前段时间忙于破解移动和电信的 apk ,挺久没有更新博客了,最近在写个工具,主要功能是通过配置对 dex 文件中的类型、函数、属性进行隐藏,达到防止被静态分析的效果。所以在写工具前必须对 dex 的文件格式有个清晰的认识,相对于 elf 文件格式 dex 文件格式会简单一些。
原文链接: DEX文件格式分析
0x00 前言
分析 dex 文件格式最好的方式是找个介绍文档,自己再写一个简单的 demo 然后用 010Editor 对照着分析。文档可以参考官方文档http://source.android.com/devices/tech/dalvik/dex-format.html,英文差的也可以找个中文的,比如说我。。。。。。
010Editor 这个工具比较好用,之前分析 elf 文件也是用的它。其实只要装了模板,可以分析很多文件。虽然是收费软件,有30天免费试用。但是如果你用的是 mac 试用期到了, 删一下这个文件 ~/.config/SweetScape/010 Editor.ini。
0x01 文件布局
dex 文件可以分为3个模块,头文件(header)、索引区(xxxx_ids)、数据区(data)。头文件概况的描述了整个 dex 文件的分布,包括每一个索引区的大小跟偏移。索引区的ids 是 identifiers 的缩写,表示每个数据的标识,索引区主要是指向数据区的偏移。

010Editor 中除了数据区(data)没有显示出来,其他区段都有显示,另外 link_data 在模板中被定为 map_list

0x02 header
header 描述了 dex 文件信息,和其他各个区的索引。010Editor(写010Editor 有点麻烦下面直接写010)中用结构体 struct header_item 来描述 header。
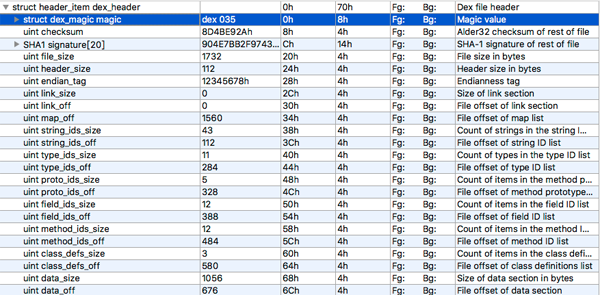
其中用到了两种数据类型char、uint。这里的 char 是 C/C++ 中的char 占 8-bit, java 中的 char 是占 16-bit 有点区别,但是我们可以他来表示 short/ushort 这个以后介绍最近写的工具会介绍。官方文档是用 ubyte来定义的,那还是按官方的来吧。结构体描述:
- ubyte 8-bit unsinged int
- uint 32-bit unsigned int, little-endian
- struct header_item
- {
- ubyte[8] magic;
- unit checksum;
- ubyte[20] signature;
- uint file_size;
- uint header_size;
- unit endian_tag;
- uint link_size;
- uint link_off;
- uint map_off;
- uint string_ids_size;
- uint string_ids_off;
- uint type_ids_size;
- uint type_ids_off;
- uint proto_ids_size;
- uint proto_ids_off;
- uint method_ids_size;
- uint method_ids_off;
- uint class_defs_size;
- uint class_defs_off;
- uint data_size;
- uint data_off;
- }
除了 magic、checksum、signature、file_size、endian_tag、map_off 其他元素都是成对出现的。_off 表示元素的偏移量,_size 表示元素的个数。其余的6个描述主要是 dex 文件的信息。
- magic: 这个是固定值,用于识别 dex 文件。转化为字符串为:
- {0x64, 0x65, 0x78, 0x0A, 0x30, 0x33, 0x35, 0x00} = "dex\n035\0"
中间是一个换行,后面035是版本号。
- checksum: 文件校验码,使用 alder32 算法校验文件除去 maigc、checksum 外余下的所有文件区域,用于检 查文件错误。
- signature: 使用 SHA-1 算法 hash 除去 magic、checksum 和 signature 外余下的所有文件区域, 用于唯一识别本文件 。
- file_size: dex 文件大小
- header_size: header 区域的大小,目前是固定为 0x70
- endian_tag: 大小端标签,dex 文件格式为小端,固定值为 0x12345678 常量
- map_off: map_item 的偏移地址,该 item 属于 data 区里的内容,值要大于等于 data_off 的大小,处于 dex 文件的末端。
0x03 string_ids
string_ids 区段描述了 dex 文件中所有的字符串。格式很简单只有一个偏移量,偏移量指向了 string_data 区段的一个字符串:

上述描述里提到了 LEB128 ( little endian base 128 ) 格式,是基于 1 个 byte 的一种不定长度的编码方式。若第一个 byte 的最高位为1,则表示还需要下一个 byte 来描述,直至最后一个 byte 的最高位为 0。每个 byte 的其余 bit 用来表示数据,如下表所示。实际中 LEB128 最大只能达到 32-bit 可以阅读 dalvik 中的Leb128.h源码看出来。

数据结构为:
- ubyte 8-bit unsinged int
- uint 32-bit unsigned int, little-endian
- uleb128 unsigned LEB128, valriable length
- struct string_ids_item
- {
- uint string_data_off;
- }
- struct string_data_item
