1 系列目录
- 分布式事务系列(开篇)提出疑问和研究过程
- 分布式事务系列(1.1)Spring事务管理器PlatformTransactionManager源码分析
- 分布式事务系列(1.2)Spring事务体系
- 分布式事务系列(2.1)分布式事务模型与接口定义
- 分布式事务系列(3.1)jotm的分布式案例
- 分布式事务系列(3.2)jotm分布式事务源码分析
- 分布式事务系列(4.1)Atomikos的分布式案例
2 三种事务模型
三种事务模型如下:
- 本地事务模型
- 编程式事务模型
- 声明式事务模型
先来看几个例子:
案例1:
Connection conn=jdbcDao.getConnection();
PreparedStatement ps=conn.prepareStatement("insert into user(name,age) value(?,?)");
ps.setString(1,user.getName());
ps.setInt(2,user.getAge());
ps.execute();
案例2:
Connection conn=jdbcDao.getConnection();
conn.setAutoCommit(false);
try {
PreparedStatement ps=conn.prepareStatement("insert into user(name,age) value(?,?)");
ps.setString(1,user.getName());
ps.setInt(2,user.getAge());
ps.execute();
conn.commit();
} catch (Exception e) {
e.printStackTrace();
conn.rollback();
}finally{
conn.close();
}
案例3:
InitialContext ctx = new InitialContext();
UserTransaction txn = (UserTransaction)ctx.lookup("UserTransaction");
try {
txn.begin();
//业务代码
txn.commit();
} catch (Exception up) {
txn.rollback();
throw up;
}
案例4:
@Transactional
public void save(User user){
jdbcTemplate.update("insert into user(name,age) value(?,?)",user.getName(),user.getAge());
}
我的看法:
- 案例1属于本地事务模型
- 案例2、3属于编程式事务模型
- 案例4属于声明式事务模型
我认为他们各自的特点在于:谁在管理着事务的提交和回滚等操作?
这里有三个角色:数据库、开发人员、spring(等第三方)
- 对于案例1:开发人员不用知道事务的存在,事务全部交给数据库来管理,数据库自己决定什么时候提交或回滚,所以数据库是事务的管理者
- 对于案例2、3:事务的提交和回滚操作完全交给开发人员,开发人员来决定事务什么时候提交或回滚,所以开发人员是事务的管理者
- 对于案例4:开发人员完全不用关心事务,事务的提交和回滚操作全部交给Spring来管理,所以Spring是事务的管理者
上述的特点也不是全部合理,如下文提到的Spring的TransactionTemplate,虽然属于编程式事务,但是它的确是把事务的提交和回滚交给了Spring来管理。总之不用过分纠结于划分事务模型
3 编程式事务
编程式事务:即通过手动编程方式来实现事务操作,大部分情况,都是类似于上述案例2、3情况,开发人员来管理事务的提交和回滚,但也可能是Spring自己来管理事务,如Spring的TransactionTemplate。
3.1 Spring的TransactionTemplate
