“数据驱动决策”,为了不让这句话成为空话,请先装备以下13种思想武器,将来你一定能用上!~

文/胡晨川
第一、信度与效度思维
这部分也许是全文最难理解的部分,但我觉得也最为重要。没有这个思维,决策者很有可能在数据中迷失。
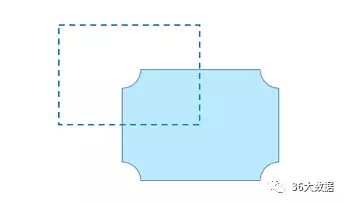
信度与效度
信度与效度的概念最早来源于调查分析,但现在我觉得可以引申到数据分析工作的各方面。
所谓信度,是指一个数据或指标自身的可靠程度,包括准确性和稳定性取数逻辑是否正确?有没有计算错误?这属于准确性;每次计算的算法是否稳定?口径是否一致?以相同的方法计算不同的对象时,准确性是否有波动?这是稳定性。
做到了以上两个方面,就是一个好的数据或指标了?其实还不够,还有一个更重要的因素,就是效度!
所谓效度,是指一个数据或指标的生成,需贴合它所要衡量的事物,即指标的变化能够代表该事物的变化。
只有在信度和效度上都达标,才是一个有价值的数据指标。
举个例子:要衡量我身体的肥胖情况,我选择了穿衣的号码作为指标,一方面,相同的衣服尺码对应的实际衣服大小是不同的,会有美版韩版等因素,使得准确性很差;同时,一会儿穿这个牌子的衣服,一会儿穿那个牌子的衣服,使得该衡量方式形成的结果很不稳定;所以,衣服尺码这个指标的信度不够。
另一方面,衡量身体肥胖情况用衣服的尺码大小?你一定觉得荒唐,尺码大小并不能反映肥胖情况,是吧?因此效度也不足。体脂率,才是信度和效度都比较达标的肥胖衡量指标。
在我们的现实工作中,许多人会想当然地拿了指标就用,这是非常值得警惕的。你要切骨头却拿了把手术刀,是不是很可悲?信度和效度的本质,其实就是数据质量的问题,这是一切分析的基石,再怎么重视都不过分!!
第二、平衡思维
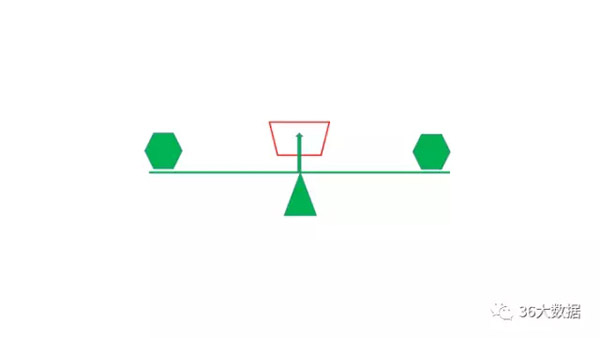
平衡
说到天平大家都不陌生,平衡的思维相信各位也都能很快理解。简单来说,在数据分析的过程中,我们需要经常去寻找事情间的平衡关系,且平衡关系往往是关乎企业运转的大问题,如市场的供需关系,薪资与效率关系,工作时长与错误率的关系等等。
平衡思维的关键点,在于寻找能展示出平衡状态的指标!也就是如图中红框,我们要去寻找这个准确的量化指标,来观察天平的倾斜程度。
怎么找这个指标呢?以我的经验,一般先找双向型的问题,即高也不是低也不是的问题,然后量化为指标,最后计算成某个比率,长期跟踪后,观察它的信度和效度。
第三、分类思维
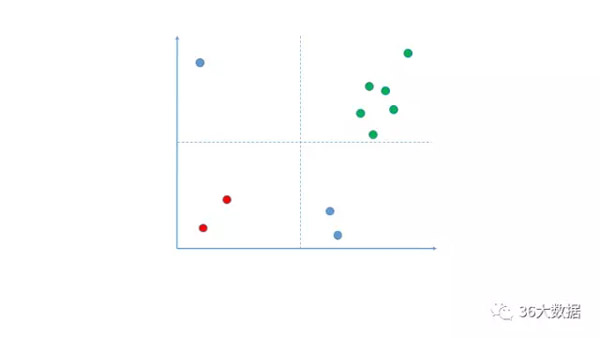
分类
客户分群、产品归类、市场分级、绩效评价...许多事情都需要有分类的思维。主管拍脑袋也可以分类,通过机器学习算法也可以分类,那么许多人就模糊了,到底分类思维怎么应用呢?
