ART世界探险(18) InlineMethod
好,我们还是先复习一下上上节学到的图: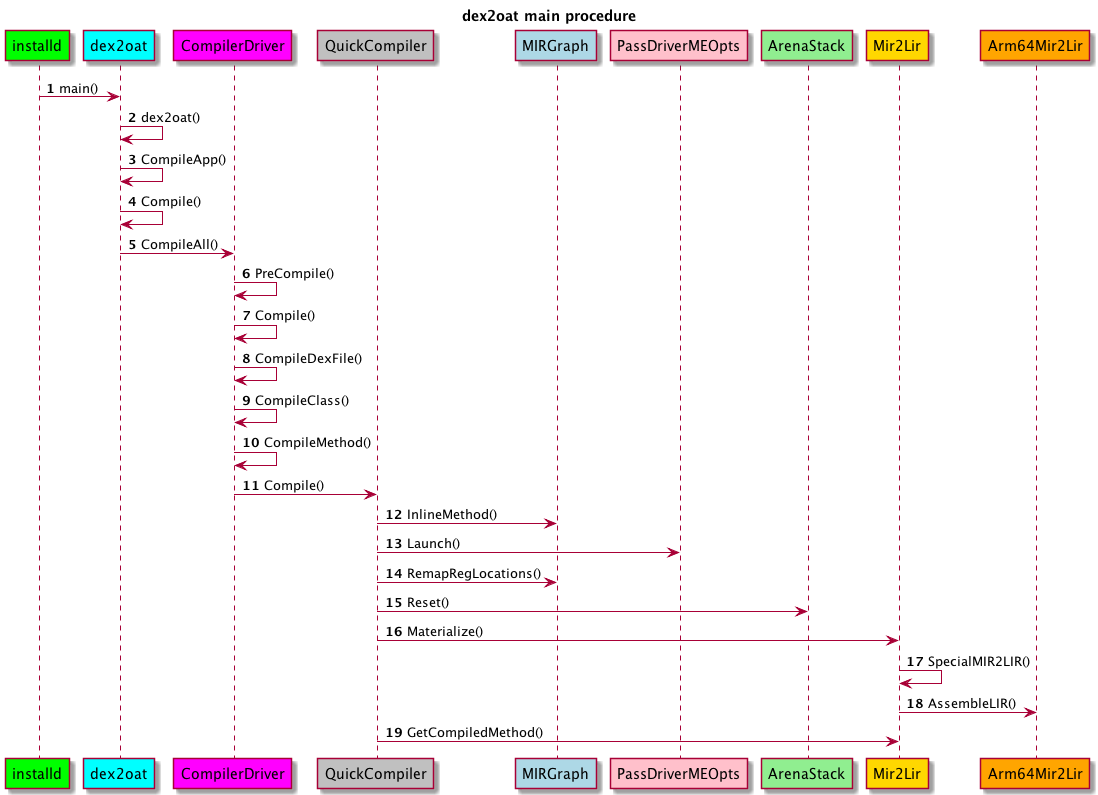
在开始InlineMethod之前,我们再继续补充一点BasicBlock的知识。
BasicBlock中针对MIR的相关操作
AppendMIR
AppendMIR的作用是将MIR增加到一个BasicBlock的结尾。
/ Insert an MIR instruction to the end of a basic block. /
void BasicBlock::AppendMIR(MIR* mir) {
// Insert it after the last MIR.
InsertMIRListAfter(last_mir_insn, mir, mir);
}
InsertMIRListAfter
一个标准的链表,实现MIR的列表队尾增加元素。
void BasicBlock::InsertMIRListAfter(MIR insert_after, MIR first_list_mir, MIR* last_list_mir) {
// If no MIR, we are done.
if (first_list_mir == nullptr || last_list_mir == nullptr) {
return;
}
// If insert_after is null, assume BB is empty.
if (insert_after == nullptr) {
first_mir_insn = first_list_mir;
last_mir_insn = last_list_mir;
last_list_mir->next = nullptr;
} else {
MIR* after_list = insert_after->next;
insert_after->next = first_list_mir;
last_list_mir->next = after_list;
if (after_list == nullptr) {
last_mir_insn = last_list_mir;
}
}
// Set this BB to be the basic block of the MIRs.