- {
- uleb128 utf16_size;
- ubyte data;
- }
其中 data 保存的就是字符串的值。string_ids 是比较关键的,后续的区段很多都是直接指向 string_ids 的 index。在写工具进行比较的时候也需要提取到 string_id
0x04 type_ids
type_ids 区索引了 dex 文件里的所有数据类型,包括 class 类型,数组类型(array types)和基本类型(primitive types)。区段里的元素格式为 type_ids_item,结构描述如下 :
- uint 32-bit unsigned int, little-endian
- struct type_ids_item
- {
- uint descriptor_idx; //-->string_ids
- }
type_ids_item 里面 descriptor_idx 的值的意思,是 string_ids 里的 index 序号,是用来描述此 type 的字符串。
0x05 proto_ids
proto 的意思是 method prototype 代表 java 语言里的一个 method 的原型 。proto_ids 里的元素为 proto_id_item,结构如下:
- uint 32-bit unsigned int, little-endian
- struct proto_id_item
- {
- uint shorty_idx; //-->string_ids
- uint return_type_idx; //-->type_ids
- uint parameters_off;
- }
- shorty_idx: 跟 type_ids 一样,它的值是一个 string_ids 的 index 号 ,最终是一个简短的字符串描述,用来说明该 method 原型。
- return_type_idx: 它的值是一个 type_ids 的 index 号 ,表示该 method 原型的返回值类型。
- parameters_off: 指向 method 原型的参数列表 type_list,若 method 没有参数,值为0。参数列表的格式是 type_list,下面会有描述。
0x06 field_ids
filed_ids 区里面有 dex 文件引用的所有的 field。区段的元素格式是 field_id_item,结构如下:
- ushort 16-bit unsigned int, little-endian
- uint 32-bit unsigned int, little-endian
- struct filed_id_item
- {
- ushort class_idx; //-->type_ids
- ushort type_idx; //-->type_ids
- uint name_idx; //-->string_ids
- }
- class_idx: 表示 field 所属的 class 类型,class_idx 的值是 type_ids 的一个 index,并且必须指向一个 class 类型。
- type_idx: 表示本 field 的类型,它的值也是 type_ids 的一个 index 。
- name_idx: 表示本 field 的名称,它的值是 string_ids 的一个 index 。
0x07 method_ids
method_ids 是索引区的最后一个条目,描述了 dex 文件里的所有的 method。method_ids 的元素格式是 method_id_item,结构跟 fields_ids 很相似:
- ushort 16-bit unsigned int, little-endian
- uint 32-bit unsigned int, little-endian
- struct filed_id_item
- {
- ushort class_idx; //-->type_ids
- ushort proto_idx; //-->proto_ids
- uint name_idx; //-->string_ids
- }
- class_idx: 表示 method 所属的 class 类型,class_idx 的值是 type_ids 的一个 index,并且必须指向一个 class 类型。<font color=red>ushort类型也是为什么我们说一个 dex 只能有 65535 个方法的原因,多了必须分包</font>。
- proto_idx: 表示 method 的类型,它的值也是 type_ids 的一个 index。
- name_idx: 表示 method 的名称,它的值是 string_ids 的一个 index。
0x08 class_defs
class_def 区段主要是对 class 的定义,它的结构很复杂,看的我有点晕,一层套一层。先看一张 010 的结构图:
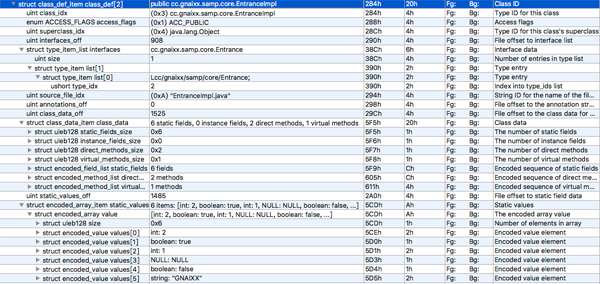
看着都晕,别说解析的时候了。
class_def_item
class_def_item 结构描述如下:
- uint 32-bit unsigned int, little-endian
- struct class_def_item
- {
- uint class_idx; //-->type_ids
- uint access_flags;
- uint superclass_idx; //-->type_ids
- uint interface_off; //-->type_list
- uint source_file_idx; //-->string_ids
- uint annotations_off; //-->annotation_directory_item
- uint class_data_off; //-->class_data_item