关键点在于,分类后的事物,需要在核心关键指标上能拉开距离!也就是说分类后的结果,必须是显著的。如图,横轴和纵轴往往是你运营当中关注的核心指标(当然不限于二维),而分类后的对象,你能看到他们的分布不是随机的,而是有显著的集群的倾向。
举个例子,假设该图反映了某个消费者分群的结果,横轴代表购买频率,纵轴代表客单价,那么绿色的这群人,就是明显的“人傻钱多”的“剁手金牌客户”。
第四、矩阵思维
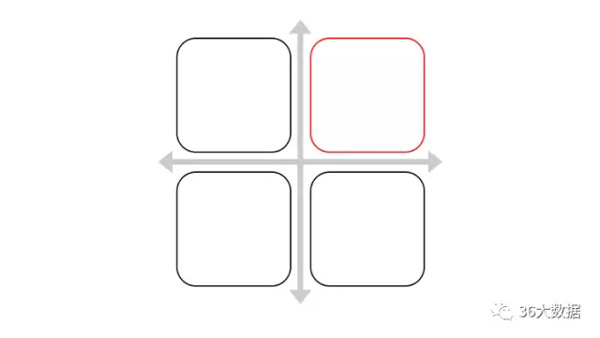
矩阵化
矩阵思维是分类思维的发展,它不再局限于用量化指标来进行分类。许多时候,我们没有数据做为支持,只能通过经验做主管的推断时,是可以把某些重要因素组合成矩阵,大致定义出好坏的方向,然后进行分析。大家可以百度经典的管理分析方法“波士顿矩阵”模型。
第五、管道/漏斗思维

管道/漏斗
这种思维方式已经比较普及了,注册转化、购买流程、销售管道、浏览路径等,太多的分析场景中,能找到这种思维的影子。
但我要说,看上去越是普世越是容易理解的模型,它的应用越得谨慎和小心。在漏斗思维当中,我们尤其要注意漏斗的长度。
漏斗从哪里开始到哪里结束?以我的经验,漏斗的环节不该超过5个,且漏斗中各环节的百分比数值,量级不要超过100倍(漏斗第一环节100%开始,到最后一个环节的转化率数值不要低于1%)。若超过了我说的这两个数值标准,建议分为多个漏斗进行观察。当然,这两个是经验数值,仅仅给各位做个参考~
理由是什么呢?超过5个环节,往往会出现多个重点环节,那么在一个漏斗模型中分析多个重要问题容易产生混乱。数值量级差距过大,数值间波动相互关系很难被察觉,容易遗漏信息。
比如,漏斗前面环节从60%变到50%,让你感觉是天大的事情,而漏斗最后环节0.1%的变动不能引起你的注意,可往往是漏斗最后这0.1%的变动非常致命。
第六、相关思维
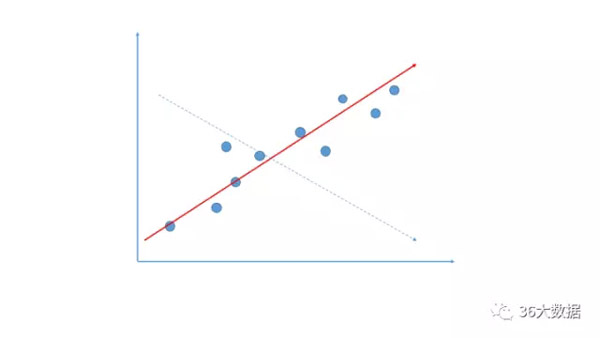
相关
我们观察指标,不仅要看单个指标的变化,还需要观察指标间的相互关系!有正相关关系(图中红色实线)和负相关关系(蓝色虚线)。最好能时常计算指标间的相关系数,定期观察变化。
相关思维的应用太广了,我这里就说一点,往往是被大家忽略的。现在的很多企业管理层,面对的问题并不是没有数据,而是数据太多,却太少有用的数据。相关思维的其中一个应用,就是能够帮助我们找到最重要的数据,排除掉过多杂乱数据的干扰!
如何执行呢?你可以计算能收集到的多个指标间的相互关系,挑出与其他指标相关系数都相对较高的数据指标,分析它的产生逻辑,对应的问题,并评估信度和效度,若都满足标准,这个指标就能定位为核心指标!