MIR* last = last_list_mir->next;
for (MIR* mir = first_list_mir; mir != last; mir = mir->next) {
mir->bb = id;
}
}
编译的第一个大步骤是MIRGraph::InlineMethod。
我们上一节准备了指令集和BasicBlock等储备知识,下面我们正式开始分析这第一个大步骤。
MIRGraph::InlineMethod
InlineMethod的作用是将一个Dex方法插入到MIRGraph中的当前插入点中。
void MIRGraph::InlineMethod(const DexFile::CodeItem* code_item, uint32_t access_flags,
InvokeType invoke_type ATTRIBUTE_UNUSED, uint16_t class_def_idx,
uint32_t method_idx, jobject class_loader, const DexFile& dex_file) {
current_code_item_ = code_item;
第一步先把传进来的code_item赋给当前MIRGraph对象的current_mode_item_项目。
它的定义为:
const DexFile::CodeItem* current_code_item_;
第二步将current_method_和current_offset_对压入到method_stack_栈中。
method_stack_是一个MIRLocation类型的ArenaVector。
ArenaVector<MIRLocation> method_stack_; // Include stack
MIRLocation是在MIRGraph类中定义的整数对。
typedef std::pair<int, int> MIRLocation; // Insert point, (m_unit_ index, offset)
总之,上面和下面这几句的目的是定位到插入下一处的位置
method_stack_.push_back(std::make_pair(current_method_, current_offset_));
current_method_ = m_units_.size();
current_offset_ = 0;
m_units_是DexCompilationUnit的容器,其结构如下: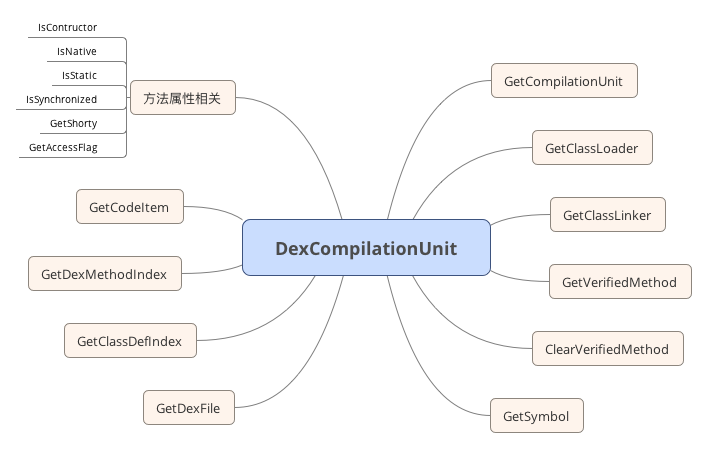
ArenaVector<DexCompilationUnit*> m_units_; // List of methods included in this graph
下面就开始往m_units_中push一个新建的DexCompilationUnit。
m_units_.push_back(new (arena_) DexCompilationUnit(
cu_, class_loader, Runtime::Current()->GetClassLinker(), dex_file,
current_code_item_, class_def_idx, method_idx, access_flags,
cu_->compiler_driver->GetVerifiedMethod(&dex_file, method_idx)));
然后计算代码的首地址和结束地址:
const uint16_t* code_ptr = current_code_item_->insns_;
const uint16_t* code_end =
current_code_item_->insns_ + current_code_item_->insns_size_in_code_units_;
下面为新的BasicBlock预留空间。
block_list_是一个BasicBlock的ArenaVector容器:
ArenaVector<BasicBlock*> block_list_;
先reserve block_list_的空间。然后再定义一个ScopedArenaVector。
block_list_.reserve(block_list_.size() + current_code_item_->insns_size_in_code_units_);
// FindBlock lookup cache.
ScopedArenaAllocator allocator(&cu_->arena_stack);
ScopedArenaVector<uint16_t> dex_pc_to_block_map(allocator.Adapter());
dex_pc_to_block_map.resize(current_code_item_->insns_size_in_code_units_ +
1 / Fall-through on last insn; dead or punt to interpreter. /);
...