- uint static_value_off; //-->encoded_array_item
- }
- class_idx: 描述具体的 class 类型,值是 type_ids 的一个 index 。值必须是一个 class 类型,不能是数组类型或者基本类型。
- access_flags: 描述 class 的访问类型,诸如 public , final , static 等。在 dex-format.html 里 "access_flags Definitions" 有具体的描述 。
- superclass_idx: 描述 supperclass 的类型,值的形式跟 class_idx 一样 。
- interfaces_off: 值为偏移地址,指向 class 的 interfaces,被指向的数据结构为 type_list 。class 若没有 interfaces 值为 0。
- source_file_idx: 表示源代码文件的信息,值是 string_ids 的一个 index。若此项信息缺失,此项值赋值为 NO_INDEX=0xffff ffff。
- annotions_off: 值是一个偏移地址,指向的内容是该 class 的注释,位置在 data 区,格式为 annotations_direcotry_item。若没有此项内容,值为 0 。
- class_data_off: 值是一个偏移地址,指向的内容是该 class 的使用到的数据,位置在 data 区,格式为 class_data_item。若没有此项内容值为 0。该结构里有很多内容,详细描述该 class 的 field、method, method 里的执行代码等信息,后面会介绍class_data_item。
- static_value_off: 值是一个偏移地址 ,指向 data 区里的一个列表 (list),格式为 encoded_array_item。若没有此项内容值为 0。
type_list
type_list 在 data 区段,class_def_item->interface_off 就是指的这里的数据。数据结构如下:
- uint 32-bit unsigned int, little-endian
- struct type_list
- {
- uint size;
- type_item list [size]
- }
- struct type_item
- {
- ushort type_idx //-->type_ids
- }
- size: 表示类型个数
- type_idx: 对应一个 type_ids 的 index
annotations_directory_item
class_def_item->annotations_off 指向的数据区段,定义了 annotation 相关的数据描述,数据结构如下:
- uint 32-bit unsigned int, little-endian
- struct annotation_directory_item
- {
- uint class_annotations_off; //-->annotation_set_item
- uint fields_size;
- uint annotated_methods_size;
- uint annotated_parameters_size;
- field_annotation field_annotations[fields_size];
- method_annotation method_annotations[annotated_methods_size];
- parameter_annotation parameter_annotations[annotated_parameters_size];
- }
- struct field_annotation
- {
- uint field_idx;
- uint annotations_off; //-->annotation_set_item
- }
- struct method_annotation
- {
- uint method_idx;
- uint annotations_off; //-->annotation_set_item
- }
- struct parameter_annotation
- {
- uint method_idx;
- uint annotations_off; //-->annotation_set_ref_list
- }
- class_annotations_off: 这个偏移指向了 annotation_set_item 具体的可以看 dex-format.html 上的介绍。
- fields_size: 表示属性的个数
- annotated_methods_size: 表示方法的个数
- annotated_parameters_size: 表示参数的个数
class_data_item
class_data_off 指向 data 区里的 class_data_item 结构,class_data_item 里存放着本 class 使用到的各种数据,下面是 class_data_item 的结构 :
- uleb128 unsigned little-endian base 128
- struct class_data_item
- {
- uleb128 static_fields_size;
- uleb128 instance_fields_size;
- uleb128 direct_methods_size;
- uleb128 virtual_methods_size;
- encoded_field static_fields[static_fields_size];
- encoded_field instance_fields[instance_fields_size];
- encoded_method direct_methods[direct_methods_size];