建议大家养成一个习惯,经常计算指标间的相关系数,仔细思考相关系数背后的逻辑,有的是显而易见的常识,比如订单数和购买人数,有的或许就能给你带来惊喜!另外,“没有相关关系”,这往往也会成为惊喜的来源哦。
第七、远近度思维
远近度
现在与许多处在管理层的朋友交流后,发现他们往往手握众多数据和报表,注意力却是非常的跳跃和分散。这当然不是好现象,但如何避免呢?一是上文说的通过相关思维,找到最核心的问题和指标;二就是这部分要说的,建立远进度的思维方式。
确定好核心问题后,分析其他业务问题与该核心问题的远近程度,由近及远,把自己的精力有计划地分配上去。
比如,近期你地核心任务就是提高客服人员的服务质量,那么客服人员的话术、客户评价通道、客服系统的相应速度等就是靠的最近的子问题,需要重点关注,而客户的问询习惯、客户的购买周期等就是相对远的问题,暂时先放一放。当然,本人经历有限,例子举得不恰当的地方还望读者们海涵。
第八、逻辑树思维
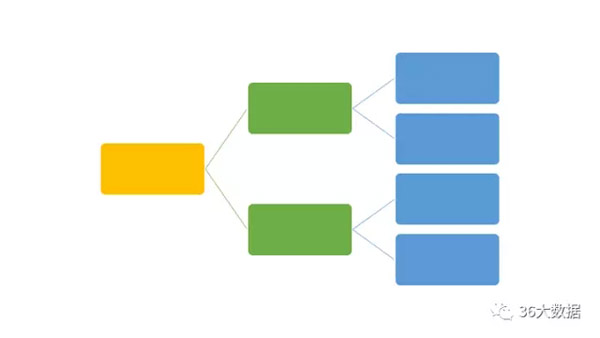
逻辑树
如图的树状逻辑相信大家已经见过许多回了。一般说明逻辑树的分叉时,都会提到“分解”和“汇总”的概念。我这里把它变一变,使其更贴近数据分析,称为“下钻”和“上卷”。
当然,这两个词不是我发明的,早已有之。所谓下钻,就是在分析指标的变化时,按一定的维度不断的分解。比如,按地区维度,从大区到省份,从省份到城市,从省市到区。所谓上卷就是反过来。随着维度的下钻和上卷,数据会不断细分和汇总,在这个过程中,我们往往能找到问题的根源。
下钻和上卷并不是局限于一个维度的,往往是多维组合的节点,进行分叉。逻辑树引申到算法领域就是决策树。
有个关键便是何时做出决策(判断)。当进行分叉时,我们往往会选择差别最大的一个维度进行拆分,若差别不够大,则这个枝桠就不在细分。能够产生显著差别的节点会被保留,并继续细分,直到分不出差别为止。经过这个过程,我们就能找出影响指标变化的因素。
举个简单的例子:我们发现全国客户数量下降了,我们从地区和客户年龄层级两个维度先进行观察,发现各个年龄段的客户都下降,而地区间有的下降有的升高。
那我们就按地区来拆分第一个逻辑树节点,拆分到大区后,发现各省间的差别是显著的,那就继续拆分到城市,最终发现是浙江省杭州市大量客户且涵盖各个年龄段,被竞争对手的一波推广活动转化走了。就此通过三个层级的逻辑树找到了原因。
第九、时间序列思维
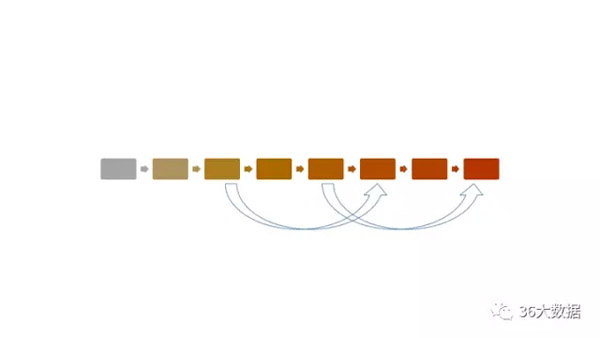
时间序列
很多问题,我们找不到横向对比的方法和对象,那么,和历史上的状况比,就将变得非常重要。
其实很多时候,我更愿意用时间维度的对比来分析问题,毕竟发展地看问题,也是“红色方法论”中的重要一环。这种方式容易排除掉一些外在的干扰,尤其适合创新型的分析对象,比如一个新行业的公司,或者一款全新的产品。
时间序列的思维有三个关键点:
一是距今越近的时间点,越要重视(图中的深浅度,越近期发生的事,越有可能再次发生);
二是要做同比(图中的尖头指示,指标往往存在某些周期性,需要在周期中的同一阶段进行对比,才有意义);
三是异常值出现时,需要重视(比如出现了历史最低值或历史最高值,建议在时间序列作图时,添加平均值线和平均值加减一倍或两倍标准差线,便于观察异常值)。
时间序列思维有一个子概念不得不提一下,就是“生命周期”的概念。用户、产品、人事等无不有生命周期存在。本人最近也正在将关注的重心移向这块,直觉上,生命周期衡量清楚,就能很方便地确定一些“阀值”问题,使产品和运营的节奏更明确。
第十、队列分析思维
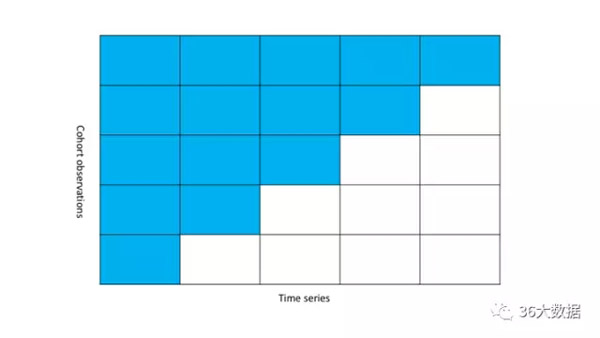
队列思维