下面开始处理第一个方法,为其创建BasicBlock对象:null_block对象,entry_block_对象和exit_block_对象。
CreateNewBB的逻辑在前面我们已经讲过了。
// If this is the first method, set up default entry and exit blocks.
if (current_method_ == 0) {
DCHECK(entry_block_ == nullptr);
DCHECK(exit_block_ == nullptr);
DCHECK_EQ(GetNumBlocks(), 0U);
// Use id 0 to represent a null block.
BasicBlock* null_block = CreateNewBB(kNullBlock);
DCHECK_EQ(null_block->id, NullBasicBlockId);
null_block->hidden = true;
entry_block_ = CreateNewBB(kEntryBlock);
exit_block_ = CreateNewBB(kExitBlock);
} else {
UNIMPLEMENTED(FATAL) << "Nested inlining not implemented.";
/*
* Will need to manage storage for ins & outs, push prevous state and update
* insert point.
*/
}
null块,入口块和出口块都是默认的。下面再创建代码块:
/ Current block to record parsed instructions /
BasicBlock* cur_block = CreateNewBB(kDalvikByteCode);
DCHECK_EQ(current_offset_, 0U);
cur_block->start_offset = current_offset_;
// TODO: for inlining support, insert at the insert point rather than entry block.
entry_block_->fall_through = cur_block->id;
cur_block->predecessors.push_back(entry_block_->id);
下面开始处理try块所管辖的区间。
/ Identify code range in try blocks and set up the empty catch blocks /
ProcessTryCatchBlocks(&dex_pc_to_block_map);
我们看一下ProcessTryCatchBlock的处理逻辑。
主要思路是:
- 遍历,寻找块中的每一个try语句
- 针对每一个try,计算catch需要处理的区间,然后加入到CatchHandler中。
/ Identify code range in try blocks and set up the empty catch blocks /
void MIRGraph::ProcessTryCatchBlocks(ScopedArenaVector<uint16_t>* dex_pc_to_block_map) {
int tries_size = current_code_item_->tries_size_;
DexOffset offset;
if (tries_size == 0) {
return;
}
for (int i = 0; i < tries_size; i++) {
const DexFile::TryItem* pTry =
DexFile::GetTryItems(*current_code_item_, i);
DexOffset start_offset = pTry->start_addr_;
DexOffset end_offset = start_offset + pTry->insn_count_;
for (offset = start_offset; offset < end_offset; offset++) {
try_block_addr_->SetBit(offset);
}
}
// Iterate over each of the handlers to enqueue the empty Catch blocks.
const uint8_t handlers_ptr = DexFile::GetCatchHandlerData(current_code_item_, 0);
uint32_t handlers_size = DecodeUnsignedLeb128(&handlers_ptr);
for (uint32_t idx = 0; idx < handlers_size; idx++) {
CatchHandlerIterator iterator(handlers_ptr);
for (; iterator.HasNext(); iterator.Next()) {
uint32_t address = iterator.GetHandlerAddress();
FindBlock(address, true /create/, / immed_pred_block_p / nullptr, dex_pc_to_block_map);
}
handlers_ptr = iterator.EndDataPointer();
}
}
下面开始处理每一条指令,将其转化成MIR。
uint64_t merged_df_flags = 0u;
/ Parse all instructions and put them into containing basic blocks /
while (code_ptr < code_end) {
MIR *insn = NewMIR();
insn->offset = current_offset_;
insn->m_unit_index = current_method_;
int width = ParseInsn(code_ptr, &insn->dalvikInsn);
Instruction::Code opcode = insn->dalvikInsn.opcode;
if (opcode_count_ != nullptr) {
opcode_count_[static_cast<int>(opcode)]++;
}
int flags = insn->dalvikInsn.FlagsOf();
int verify_flags = Instruction::VerifyFlagsOf(insn->dalvikInsn.opcode);
前面都是跟上节讲到的Dalvik指令集密切相关,相关信息可以参考上节。
下面开始处理一些特殊的标志。
uint64_t df_flags = GetDataFlowAttributes(insn);
merged_df_flags |= df_flags;
if (df_flags & DF_HAS_DEFS) {
def_count_ += (df_flags & DF_A_WIDE) ? 2 : 1;
}
if (df_flags & DF_LVN) {
cur_block->use_lvn = true; // Run local value numbering on this basic block.
