相信很多刚开始学习火车头的菜鸟们,也和烂泥一样使用的是火车头免费版,然后为我们的zencart网站进行一些产品数据的采集。但是在写采集规则的时候,会经常碰到的一个问题就是如何采集一个产品的多张图片。
采集一张图片的规则,相信大家都会写了。那么多张图片呢?如何写呢?其实,这个和我们写采集一张图的是一样的,只是在一些细节上面设置正确就ok了。下面我就自己采集的一个站点给各位做一下讲解。
我们知道要采集一个网站的图片,那么我们肯定是在火车头使用img标签来进行的。
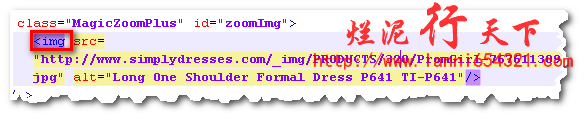
要采集多张图片,我们肯定要找出来这些图片在源码中的代码。我下面举例来进行讲解:

在上图中是标记出来的1和2是两张不同的图片,但是我们仔细的观察可以发现img标签中,如果把图片的源地址和alt去掉的话,那么其他的都是一样的。而火车头有一个标签循环使用的功能,这就为我们采集多张图片提供了一个方便。我现在把源码粘贴出来:
<img src="http://www.simplydresses.com/_img/PRODUCTS/320/PromGirl-767611310.jpg" width="68" border="0" alt="Long One Shoulder Formal Dress P641 TI-P641" />
然后在火车头中进行采集规则的编写:
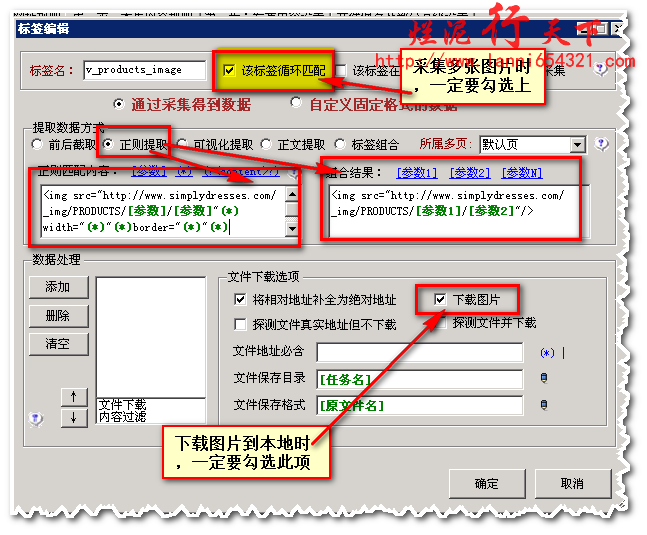
在数据提取方式中,我们选择了“正则提取”,而“正则匹配内容”中填写如下:
<img src="http://www.simplydresses.com/_img/PRODUCTS/[参数]/[参数]"(*)width="(*)"(*)border="(*)"(*)alt="(*)"(*)/>
组合结果中填写如下:
<img src="http://www.simplydresses.com/_img/PRODUCTS/[参数1]/[参数2]"/>
其中正则匹配内容第一个“参数”对应的是组合结果中的“参数1”,正则匹配内容第二个“参数”对应的是组合结果中的“参数2”,而其中的“*”是任意匹配的意思。

上图是设置好后,采集测试的结果

这个是导出的结果。
Ok,以上我们可以看到要采集多张图片,只要我们设置好了采集标签,然后此标签可以循环使用,就可以达到我们要的结果了……