
卢文星
目前就职云和恩墨,南区交付工程师,有超过8年超大型数据库管理经验,擅长Oracle数据库性能优化与升级迁移。
故障现象
某省税务核心业务系统在7月13日11-12点出现业务处理非常缓慢,偶尔出现卡住不动。某业务功能处理时间是平时的10倍以上。
已知情况:
1、近两周开始,在白天业务高峰期业务系统会出现处理缓慢
2、数据库层面出现大量latch:cache buffers chains等待会话
3、每次问题大概持续了30分钟后,latch:cache buffers chains等待消失,业务恢复正常
4、缓慢期间系统CPU使用率达到80%
故障分析
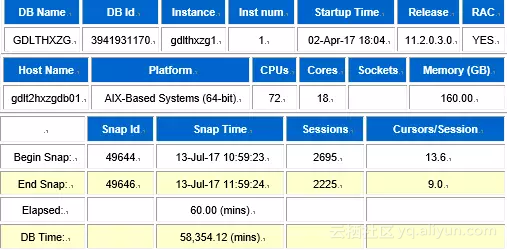
了解了以上信息后,我们首先获取了故障期间1节点的awr信息,一小时的dbtime高达58,354 min。我们知道dbtime是数据库实例会话花费时间的总和,那么从dbtime上看,期间数据库确实出现问题,会话发生了严重的等待。
Top等待事件中看到latch: cache buffers chains等待事件排列第1,占据了dbtime 82%,等待次数1千万以上,其平均等待时间达到238ms。其余等待事件占比很少。可以推断cache buffers chains事件跟本次故障有极强的相关性。因此我们接下来从该等待事件着手进行分析。

latch cache buffers chains 定义

我们可以看到,一个latch保护多个hash bucket,一个hash bucket对应一个hash chain list,而hash chain list挂载了一个或者多个buffer header(注意:buffer header与Data block一一对应)。
也就是说,如果我要访问某个block,我们首先获得这个latch。当有多个会话同时访问一个hash chain时,就会发生竞争。Latch cbc等待就这样出现了。

以下情况下会发生 cache buffers chains等待:
1、同一个cache buffers chains下不同block被频繁访问,称为hot chains
2、同一个cache buffers chains下同一个block被频繁访问,称为hot block
一个块的访问过程

一个块的访问过程,一般会有2次cbc latch的获取、释放。
官方对cbc latch的描述。





以上内容简单来说就是一个用户进程获取latch来扫描buffer ,系统根据块地址和类型将数据块分配在buffer链表中,每个buffer链表会有一个latch来保护。防止其扫描过程链表里的块发生变动。
分析问题原因
首先,通过dba_hist_active_session_history视图还原故障期间发生等待的会话信息,包括用户、正执行的SQL等。

dba_hist_active_sess_history视图查询十几分钟都没出结果。
查看该视图基表WRH$_ACTIVE_SESSION_HISTORY,其分区达到了8GB,视图里又关联了WRH$_EVENT_NAME、WRM$_SNAPSHOT表,所以查询长时间未完成。

直接查基表WRH$_ACTIVE_SESSION_HISTORY。基表没有event_name列,需要通过event_id来查,获取latch: cache buffers chains的event_id 。


五分钟执行完,查看结果后发现,cph4kgcn7frzs、c85hrnmygbhz2、1tnz5r62b84gg 这三个sql执行时发生了严重的Latch cbc等待。
查看这三个sql的SQLTEXT,发现它们的子查询SQL一样的,子查询访问的表为swjg_dm。



