量让客户去规避这些问题。
后面我再专门写一篇文章,综合对比阿里云KVStore围绕性能、价格、维护成本、可靠性几方面进行“性价比”,以便更好践行“客户第一”。
压测主机规格情况
| ECS 实例 | 主机IP | 规格名称 | CPU | 内存 | 磁盘 | 区域 |
|---|---|---|---|---|---|---|
| i-2ze29lbqp06cfaxebxur | 192.168.1.130 | ecs.i1.xlarge | 4核 | 16 GB | 高I/O型本地盘 104GB | 华北 2 可用区 A |
| i-2ze7ut58w9lsgtn5icbm | 192.168.1.123 | ecs.gn4-c4g1.xlarge | 4核 | 30 GB | SSD云盘 20GB | 华北 2 可用区 A |
| i-2ze7ut58w9lsgtn5icbn | 192.168.1.125 | ecs.gn4-c4g1.xlarge | 4核 | 30 GB | SSD云盘 20GB | 华北 2 可用区 A |
Redis主备Sentinel集群架构
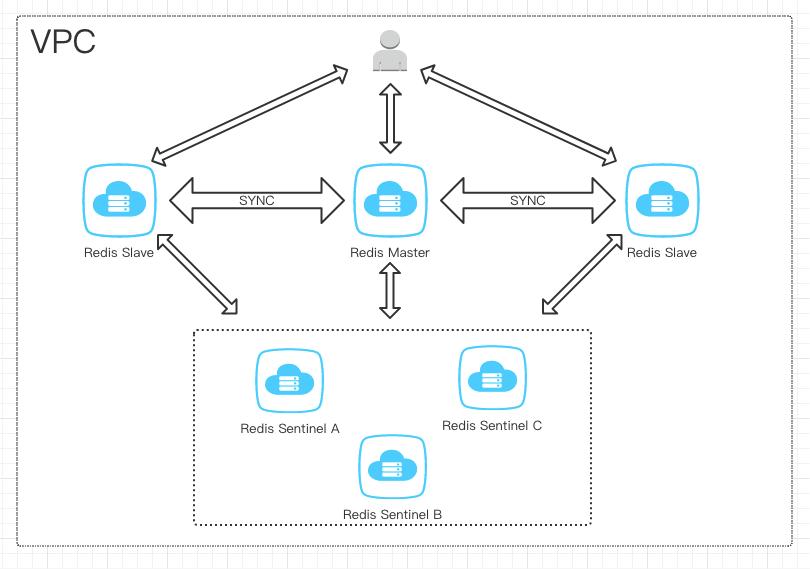
关于Sentinel 在Redis 高可用的实现上可以参阅:https://redis.io/topics/sentinel
Redis读写性能压测方法
Redis自带了可一个时间点模拟大量客户发起大量读写请求的工具
redis-benchmark(类似于Apache的ab Tool),下面为此次压测过程使用到的执行参数:
./redis-benchmark [-h <hostname>] [-a <passwrod>] [-t <tests>] [-c <clients>] [-d <size>] [-n <requests>] [-P <numreq>]
-h <hostname> Server hostname (default 127.0.0.1)
-p <port> Server port (default 6379)
-a <password> Password for Redis Auth
-t <tests> Only run the comma separated list of tests. The test
names are the same as the ones produced as output.
-c <clients> Number of parallel connections (default 50)
-d <size> Data size of SET/GET value in bytes (default 2)
-n <requests> Total number of requests (default 100000)
-r <keyspacelen> Use random keys for SET/GET/INCR, random values for SADD
Using this option the benchmark will expand the string rand_int
inside an argument with a 12 digits number in the specified range
from 0 to keyspacelen-1. The substitution changes every time a command
is executed. Default tests use this to hit random keys in the
specified range.