在前一篇文章中了解到,使用jdbc操作事务,编程非常麻烦,老是需要写一套模板式的try catch代码,所以我们可以将try catch代码封装成一个模板,这就引出了Spring的TransactionTemplate:
案例如下:
TransactionTemplate template=new TransactionTemplate();
template.setIsolationLevel(TransactionDefinition.ISOLATION_DEFAULT);
template.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
template.setTransactionManager(transactionManager);
template.execute(new TransactionCallback<User>() {
@Override
public User doInTransaction(TransactionStatus status) {
//可以使用DataSourceUtils获取Connection来执行sql
//jdbcTemplate.update(sql2);
//可以使用SessionFactory的getCurrentSession获取Session来执行
//hibernateTemplate.save(user1)
return null;
}
});
- TransactionTemplate继承了DefaultTransactionDefinition,有了默认的事务定义,也可以自定义设置隔离级别、传播属性等
- TransactionTemplate需要一个PlatformTransactionManager事务管理器,来执行事务的操作
- TransactionTemplate在TransactionCallback中执行业务代码,try catch的事务模板代码,则被封装起来,包裹在业务代码的周围,详细见TransactionTemplate的execute方法,如下:

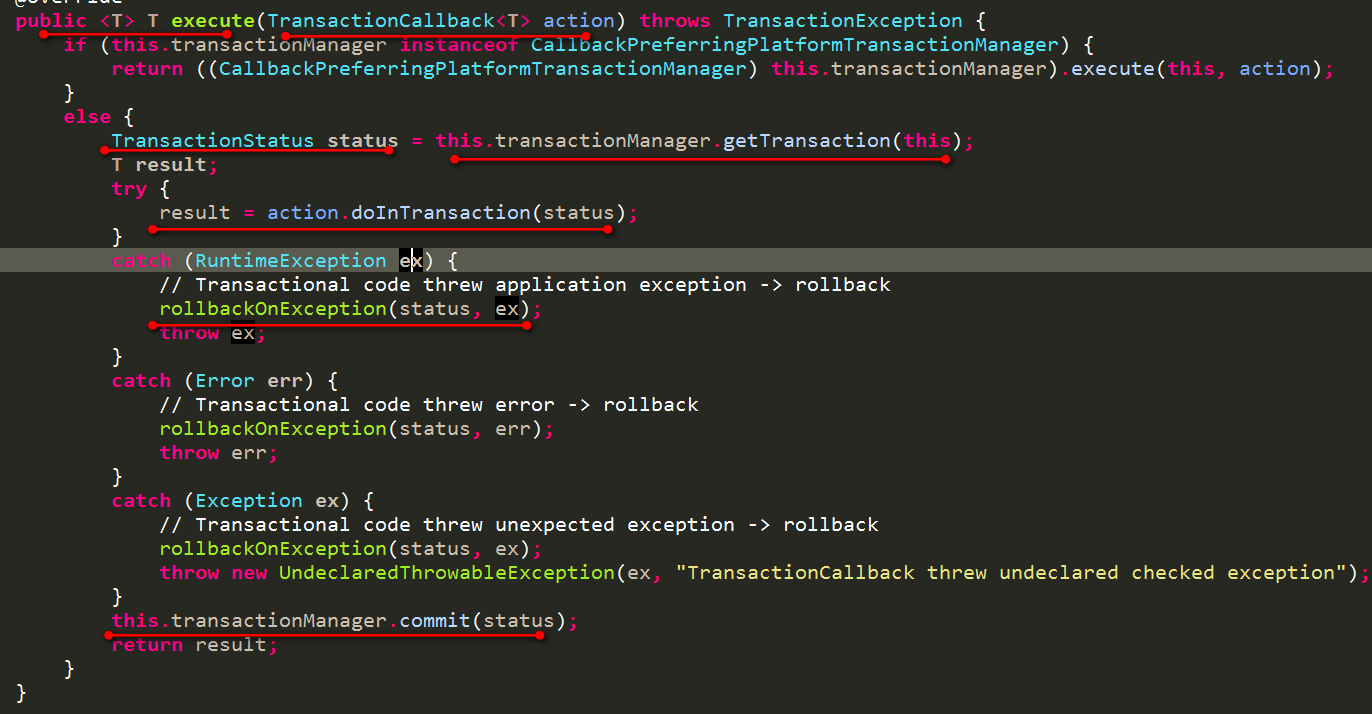
详细过程如下:
- 第一步:根据事务定义获取事务
由于TransactionTemplate继承了DefaultTransactionDefinition,所以使用PlatformTransactionManager事务管理器来根据TransactionTemplate来获取事务,这部分就是上一篇文章的内容了,见分布式事务系列(1.1)Spring事务管理器PlatformTransactionManager源码分析
- 第二步:执行业务代码
在TransactionCallback中的doInTransaction中执行相应的业务代码。
如果使用的是DataSourceTransactionManager,你就可以使用JdbcTemplate来执行业务逻辑;或者直接使用Connection,但是必须使用DataSourceUtils来获取Connection
如果使用的是HibernateTransactionManager,就可以使用HibernateTemplate来执行业务逻辑,或者则可以使用SessionFactory的getCurrentSession方法来获取当前线程绑定的Session,不可使用SessionFactory的openSession方法。也是不可乱用的,下面详细解释
- 第三步:如果业务代码出现异常,则回滚事务,没有异常则提交事务
回滚与提交都是通过PlatformTransactionManager事务管理器来进行的
3.2 事务代码和业务代码可以实现分离的原理
我们可以看到,使用TransactionTemplate,其实就做到了事务代码和业务代码的分离,分离之后的代价就是,必须保证他们使用的是同一类型事务。之后的声明式事务实现分离也是同样的原理,这里就提前说明一下。
- 1 如果使用DataSourceTransactionManager:
- 1.1 事务代码是通过和当前线程绑定的ConnectionHolder中的Connection的commit和rollback来执行相应的事务,详见上一篇文章说明事务管理器的事务分析,所以我们必须要保证业务代码也是使用相同的Connection,这样才能正常回滚与提交。
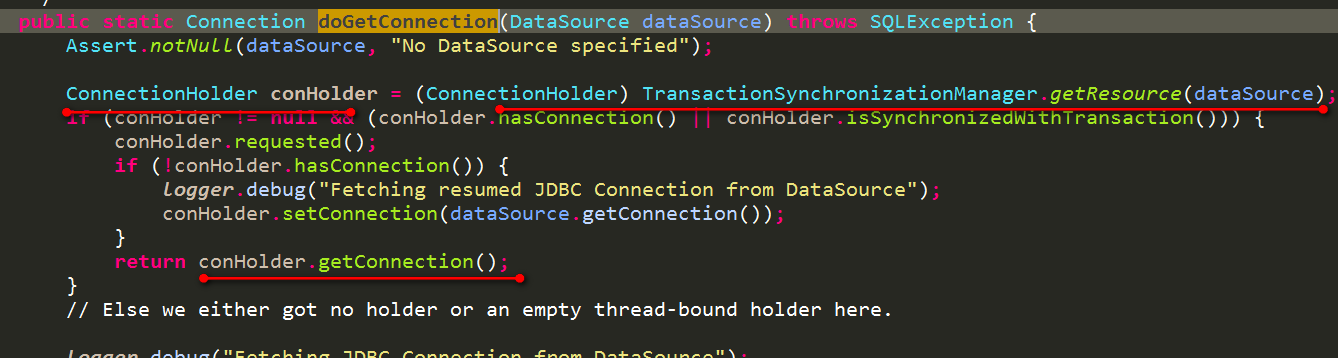
- 1.2 业务代码使用jdbcTemplate.update(sql)来执行业务,这个方法是使用的Connection从哪来的?是和上面的事务Connection是同一个吗?源码如下:
jdbcTemplate在执行sql时,会使用DataSourceUtils从dataSource中获取一个Connection。获取过程如下:
也是先获取和当前线程绑定的ConnectionHolder(由于事务在执行业务逻辑前已经开启,已经有了和当前线程绑定的ConnectionHolder),所以会获取到和事务中使用的ConnectionHolder,这样就保证了他们使用的是同一个Connection了,自然就可以正常提交和回滚了
如果想使用Connection,则需要使用DataSourceUtils从dataSorce中获取Connection,不能直接从dataSource中获取Connection。
- 2 如果使用HibernateTransactionManager:
- 2.1 事务代码是通过和当前线程绑定的SessionHolder中的Session中的Transaction的commit和rollback来执行相应的事务,详见上一篇文章说明事务管理器的事务分析,所以我们必须要保证业务代码也是使用相同的session
- 2.2业务代码就不能使用jdbcTemplate来执行相应的业务逻辑了,需要使用Session来执行相应的操作,换成对应的HibernateTemplate来执行。
HibernateTemplate在执行save(user)的过程中,会获取一个Session,方式如下:
session = getSessionFactory().getCurrentSession();
即采用SessionFactory的自带的getCurrentSession方法,获取当前Session。具体什么策略呢?
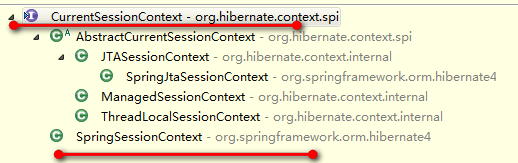
Hibernate定义了这样的一个接口:CurrentSessionContext,内容如下:
public interface CurrentSessionContext extends Serializable { public Session currentSession() throws HibernateException; }上述SessionFactory获取当前Session就是依靠CurrentSessionContext的实现。它的实现如下:
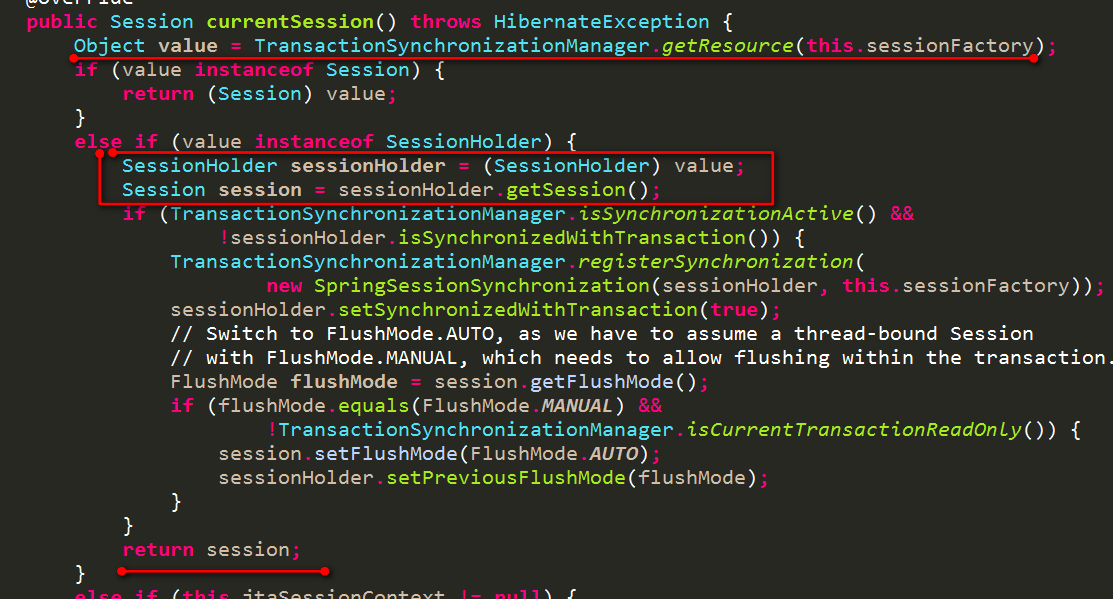
在spring环境下,默认采用的是SpringSessionContext,它获取当前Session的方式如下:
也是先获取和当前线程绑定的SessionHolder(由于事务在执行业务逻辑前已经开启,已经有了和当前线程绑定的SessionHolder),所以会获取到和事务中使用的SessionHolder,这样就保证了他们使用的是同一个Session了,自然就可以正常提交和回滚了。
如果不想通过使用HibernateTemplate,想直接通过Session来操作,同理则需要使用SessionFactory的getCurrentSession方法来获取Session,而不能使用SessionFactory的openSession方法。
以上分析都是基于Hibernate4,Hibenrate3的原理自行去看,都差不多。
4 Spring的声明式事务
Spring可以有三种形式来配置事务拦截,不同配置形式仅仅是外在形式不同,里面的拦截原理都是一样的,所以先通过一个小例子了解利用AOP实现事务拦截的原理