再观察SQL的执行计划(3个SQL执行计划基本一样,此处以c85hrnmygbhz2展示),子查询里访问表swjg_dm是通过索引UK_DM_GY_SWJG

回到awr报告,Segments by Logical Reads部分TOP1可以看到是DM_GY_SWJG表的索引UK_DM_GY_SWJG,该索引正好3个SQL执行计划中都用到的索引UK_DM_GY_SWJG。说明它被频繁访问。

awr报告SQL Statistics,1小时内,每个SQL执行次数都超过3百万。

在以下查询中p1为LATCH: CBC的address。显示有三个不同的SQL,说明3个SQL竞争同一个LATCH:CBC。

根据latch地址,到v$latch_children视图中可以查找该latch .因为实例没有重启过,cbc对应latch的address没有变动(如果数据库重启,则latch的addr会重新分配,就查不到了).
下面将P1转化为p1raw与视图addr关联

可以看到该latch地址是一个cache buffers chains latch
目前,我们只确认热块在索引UK_DM_GY_SWJG,但具体哪个块,我们还不确定。再根据latch的地址,通过x$hb联合dba_objects视图来查看。
再通过x$hb联合dba_objects视图来查看该CBC下中有哪些对象、块等

看到熟悉的对象索引UK_DM_GY_SWJG,它是9号文件的31109号块在这个CBC中。该cbc里只有1个UK_DM_GY_SWJG索引块。那么该块是不是热块,该索引的其他块在哪个cbc?
我们通过dump索引的结构来确认以下。


我们看到tree dump该索引有1个枝块和3个叶块,总共4个块,该所索引有1千多条记录。通过索引块地址dba转换后,看到9号文件31109号块是索引的叶子块。
再次通过x$bh确认,该索引的4个块分别在4个CBC中

分析结论
本次系统故障原因是,由于业务高峰期“cph4kgcn7frzs”、“c85hrnmygbhz2”、“1tnz5r62b84gg”这3个SQL执行频繁,并发访问索引UK_DM_GY_SWJG的9号文件31109号,对应的latch addr:07000100F6A6C8E8,引起严重latch: cache buffers chains竞争阻塞,从而导致业务处理缓慢。
优化措施
官方提供的Solution方法
1、Splitting the buffer pool into multiple pools
我们的问题情况是热块不是热链,不适合
2、Altering PCTFREE/PCTUSED to allow fewer rows per block, thus reducing contention on a certain block
对于索引记录分块,因为SQL访问该索引块中存在一定的热记录。所以对LATCH CBC问题的缓解效果不是很明显。
3、Reducing the frequency the application accesses the object in question.
客户确认,业务量上看该SQL不需要这么多次执行,与开发商确认存程序在BUG,但开发商回复bug短期内无法修复。
4、Tuning queries so that they won’t touch as many blocks. This will alleviate the problem with this latch if the query is heavily executed.
从前执行计划上看,对索引UK_DM_GY_SWJG访问,基本没有优化空间。
5、 Avoid doing too many concurrent DML and Queries against the same row/block. Too many concurrent DML and Queries against the same block can result in multiple versions of the block created in the same cache buffer chain. Longer chains means more time spent by the session traversing through the chain while holding on to the latch.
不存在dml,主要query SQL
我们问题的现状:

优化构思

优化措施
实现方法:
我们可以在表dm_gy_swjg 的swjg_dm列,再创建两个索引(复合索引),swjg_dm为前缀列,通过SQL PROFILE概要文件将c85hrnmygbhz2、1tnz5r62b84gg索引访问分别指向新建的两个复合索引,cph4kgcn7frzs不变动,则使用原UK_DM_GY_SWJG索引。
实施步骤:
dm_gy_swjg表创建两个新的复合索引,复合列为(swjg_dm , xybz)、(swjg_dm, yxbz)。
使用hint将c85hrnmygbhz2、1tnz5r62b84gg分别指定使用新建立两个复合索引,并获取outline信息。
通过SQL PROFILE概要固定c85hrnmygbhz2、1tnz5r62b84gg执行计划。
优化结果
在优化调整实施后一周,客户反馈,那3个sql在每小时3百万执行量的情况下,已经无发现有明显的latch: cache buffer chains等待,说明问题得以缓解。