}
下面先处理空指令。
空指令虽然只有一个字节,而且也没有操作要执行。但是处理起来也是有不少工程上的细节。
1. 首先要判断是否是因为对齐,而占用的字节数大于1.
2. 如果只占一个字节,则AppendMIR这条空指令
3. 否则可能存在不可达指令,对此要做一些针对性的处理
// Check for inline data block signatures.
if (opcode == Instruction::NOP) {
// A simple NOP will have a width of 1 at this point, embedded data NOP > 1.
if ((width == 1) && ((current_offset_ & 0x1) == 0x1) && ((code_end - code_ptr) > 1)) {
// Could be an aligning nop. If an embedded data NOP follows, treat pair as single unit.
uint16_t following_raw_instruction = code_ptr[1];
if ((following_raw_instruction == Instruction::kSparseSwitchSignature) ||
(following_raw_instruction == Instruction::kPackedSwitchSignature) ||
(following_raw_instruction == Instruction::kArrayDataSignature)) {
width += Instruction::At(code_ptr + 1)->SizeInCodeUnits();
}
}
if (width == 1) {
// It is a simple nop - treat normally.
cur_block->AppendMIR(insn);
} else {
DCHECK(cur_block->fall_through == NullBasicBlockId);
DCHECK(cur_block->taken == NullBasicBlockId);
// Unreachable instruction, mark for no continuation and end basic block.
flags &= ~Instruction::kContinue;
FindBlock(current_offset_ + width, / create / true,
/ immed_pred_block_p / nullptr, &dex_pc_to_block_map);
}
如果不是空指令的话,直接AppendMIR。
} else {
cur_block->AppendMIR(insn);
}
下面开始处理跳转相关的指令:
// Associate the starting dex_pc for this opcode with its containing basic block.
dex_pc_to_block_map[insn->offset] = cur_block->id;
code_ptr += width;
if (flags & Instruction::kBranch) {
cur_block = ProcessCanBranch(cur_block, insn, current_offset_,
width, flags, code_ptr, code_end, &dex_pc_to_block_map);
处理返回相关的操作:
} else if (flags & Instruction::kReturn) {
cur_block->terminated_by_return = true;
cur_block->fall_through = exit_block_->id;
exit_block_->predecessors.push_back(cur_block->id);
/*
* Terminate the current block if there are instructions
* afterwards.
*/
if (code_ptr < code_end) {
/*
* Create a fallthrough block for real instructions
* (incl. NOP).
*/
FindBlock(current_offset_ + width, / create / true,
/ immed_pred_block_p / nullptr, &dex_pc_to_block_map);
}
处理抛出异常指令:
} else if (flags & Instruction::kThrow) {
cur_block = ProcessCanThrow(cur_block, insn, current_offset_, width, flags, try_block_addr_,
code_ptr, code_end, &dex_pc_to_block_map);
处理分支指令:
} else if (flags & Instruction::kSwitch) {
cur_block = ProcessCanSwitch(cur_block, insn, current_offset_, width,
flags, &dex_pc_to_block_map);
}
...
寻找下一个BasicBlock. 找到之后,就把它们关联起来。
周而复始,我们就将它们画成了一张图。
current_offset_ += width;
BasicBlock next_block = FindBlock(current_offset_, / create */ false,
/ immed_pred_block_p / nullptr,
&dex_pc_to_block_map);
if (next_block) {
/*
* The next instruction could be the target of a previously parsed
* forward branch so a block is already created. If the current
* instruction is not an unconditional branch, connect them through
* the fall-through link.
*/
DCHECK(cur_block->fall_through == NullBasicBlockId ||
GetBasicBlock(cur_block->fall_through) == next_block ||
GetBasicBlock(cur_block->fall_through) == exit_block_);
if ((cur_block->fall_through == NullBasicBlockId) && (flags & Instruction::kContinue)) {
cur_block->fall_through = next_block->id;
next_block->predecessors.push_back(cur_block->id);
}
cur_block = next_block;
}
}
merged_df_flags_ = merged_df_flags;
...
