redis支持migrate key的命令,支持从源redis节点迁移key到目标节点上,目标节点再执行restore命令,将数据加载进内存中。以800MB,数据类型为zset(skiplist) 的 key为例,测试环境为本地开发机上两台redis,忽略网络的影响。原生的redis 在restore时执行需要163s,优化后的redis执行需要27s。
1. 原生redis restore的性能瓶颈
通过扁鹊工具分析,可以看到cpu的运行情况如下: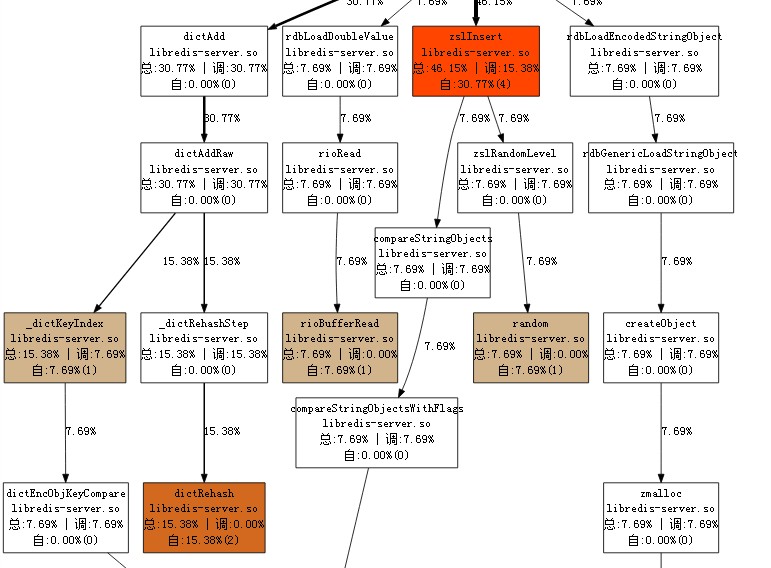
查看源码可知,migrate 遍历出来的zset 中的hashtable值和score,序列化之后打包给目标节点。
目标节点在反序列后重新构造了zset的结构,包括zslinsert, dictadd 等操作。当数据量越大时,重构的代价也就越大。
2. 优化方法
已知瓶颈在重构数据模型,所以优化的思路就是将源节点的数据模型也一并序列化打包给目标节点。目标节点解析后预构造出内存,再按解析后的member填鸭进去即可。
zset 可以说是redis中最为复杂的数据结构,以zset为例,阐述如何优化。
2.1 zset的数据结构
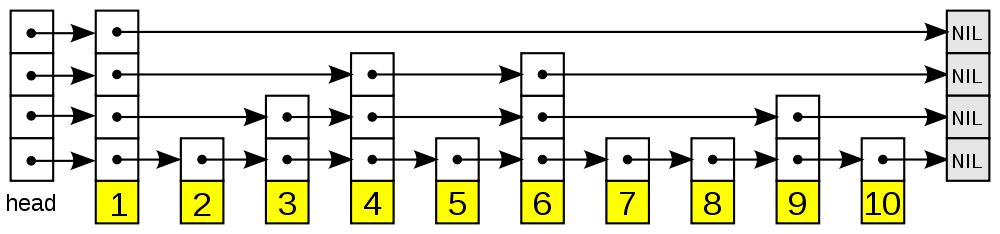
zset 由两个数据结构组成,一个是hashtable 结构的dict,存储的是每个member的值及对应的score,另一个是skiplist的zsl,按序排列每个member。如图所示:
2.2 序列化zset结构模型
redis中,zset的dict 和 zsl 中member 和score的内存是共享的,两种结构,一份内存。如果在序列化中描述一份数据两种索引成本反而更高。
2.2.1 序列化dict模型
再细看cpu的性能消耗,hashtable部分更多消耗在计算index, rehash(即预分配的hash table的size不满足时,需要使用一个更大size的hashtable,将旧的table挪到新的table中),compare key(在链表中遍历判断key是否已经存在)。
基于此,在序列化时带上最大的hashtable的size,restore时指定生成size大小的dict table,去掉rehash。
restore zsl 结构,反序列化出member,score,重新计算member的index,插入指定index的table中,因为遍历出来的zsl不会有出现key冲突的情况,省去compare key,直接将相同index的member接入到链表中。
2.2.2 序列化zsl模型
zsl 有多层结构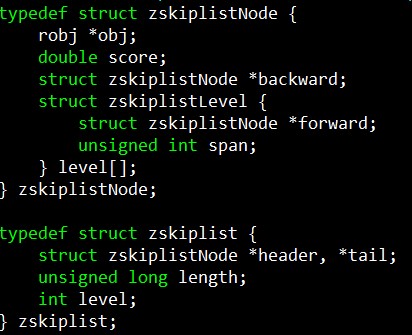
描述的难点在于每一层上的zskiplistNode总共的level层不知道,并且需要描述每一层的前后节点关系,同时需要考虑兼容性。
综合以上考虑,决定从整个zsl最高的level层次遍历,序列化的格式是:
level | header span | level_len | [ span ( | member | score ... ) ]
level : 第几层的数据
header span : header 节点在该层上的span值
level_len : 该层上总的节点数
span : 节点在该层上的span值
member | socre :因为在0层以上的level 有冗余的节点,通过span值相加可以判断是否是冗余节点,冗余节点则不序列化member | score, 非冗余节点带上member | score。反序列时的算法亦然。
结束语
如此zset的数据模型描述完成。对restore的性能更快,但是同时会消耗更多的带宽,多出来的带宽是描述节点的字段。800MB的数据,优化后比优化前多出20MB数据。
云数据库Redis版(ApsaraDB for Redis)是一种稳定可靠、性能卓越、可弹性伸缩的数据库服务。基于飞天分布式系统和全SSD盘高性能存储,支持主备版和集群版两套高可用架构。提供了全套的容灾切换、故障迁移、在线扩容、性能优化的数据库解决方案。欢迎各位购买使用:云数据库 Redis 版