协同消费库(ConsumerLibrary) 是并行对 LogHub 中日志进行消费的高级模式,提供了消费组(ConsumerGroup)概念对实时消费端进行抽象与管理。Spark Streaming、Storm、即将推出的 Flink SDK 都是基于这种模式的包装。
注意:有关 ConsumerGroup 概念及使用方法,参考下面的文档:
1. 通过 ConsumerLib 实现不丢、保序、去重
2. ConsumerLib 使用
3. 查看协同消费进度
消费组消费进度与报警
ConsumerGroup 是一个消费者组,包含多个 consumer,每个 consumer 消费 Logstore 中的一部分 shard。
shard 的数据模型可以简单理解成一个队列,新写入的数据被加到队尾,队列中的每条数据都会对应一个数据写入时间,下图是 shard 的数据模型。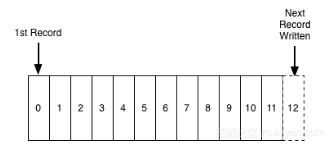
要理解报警首先要理解下面几个概念:
消费过程:消费者从队头开始顺序读取数据的过程。
消费进度:消费者当前读取的数据对应的写入时间。
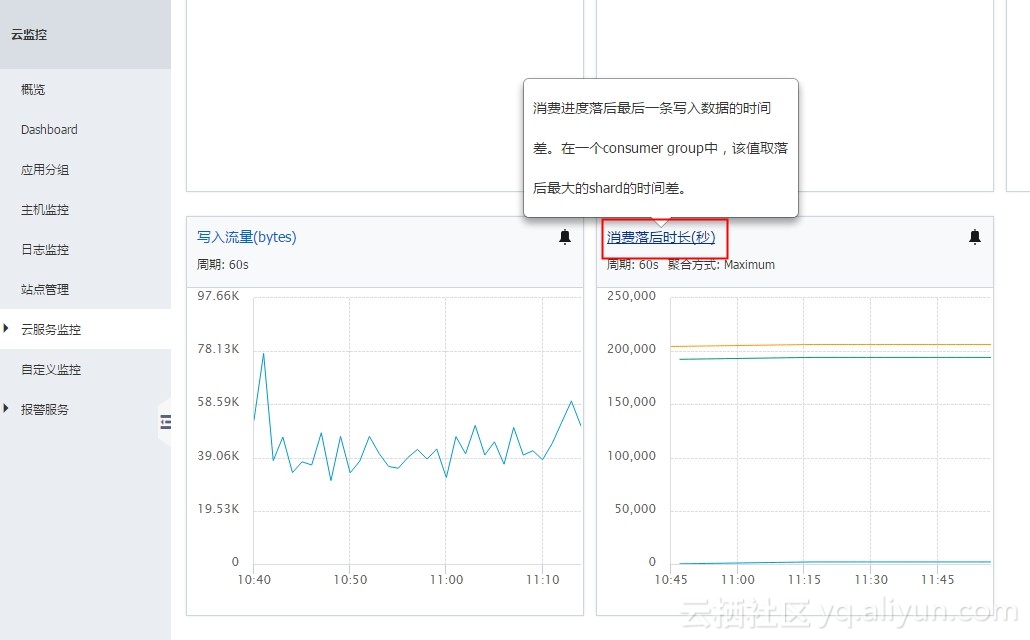