4.1 利用AOP实现声明式事务的原理
4.1.1 简单的AOP事务例子
从上面的Spring的TransactionTemplate我们可以实现了,事务代码和业务代码的分离,但是分离的还不彻底,还是需要如下的代码:
TransactionTemplate template=new TransactionTemplate();
template.setIsolationLevel(TransactionDefinition.ISOLATION_DEFAULT);
template.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
template.setTransactionManager(transactionManager);
一大堆的设置,同时业务代码必须嵌套在TransactionCallback中,如何才能做到如下方式的彻底分离呢?
@Transactional
public void save(User user){
jdbcTemplate.update("insert into user(name,age) value(?,?)",user.getName(),user.getAge());
}
这就需要使用Spring的AOP机制,SpringAOP的原理就不再详细说明了,可以参考这里的源码分析Spring AOP源码分析,这里给出一个简单的AOP事务拦截原理的小例子:
@Repository
public class AopUserDao implements InitializingBean{
@Autowired
private UserDao userDao;
private UserDao proxyUserDao;
@Resource(name="transactionManager")
private PlatformTransactionManager transactionManager;
@Override
public void afterPropertiesSet() throws Exception {
ProxyFactory proxyFactory = new ProxyFactory();
proxyFactory.setTarget(userDao);
TransactionInterceptor transactionInterceptor=new TransactionInterceptor();
transactionInterceptor.setTransactionManager(transactionManager);
Properties properties=new Properties();
properties.setProperty("*","PROPAGATION_REQUIRED");
transactionInterceptor.setTransactionAttributes(properties);
proxyFactory.addAdvice(transactionInterceptor);
proxyUserDao=(UserDao) proxyFactory.getProxy();
}
public void save(User user){
proxyUserDao.save(user);
}
}
代码分析如下:
- 首先需要一个原始的UserDao,我们需要对它进行AOP代理,产生代理对象proxyUserDao,之后保存的功能就是使用proxyUserDao来执行
- 对UserDao具体的代理过程如下:
- 使用代理工厂,设置要代理的对象,即target
proxyFactory.setTarget(userDao);
- 对代理对象加入拦截器
分成2种情况,一种默认拦截原UserDao的所有方法,一种是指定Pointcut,即拦截原UserDao的某些方法。