-P <numreq> Pipeline <numreq> requests. Default 1 (no pipeline).
e.g:
./redis-benchmark -h 192.168.1.123 -a Redis123 -t set -c 100 -d 1024 -n 1000000 -P 100
压测结果分析
开启pipeline对QPS性能的影响
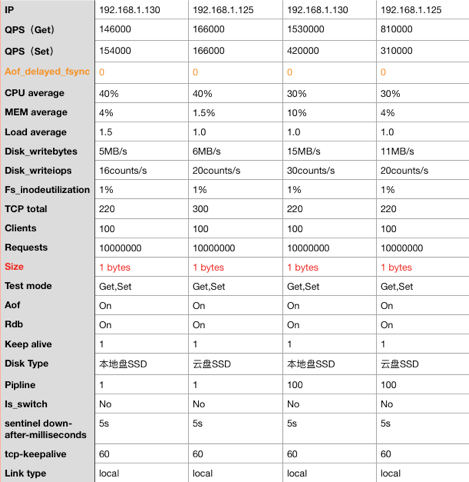
从上图可看出不同规格主机在写入value size只有一字节的情况下,不会出现Asynchronous AOF fsync is taking too long这样慢盘的情况。这种场景下,我们可暂时忽略ECS 存储盘性能影响。
在不开启Pipeline的情况下,本地盘SSD和云盘SSD都在小value读写下QPS相差无几,并且CPU、内存使用率都不高。但是在开启Pipeline的情况下,本地盘SSD比云盘SSD的读写性能要高出很多。
从Redis官网的介绍来看,Pipeline即对request做队列化,Redis Server 也对相应结果做队列化后再response,详细介绍可以参阅文档里头介绍的一个Request/Response Demo:
https://redis.io/topics/pipelining
哨兵sentinel down-after-milliseconds 参数设置对大value读写影响
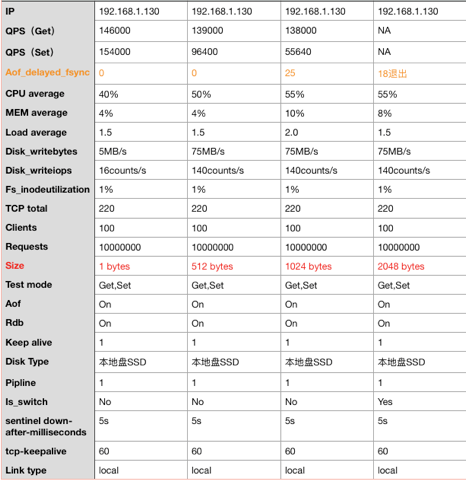
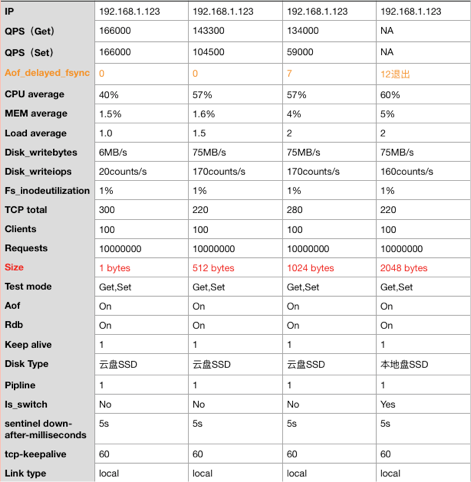
从上面2个图对比可看出无论是本地盘SSD和云盘SSD,在redis写入value大于1024字节的情况下都会出现Disk Slow的情况,并且在哨兵配置sentinel down-after-milliseconds 计时5秒的情况下,写入value大于2048字节情况下会触发主备切换。
在发生主备切换的时候,主机CPU和内存利用率都不算高,因此在自建redis并且写入value过大的场景下,慢盘看起来貌似是一个无法规避的问题(这一块还在调研中,还在咨询存储的专家,可能因系统参数设置不合理导致?!)。
假设上面的问题无法规避,因此这里down-after-milliseconds 参数设置就很关键,如果设置时间过长,会导致写入失败切换时间过长,这中间相当于服务不可用。如果设置时间过短,会导致主备切换后节点状态不一致,可能造成频繁做主备切换,甚至导致整个集群不可用。
Redis官方建议的配置时间为30秒,如果并发写入量较高,建议该时间可适当设置长一点。
同等规格写入的value大小和读写QPS的关系
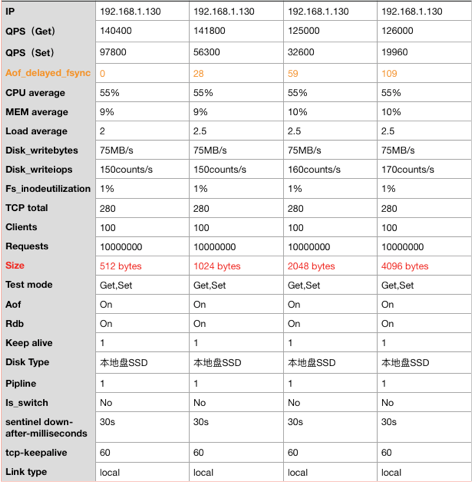