最后再检查一下是不是有落空的代码跳出去了。
// Check if there's been a fall-through out of the method code.
BasicBlockId out_bb_id = dex_pc_to_block_map[current_code_item_->insns_size_in_code_units_];
if (UNLIKELY(out_bb_id != NullBasicBlockId)) {
// Eagerly calculate DFS order to determine if the block is dead.
DCHECK(!DfsOrdersUpToDate());
ComputeDFSOrders();
BasicBlock* out_bb = GetBasicBlock(out_bb_id);
DCHECK(out_bb != nullptr);
if (out_bb->block_type != kDead) {
LOG(WARNING) << "Live fall-through out of method in " << PrettyMethod(method_idx, dex_file);
SetPuntToInterpreter(true);
}
}
}
以上,便完成了一次MIRGraph的生成过程。后面我们会举例子,详细分析生成代码时这个流程是如何走的。
但是,我们还有一些细节还没有讲,我们先过一下它们。
ProcessCanBranch
ProcessCanBranch方法,会处理下面这些跟跳转相关的指令:
- 无条件跳转指令
- GOTO
- GOTO_16
- GOTO_32
- 条件跳转指令
- IF_EQ: 等于
- IF_NE: 不等于
- IF_LT: 小于
- IF_GE: 大于或等于
- IF_GT: 大于
- IF_LE: 小于或等于
另外,还有两参数的指令:IF_XXZ。
上节看指令格式的时候我们可以看到,IF_EQ是三参数的:。而对应的IF_EQZ是两个参数的:IF_EQZ vAA, +BBBB
首先是根据指令晒参数:
/ Process instructions with the kBranch flag /
BasicBlock MIRGraph::ProcessCanBranch(BasicBlock cur_block, MIR* insn, DexOffset cur_offset,
int width, int flags, const uint16_t* code_ptr,
const uint16_t* code_end,
ScopedArenaVector<uint16_t>* dex_pc_to_block_map) {
DexOffset target = cur_offset;
switch (insn->dalvikInsn.opcode) {
case Instruction::GOTO:
case Instruction::GOTO_16:
case Instruction::GOTO_32:
target += insn->dalvikInsn.vA;
break;
case Instruction::IF_EQ:
case Instruction::IF_NE:
case Instruction::IF_LT:
case Instruction::IF_GE:
case Instruction::IF_GT:
case Instruction::IF_LE:
cur_block->conditional_branch = true;
target += insn->dalvikInsn.vC;
break;
case Instruction::IF_EQZ:
case Instruction::IF_NEZ:
case Instruction::IF_LTZ:
case Instruction::IF_GEZ:
case Instruction::IF_GTZ:
case Instruction::IF_LEZ:
cur_block->conditional_branch = true;
target += insn->dalvikInsn.vB;
break;
default:
LOG(FATAL) << "Unexpected opcode(" << insn->dalvikInsn.opcode << ") with kBranch set";
}
后面根据参数情况查找要跳转的代码块:
CountBranch(target);
BasicBlock taken_block = FindBlock(target, / create */ true,
/ immed_pred_block_p / &cur_block,
dex_pc_to_block_map);
DCHECK(taken_block != nullptr);
cur_block->taken = taken_block->id;
taken_block->predecessors.push_back(cur_block->id);
下面处理continue退出块的情况:
/ Always terminate the current block for conditional branches /
if (flags & Instruction::kContinue) {
BasicBlock* fallthrough_block = FindBlock(cur_offset + width,
/ create /
true,
/ immed_pred_block_p /
&cur_block,
dex_pc_to_block_map);
DCHECK(fallthrough_block != nullptr);
cur_block->fall_through = fallthrough_block->id;
fallthrough_block->predecessors.push_back(cur_block->id);
} else if (code_ptr < code_end) {
FindBlock(cur_offset + width, / create / true, / immed_pred_block_p / nullptr, dex_pc_to_block_map);
}
return cur_block;
}
ProcessCanSwitch
处理switch语句:
/ Process instructions with the kSwitch flag /
BasicBlock MIRGraph::ProcessCanSwitch(BasicBlock cur_block, MIR* insn, DexOffset cur_offset,
int width, int flags,
ScopedArenaVector<uint16_t>* dex_pc_to_block_map) {
UNUSED(flags);
const uint16_t* switch_data =
reinterpret_cast<const uint16_t*>(GetCurrentInsns() + cur_offset +
static_cast<int32_t>(insn->dalvikInsn.vB));
int size;
const int* keyTable;
const int* target_table;
int i;
int first_key;
switch的case以压缩的格式存储的话:
/*
* Packed switch data format:
* ushort ident = 0x0100 magic value
* ushort size number of entries in the table
* int first_key first (and lowest) switch case value
* int targets[size] branch targets, relative to switch opcode
*
Total size is (4+size2) 16-bit code units.