这里使用proxyFactory.addAdvice(transactionInterceptor);就表示默认拦截原UserDao的所有方法。
如果使用proxyFactory.addAdvisor(advisor),这里的Advisor可以简单看成是Pointcut和Advice的组合,Pointcut则是用于指定是否拦截某些方法。
上述addAdvice就是使用了默认的Pointcut,表示对所有方法都拦截,源码如下:
addAdvisor(pos, new DefaultPointcutAdvisor(advice));DefaultPointcutAdvisor内容如下:
public DefaultPointcutAdvisor(Advice advice) { this(Pointcut.TRUE, advice); }Pointcut.TRUE便表示拦截所有方法。
之后再详细讲解这个事务拦截器。
- 设置好代理工厂要代理的对象和拦截器后,便可以创建代理对象。
proxyUserDao=(UserDao) proxyFactory.getProxy()
之后,我们在使用创建出的proxyUserDao时,就会首先进入拦截器,执行相关拦截器代码,因此我们可以在这里实现事务的处理
- 使用代理工厂,设置要代理的对象,即target
4.1.2 事务拦截器的原理分析
事务拦截器需要2个参数:
- 事务配置的提供者
用于指定哪些方法具有什么样的事务配置
可以通过属性配置方式,或者通过其他一些配置方式,如下三种方式都是为了获取事务配置提供者:
- 方式1:
<property name="transactionAttributes"> <props> <prop key="*">PROPAGATION_REQUIRED</prop> </props> </property>
- 方式2:
<tx:attributes>
<tx:method name="add*" propagation="REQUIRED" /> <tx:method name="delete*" propagation="REQUIRED" /> <tx:method name="update*" propagation="REQUIRED" /> <tx:method name="add*" propagation="REQUIRED" /></tx:attributes>
- 方式3:
@Transactional(propagation=Propagation.REQUIRED)
- 方式1:
- 事务管理器PlatformTransactionManager
有了事务的配置,我们就可以通过事务管理器来获取事务了。
在执行代理proxyUserDao的save(user)方法时,会先进入事务拦截器中,具体的拦截代码如下:
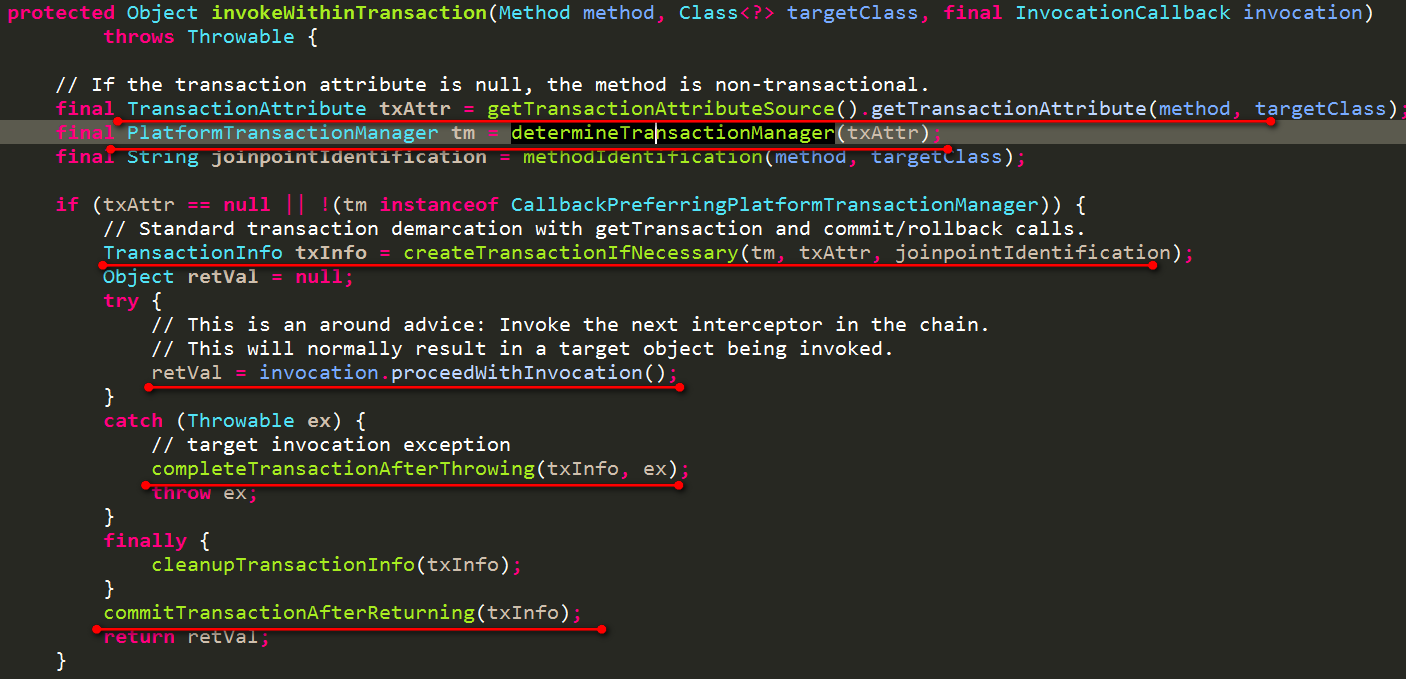
- 第一步:首先获取所执行方法的对应的事务配置
- 第二步:然后获取指定的事务管理器PlatformTransactionManager
- 第三步:根据事务配置,使用事务管理器创建出事务
- 第四步:继续执行下一个拦截器,最终会执行到代理的原始对象的方法
- 第五步:一旦执行过程发生异常,使用事务拦截器进行事务的回滚
- 第六步:如果没有异常,则使用事务拦截器提交事务
一个事务拦截器的内容大致就是这样。
4.2 Spring的三种事务配置形式
4.2.1 使用TransactionProxyFactoryBean
配置案例如下:
<bean id="proxy"
class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<!-- 为事务代理工厂Bean注入事务管理器 -->
<property name="transactionManager" ref="transactionManager" />
<!-- 要在哪个Bean上面创建事务代理对象 -->
<property name="target" ref="productDao" />