上图我把down-after-milliseconds 参数设置为官方建议的等待30秒,我们可以看到虽然触发了多次哨兵的aof_depayed_fsync计数,但是并未触发Sentinel主备切换,那么实际应用中则需要通过应用端的重试机制保证写入成功率。
我们再看看本地盘写入流量和IO情况: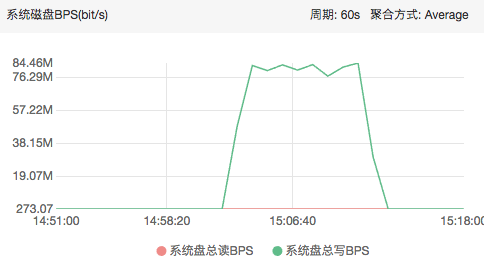
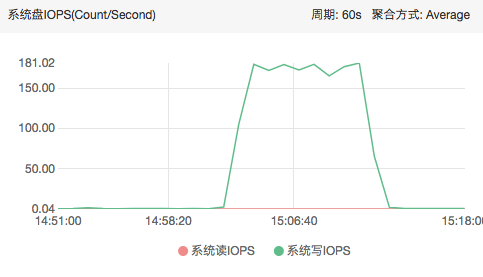
可以看到写入量BPS峰值达到87Mbit/s,峰值写IOPS达到181Count/s
而今年首推的高I/O型本地盘在512KB顺序读写应用,可提供高达300MB/s的吞吐量能力,16KB随机读写应用,可提供高达12000的随机IOPS能力;可见对磁盘压测上远远还达不到上限。
排除磁盘性能影响,可见伴随写入value的增长,相对来说读的QPS差别不是很大,但是写入的QPS会有所下降。那高I/O型本地盘怎么发挥最大性能呢?答案上面已经说了,开启pipeline。
本地连接与远程连接的QPS性能差异
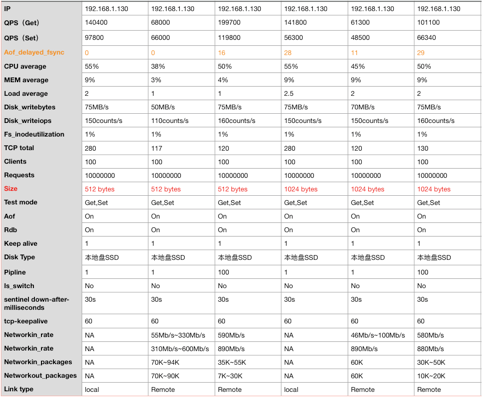
上图可以看出在同等规格写入大小一致value以及不开启pipeline的情况下,通过本地压测和远程压测的读写QPS性能差异很大,明显本地压测效果会更好点,那么远程压测的性能瓶颈在哪呢?
从访问途径上差异基本可以定位是虚拟网络的限制,其中主要关注虚拟网络内网的带宽限制和收发包数限制,我们查询了下这个规格ecs.i1.xlarge对应的限制,发现该规格的限制:
内网带宽(bit/s)为0.8G,内网收发包(PPS)为10万
因此在不开pipeline,写入value为512字节的远程写入情况下,收发包已经达到上限,故QPS就上不去了。
如果开启pipeline做队列化读写,可以大幅提供读写QPS,但内网带宽达到上限,如QPS依旧达不到本地写入的效果。
但是在实际使用场景中,基本上客户自建Redis都是通过远程写入,所以我们建议客户开启pipeline并且合理控制好虚拟内网带宽和收发包数量的限制(配置云监控),已获取一个较高的读写性能。
其他所有实例规格限制官方文档查询:
https://help.aliyun.com/document_detail/25378.html?spm=5176.doc52559.2.1.rZvgXZ#MN4
总结
客户购买ECS自建Redis Sentinel集群的情况下,推荐客户购买的ECS单独挂载使用高I/O型本地数据盘,并且对于高并发大量写入的情况下,建议设置哨兵down-after-milliseconds 大于15秒;如果写入value过大,需要留意ECS 实例规格对内网带宽和内网收发包数量的限制,建议开启pipeline实现更高的读写性能。