*/
if (insn->dalvikInsn.opcode == Instruction::PACKED_SWITCH) {
DCHECK_EQ(static_cast<int>(switch_data[0]),
static_cast<int>(Instruction::kPackedSwitchSignature));
size = switch_data[1];
first_key = switch_data[2] | (switch_data[3] << 16);
target_table = reinterpret_cast<const int*>(&switch_data[4]);
keyTable = nullptr; // Make the compiler happy.
以非压缩的稀疏方式存储的情况:
/*
* Sparse switch data format:
* ushort ident = 0x0200 magic value
* ushort size number of entries in the table; > 0
* int keys[size] keys, sorted low-to-high; 32-bit aligned
* int targets[size] branch targets, relative to switch opcode
*
Total size is (2+size4) 16-bit code units.
*/
} else {
DCHECK_EQ(static_cast<int>(switch_data[0]),
static_cast<int>(Instruction::kSparseSwitchSignature));
size = switch_data[1];
keyTable = reinterpret_cast<const int*>(&switch_data[2]);
target_table = reinterpret_cast<const int>(&switch_data[2 + size2]);
first_key = 0; // To make the compiler happy.
}
...
下面去查找对应的代码块,并把它们组织起来。
cur_block->successor_block_list_type =
(insn->dalvikInsn.opcode == Instruction::PACKED_SWITCH) ? kPackedSwitch : kSparseSwitch;
cur_block->successor_blocks.reserve(size);
for (i = 0; i < size; i++) {
BasicBlock case_block = FindBlock(cur_offset + target_table[i], / create */ true,
/ immed_pred_block_p / &cur_block,
dex_pc_to_block_map);
DCHECK(case_block != nullptr);
SuccessorBlockInfo* successor_block_info =
static_cast<SuccessorBlockInfo*>(arena_->Alloc(sizeof(SuccessorBlockInfo),
kArenaAllocSuccessor));
successor_block_info->block = case_block->id;
successor_block_info->key =
(insn->dalvikInsn.opcode == Instruction::PACKED_SWITCH) ?
first_key + i : keyTable[i];
cur_block->successor_blocks.push_back(successor_block_info);
case_block->predecessors.push_back(cur_block->id);
}
下面处理落空的情况,就是default的情况了。
/ Fall-through case /
BasicBlock fallthrough_block = FindBlock(cur_offset + width, / create */ true,
/ immed_pred_block_p / nullptr,
dex_pc_to_block_map);
DCHECK(fallthrough_block != nullptr);
cur_block->fall_through = fallthrough_block->id;
fallthrough_block->predecessors.push_back(cur_block->id);
return cur_block;
}
ProcessCanThrow - 处理异常的情况
/ Process instructions with the kThrow flag /
BasicBlock MIRGraph::ProcessCanThrow(BasicBlock cur_block, MIR* insn, DexOffset cur_offset,
int width, int flags, ArenaBitVector* try_block_addr,
const uint16_t code_ptr, const uint16_t code_end,
ScopedArenaVector<uint16_t>* dex_pc_to_block_map) {
UNUSED(flags);
bool in_try_block = try_block_addr->IsBitSet(cur_offset);
bool is_throw = (insn->dalvikInsn.opcode == Instruction::THROW);
首先是处理try块:
/ In try block /
if (in_try_block) {
CatchHandlerIterator iterator(*current_code_item_, cur_offset);
if (cur_block->successor_block_list_type != kNotUsed) {
LOG(INFO) << PrettyMethod(cu_->method_idx, *cu_->dex_file);
LOG(FATAL) << "Successor block list already in use: "
<< static_cast<int>(cur_block->successor_block_list_type);
}
for (; iterator.HasNext(); iterator.Next()) {
BasicBlock catch_block = FindBlock(iterator.GetHandlerAddress(), false / create */,
nullptr / immed_pred_block_p /,
dex_pc_to_block_map);
if (insn->dalvikInsn.opcode == Instruction::MONITOR_EXIT &&
IsBadMonitorExitCatch(insn->offset, catch_block->start_offset)) {
// Don't allow monitor-exit to catch its own exception, http://b/15745363 .