<!-- 指定事务属性 -->
<property name="transactionAttributes">
<props>
<prop key="*">PROPAGATION_REQUIRED</prop>
</props>
</property>
</bean>
案例分析:
上面有三大配置:
- 事务管理器transactionManager
- 事务配置的提供者transactionAttributes(用于指定哪些方法具有什么样的事务配置)
有了以上2个元素,我们就可以创建出一个事务拦截器TransactionInterceptor
- 要代理的对象target
TransactionProxyFactoryBean这个工厂bean创建代理对象的原理就是:通过ProxyFactory来对target创建出代理对象了,同时加入上述事务拦截器,就可以实现事务拦截功能了
4.2.2 使用aop:config和tx:advice
使用TransactionProxyFactoryBean的方式只能针对一个target进行代理,如果想再代理一个target,就需要再配置一个TransactionProxyFactoryBean,比较麻烦,所以使用apo:config的配置形式,就可以针对符合Pointcut的所有target都可以进行代理。
配置案例如下:
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="add*" propagation="REQUIRED" />
<tx:method name="delete*" propagation="REQUIRED" />
<tx:method name="update*" propagation="REQUIRED" />
<tx:method name="add*" propagation="REQUIRED" />
</tx:attributes>
</tx:advice>
<aop:config>
<aop:pointcut id="pointcut"
expression="XXXX" />
<aop:advisor advice-ref="txAdvice"
pointcut-ref="pointcut" />
</aop:config>
这里有2种配置:
- tx:advice:
有事务管理器transactionManager和事务配置提供者attributes,就可以产生一个事务拦截器TransactionInterceptor
- aop:config:
这里会对符合pointcut的bean创建出代理对象,同时加入上述创建的事务拦截器
4.2.3 使用@Transactional
使用aop:config可以在xml中进行代理的配置,有时候想在代码中直接进行配置,这时候就需要使用注解@Transactional。
案例如下:
xml中启动@Transactional注解扫描
<tx:annotation-driven transaction-manager="transactionManager" />
在代码中就可以通过配置@Transactional来实现事务拦截了
@Transactional(propagation=Propagation.REQUIRED)
public void save(User user){
xxxx
}
在xml配置中启动注解扫描,会把那些加入了@Transactional标记的容器bean创建出代理对象,同时加入事务拦截器。在执行事务拦截的时候,会从@Transactional注解中取出对应的事务配置和事务管理器配置,进而可以执行事务的创建等操作。
5 结束语
至此Spring的事务体系大概就讲完了,接下来就要说明如何实现分布式事务了,在涉及jotm、atomikos这些第三方框架之前,先要了解下,分布式事务的一些概念
- 1 X/Open DTP模型、XA规范、2PC
- 2 JTA、JTS概念
- 3 JTA接口定义的理解