- encoded_method virtual_methods[virtual_methods_size];
- }
- struct encoded_field
- {
- uleb128 filed_idx_diff;
- uleb128 access_flags;
- }
- struct encoded_method
- {
- uleb128 method_idx_diff;
- uleb128 access_flags;
- uleb128 code_off;
- }
class_data_item
- static_fields_size: 静态成员变量的个数
- instance_fields_size: 实例成员变量个数
- direct_methods_size: 直接函数个数
- virtual_methods_size: 虚函数个数
下面几个就是对于的描述
encoded_field
- method_idx_diff: 前缀 methd_idx 表示它的值是 method_ids 的一个 index ,后缀 _diff 表示它是于另 外一个 method_idx 的一个差值 ,就是相对于 encodeed_method [] 数组里上一个元素的 method_idx 的差值 。 其实 encoded_filed - > field_idx_diff 表示的也是相同的意思 ,只是编译出来的 Hello.dex 文件里没有使用到 class filed 所以没有仔细讲 ,详细的参考 dex_format.html 的官网文档。
- access_flags: 访问权限,比如 public、private、static、final 等。
- code_off: 一个指向 data 区的偏移地址,目标是本 method 的代码实现。被指向的结构是code_item,有近 10 项元素。
code_item
code_item 结构里描述着某个 method 的具体实现,它的结构描述如下:
- struct code_item
- {
- ushort registers_size;
- ushort ins_size;
- ushort outs_size;
- ushort tries_size;
- uint debug_info_off;
- uint insns_size;
- ushort insns [insns_size];
- ushort paddding; // optional
- try_item tries [tyies_size]; // optional
- encoded_catch_handler_list handlers; // optional
- }
末尾的 3 项标志为 optional , 表示可能有 ,也可能没有 ,根据具体的代码来。
- registers_size: 本段代码使用到的寄存器数目。
- ins_size: method 传入参数的数目 。
- outs_size: 本段代码调用其它 method 时需要的参数个数 。
- tries_size: try_item 结构的个数 。
- debug_off: 偏移地址,指向本段代码的 debug 信息存放位置,是一个 debug_info_item 结构。
- insns_size: 指令列表的大小,以 16-bit 为单位。 insns 是 instructions 的缩写 。
- padding: 值为 0,用于对齐字节 。
- tries 和 handlers: 用于处理 java 中的 exception,常见的语法有 try catch。
encoded_array_item
class_def_item->static_value_off 偏移指向该区段数据。
- uleb128 unsigned LEB128, valriable length
- struct encoded_array_item
- {
- encoded_array value;
- }
- struct encoded_array
- {
- uleb128 size;
- encoded_value values[size];
- }
- size : 表示encoded_value 个数
- encoded_value: 这个我也没分析出来怎么搞得
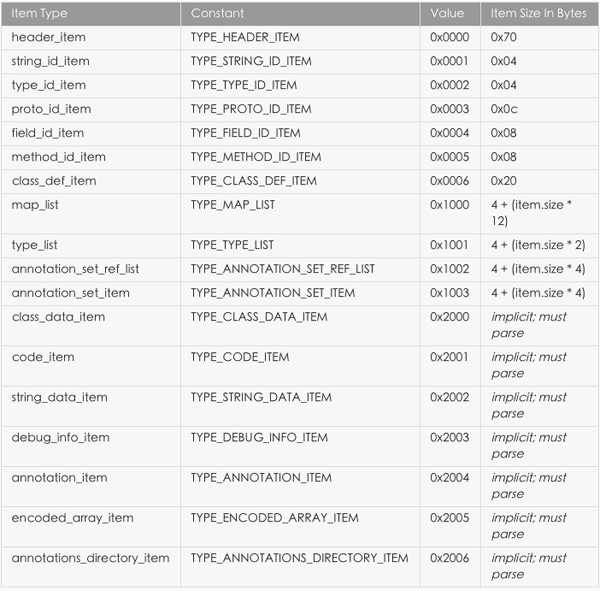
0x09 map_list
map_list 中大部分 item 跟 header 中的相应描述相同,都是介绍了各个区的偏移和大小,但是 map_list 中描述的更加全面,包括了 HEADER_ITEM 、TYPE_LIST、STRING_DATA_ITEM、DEBUG_INFO_ITEM 等信息。
010 中map_list 表示为:
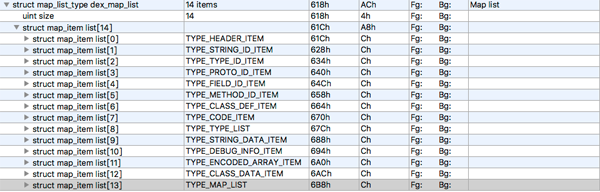
数据结构为:
- ushort 16-bit unsigned int, little-endian
- uint 32-bit unsigned int, little-endian
- struct map_list
- {
- uint size;
- map_item list [size];
- }
- struct map_item
- {
- ushort type;
- ushort unuse;
- uint size;
- uint offset;
- }
map_list 里先用一个 uint 描述后面有 size 个 map_item,后续就是对应的 size 个 map_item 描述。 map_item 结构有 4 个元素: type 表示该 map_item 的类型,Dalvik Executable Format 里 Type Code 的定义; size 表示再细分此 item,该类型的个数;offset 是第一个元素的针对文件初始位置的偏移量; unuse 是用对齐字节的,无实际用处。
作者:凸一_一凸
来源:51CTO