随着数据运算能力的提高,队列分析的方式逐渐展露头脚。英文名称为cohort analysis,说实话我不知道怎么表述这个概念,我的理解就是按一定的规则,在时间颗粒度上将观察对象切片,组成一个观察样本,然后观察这个样本的某些指标随着时间的演进而产生的变化。目前使用得最多的场景就是留存分析。
举个经常用的例子:假设5.17我们举办了一次促销活动,那么将这一天来的新用户作为一个观察样本,观察他们在5.18、5.19...之后每天的活跃情况。
队列分析中,指标其实就是时间序列,不同的是衡量样本。队列分析中的衡量样本是在时间颗粒上变化的,而时间序列的样本则相对固定。
第十一、循环/闭环思维
闭环
循环/闭环的概念可以引申到很多场景中,比如业务流程的闭环、用户生命周期闭环、产品功能使用闭环、市场推广策略闭环等等。许多时候你会觉得这是一个不落地的概念,因为提的人很多,干出事情来的例子很少。
但我觉得这种思考方式是非常必要的。业务流程的闭环是管理者比较容易定义出来的,列出公司所有业务环节,梳理出业务流程,然后定义各个环节之间相互影响的指标,跟踪这些指标的变化,能从全局上把握公司的运行状况。
比如,一家软件公司的典型业务流:推广行为(市场部)——流量进入主站(市场+产研)——注册流程(产研)——试用体验(产研+销售)——进入采购流程(销售部)——交易并部署(售后+产研)——使用、续约、推荐(售后+市场)——推广行为,一个闭环下来,各个衔接环节的指标,就值得关注了:广告点击率——注册流程进入率——注册转化率——试用率——销售管道各环节转化率——付款率——推荐率/续约率...这里会涉及漏斗思维,如前文所述,千万不要用一个漏斗来衡量一个循环。
有了循环思维,你能比较快的建立有逻辑关系的指标体系。
第十二、测试/对比思维

测试
AB test,大家肯定不陌生了。那么怎么细化一下这个概念?一是在条件允许的情况下,决策前尽量做对比测试;二是测试时,一定要注意参照组的选择,建议任何实验中,都要留有不进行任何变化的一组样本,作为最基本的参照。
现在数据获取越来越方便,在保证数据质量的前提下,希望大家多做实验,多去发现规律。
指数化思维

指数化
指数化思维,是指将衡量一个问题的多个因素分别量化后,组合成一个综合指数(降维),来持续追踪的方式。把这个放在最后讨论,目的就是强调它的重要性。前文已经说过,许多管理者面临的问题是“数据太多,可用的太少”,这就需要“降维”了,即要把多个指标压缩为单个指标。
指数化的好处非常明显,一是减少了指标,使得管理者精力更为集中;二是指数化的指标往往都提高了数据的信度和效度;三是指数能长期使用且便于理解。
指数的设计是门大学问,这里简单提三个关键点:一是要遵循独立和穷尽的原则;二是要注意各指标的单位,尽量做标准化来消除单位的影响;三是权重和需要等于1。
独立穷尽原则,即你所定位的问题,在搜集衡量该问题的多个指标时,各个指标间尽量相互独立,同时能衡量该问题的指标尽量穷尽(收集全)。
举个例子:当初设计某公司销售部门的指标体系时,目的是衡量销售部的绩效,确定了核心指标是销售额后,我们将绩效拆分为订单数、客单价、线索转化率、成单周期、续约率5个相互独立的指标,且这5个指标涵盖了销售绩效的各个方面(穷尽)。
我们设计的销售绩效综合指数=0.4*订单数+0.2*客单价+0.2*线索转化率+0.1*成单周期+0.1*续约率,各指标都采用max-min方法进行标准化。
通过这个例子,相信各位就能理解指数化思维了。
小节
本篇内容在我脑中酝酿了2月有余了,但当起笔成文时,依然觉得自己的思考还不够全面,经验也不够丰富。各种思维方式的应用,似乎没有孰好孰坏,是否启用看似也比较随机。希望随着我经历的不断丰富,能够总结出一套行之有效的思维技巧,但目前还不行。
总的来说,数据质量依然是我觉得最大的前提。重要事情说三遍,动手前,一定要保证好数据质量!
本文作者:胡晨川
来源:51CTO