continue;
}
if (cur_block->successor_block_list_type == kNotUsed) {
cur_block->successor_block_list_type = kCatch;
}
catch_block->catch_entry = true;
if (kIsDebugBuild) {
catches_.insert(catch_block->start_offset);
}
SuccessorBlockInfo successor_block_info = reinterpret_cast<SuccessorBlockInfo>
(arena_->Alloc(sizeof(SuccessorBlockInfo), kArenaAllocSuccessor));
successor_block_info->block = catch_block->id;
successor_block_info->key = iterator.GetHandlerTypeIndex();
cur_block->successor_blocks.push_back(successor_block_info);
catch_block->predecessors.push_back(cur_block->id);
}
in_try_block = (cur_block->successor_block_list_type != kNotUsed);
}
bool build_all_edges =
(cu_->disable_opt & (1 << kSuppressExceptionEdges)) || is_throw || in_try_block;
if (!in_try_block && build_all_edges) {
BasicBlock* eh_block = CreateNewBB(kExceptionHandling);
cur_block->taken = eh_block->id;
eh_block->start_offset = cur_offset;
eh_block->predecessors.push_back(cur_block->id);
}
如果有异常要抛出,就需要构建一个catch块去处理:
if (is_throw) {
cur_block->explicit_throw = true;
if (code_ptr < code_end) {
// Force creation of new block following THROW via side-effect.
FindBlock(cur_offset + width, / create / true, / immed_pred_block_p / nullptr, dex_pc_to_block_map);
}
if (!in_try_block) {
// Don't split a THROW that can't rethrow - we're done.
return cur_block;
}
}
if (!build_all_edges) {
/*
* Even though there is an exception edge here, control cannot return to this
* method. Thus, for the purposes of dataflow analysis and optimization, we can
* ignore the edge. Doing this reduces compile time, and increases the scope
* of the basic-block level optimization pass.
*/
return cur_block;
}
下面是对catch的处理。注释里有详细的说明,我们后面再讨论细节。
这个阶段重要的是大家对于整个流程有个概念,可以不必过于关注细节。
/*
* Split the potentially-throwing instruction into two parts.
* The first half will be a pseudo-op that captures the exception
* edges and terminates the basic block. It always falls through.
* Then, create a new basic block that begins with the throwing instruction
* (minus exceptions). Note: this new basic block must NOT be entered into
* the block_map. If the potentially-throwing instruction is the target of a
* future branch, we need to find the check psuedo half. The new
* basic block containing the work portion of the instruction should
* only be entered via fallthrough from the block containing the
* pseudo exception edge MIR. Note also that this new block is
* not automatically terminated after the work portion, and may
* contain following instructions.
*
* Note also that the dex_pc_to_block_map entry for the potentially
* throwing instruction will refer to the original basic block.
*/
BasicBlock* new_block = CreateNewBB(kDalvikByteCode);
new_block->start_offset = insn->offset;
cur_block->fall_through = new_block->id;
new_block->predecessors.push_back(cur_block->id);
MIR* new_insn = NewMIR();
*new_insn = *insn;
insn->dalvikInsn.opcode = static_cast<Instruction::Code>(kMirOpCheck);
// Associate the two halves.
insn->meta.throw_insn = new_insn;
new_block->AppendMIR(new_insn);
return new_block;
}