2.4.1 HDFS Java API操作
Hadoop中关于文件操作类基本上是在org.apache.hadoop.fs包中,这些API能够支持的操作有:打开文件,读写文件,删除文件,创建文件、文件夹,判断是文件或文件夹,判断文件或文件夹是否存在等。
Hadoop类库中最终面向用户提供的接口类是FileSystem,这个类是个抽象类,只能通过类的get方法得到其实例。get方法有几个重载版本,如图2-28所示。
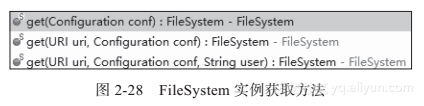
比较常用的是第一个,即灰色背景的方法。
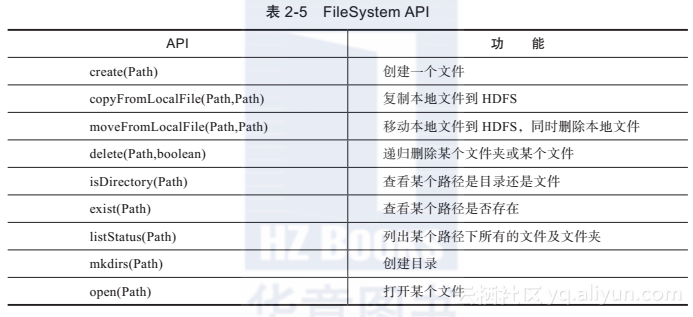
FileSystem针对HDFS相关操作的API如表2-5所示。
代码清单2-22,是FileSystem API的一个简单示例。该代码首先获取FileSystem的一个实例,然后调用该实例的listStatus方法,获取所有根目录下面的文件或文件夹(注意这里获取的不包含递归子目录);接着,调用create方法创建一个新文件,并写入“Hello World!”;最后,读取刚才创建的文件,并把创建的文件内容打印出来;关闭FileSystem实例。
代码清单2-22 FileSystem API示例
package demo;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class FileSystemAPIDemo {
public static void main(String[] args) throws IOException {
// 获取Hadoop默认配置
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://master:8020"); // 配置HDFS
// 获取HDFS FileSystem实例
FileSystem fs = FileSystem.get(conf);
// 列出根目录下所有文件及文件夹
Path root = new Path("hdfs://master:8020/");
FileStatus[] children = fs.listStatus(root);
for(FileStatus child :children){
System.out.println(child.getPath().getName());
}
// 创建文件并写入“HelloWorld!”
Path newFile = new Path("hdfs://master:8020/user/fansy/new.txt"); // 注意路径需要具有写权限
if(fs.exists(newFile)){ // 判断文件是否存在
fs.delete(newFile, false); // 如果存在,则删除文件
}
FSDataOutputStream out = fs.create(newFile); // 创建文件
out.writeUTF("Hello World!"); // 写入“Hello World!”
out.close(); // 关闭输出流
// 读取文件内容
FSDataInputStream in = fs.open(newFile); // 打开文件
String info = in.readUTF(); // 读取输入流
System.out.println(info); // 打印输出
// 关闭文件系统实例
fs.close();
}
}
执行完成后,在HDFS上可以看到创建的文件及内容,如图2-29所示。
时间: 2024-12-05 22:09:41