消费落后时长:当前消费进度和队列中最新的数据写入时间的差值,单位为秒。
ConsumerGroup 的消费落后时长取其包含的所有 shard 的消费落后时长的最大值,当超过用户预设阈值时,就认为消费落后太多,需要报警。
配置方法
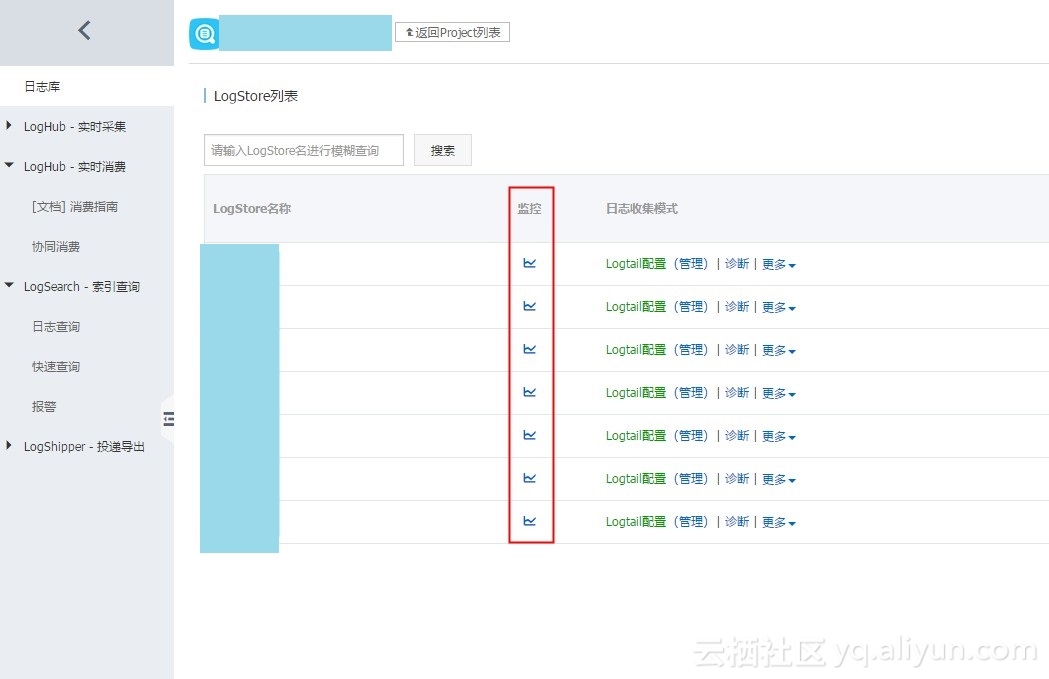
- 登录 日志服务管理控制台,单击需要监控的 Logstore 的监控图标。

- 找到消费落后时长图表,单击进入云监控控制台。
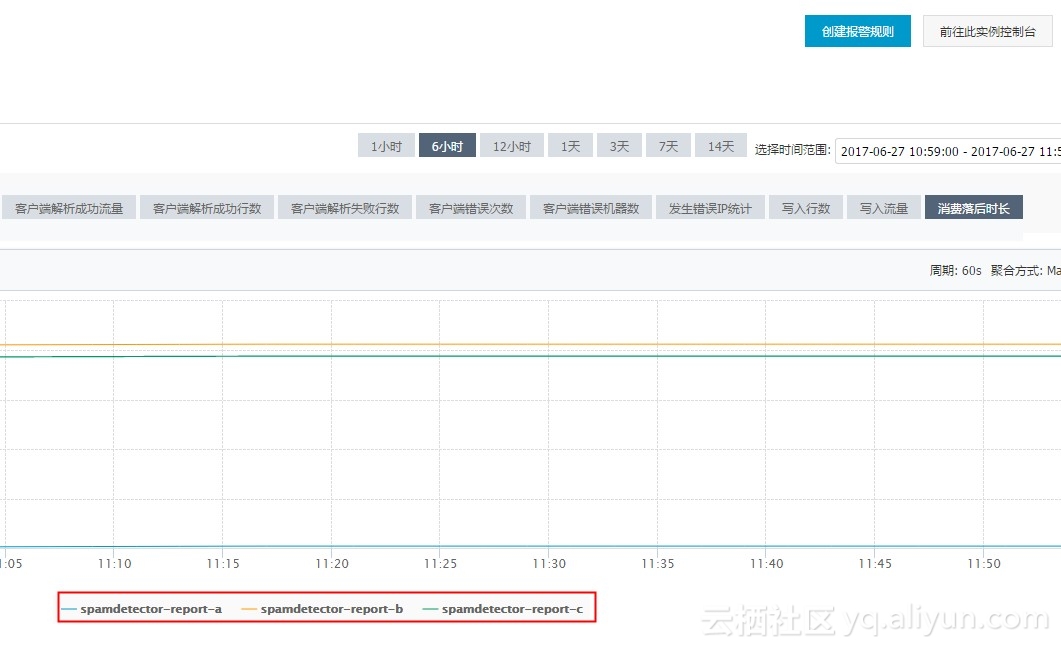
- 该图展示了 Logstore 下所有 ConsumerGroup 的消费落后时长,单位为秒。红框中图例便是所有的 ConsumerGroup,单击右上角 创建报警规则 进入规则创建页面。
- 创建针对 ConsumerGroup spamdetector-report-c 的报警规则,5min 内只要有一次大于等于 600 秒就报警。设置生效时间和报警通知联系人,保存规则。
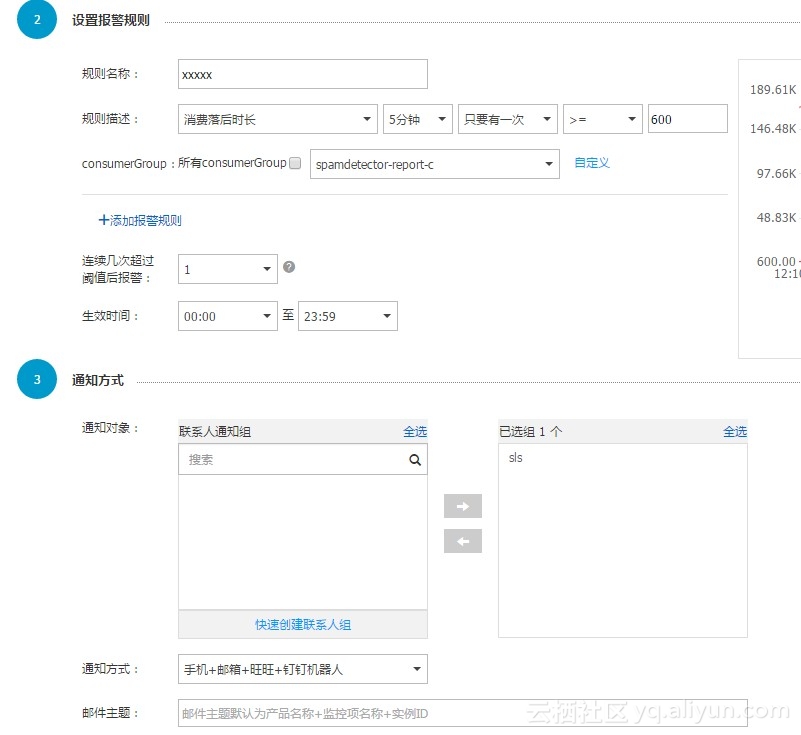
上面的操作完成后便成功创建了报警规则。有关报警规则配置的任何问题,可以直接提工单到云监控。
时间: 2025-01-19 16:44:09