原文:SSAS系列——【03】多维数据(多维数据集对象)
1、什么是Cube?
简单 Cube 对象由基本信息、维度和度量值组组成。 基本信息包括多维数据集的名称、多维数据集的默认度量值、数据源和存储模式等。维度是多维数据集中使用的实际维度组。所有维度都必须先在数据库的维度集合中定义,然后才能在多维数据集中引用。度量值组是多维数据集中的度量值集。度量值组是具有常见数据源视图和维度集的度量值的集合。度量值组是度量值的处理单元;可先对度量值组进行单独处理,然后再浏览。这个概念MSND解释的非常清楚,也不难理解,姑且Copy贴上来。
2、度量值和度量值组
度量值通常映射到事实数据表中的列。维度表中的属性列可以用于定义度量值,但是这些度量值通常在聚合行为方面具有半累加性或非累加性。
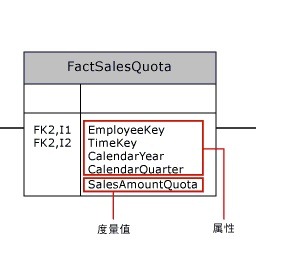
图 事实数据表中的度量值
简单 MeasureGroup 对象由基本信息、度量值、维度和分区组成。基本信息包括度量值组的名称、度量值的类型、存储模式和处理模式等。度量值是组成度量值组的实际度量值集。对于每个度量值,均有一个聚合函数定义、一个格式属性定义、一个数据项源定义等其他定义。维度是用于创建已处理度量值组的多维数据集维度的子集。分区是已处理度量值组的物理拆分的集合。在多维数据集中,度量值按照其基础事实数据表分组为多个度量值组。度量值组用于使维度和度量值相互关联。度量值组还可用于将非重复计数作为其聚合行为的度量值。将每个非重复计数度量值放入自己的度量值组后,可优化聚合处理。
3、粒度和聚合函数
在oo中,如果一个对象“车队”的实现只深入到“汽车”这个层次,而不是“发动机”“轮胎”这个层次,那么前者比后者粒度大。
只要能满足需要,粒度当然越大越好,简单实用。在数据仓库中的粒度的概念同上。
聚合函数用于库表数据统计,如: sum, count, avg。这儿不用多说,在这儿每个度量值的聚合行为都由与该度量值关联的聚合函数确定。
4、维度关系
指的是维度和事实数据表在一定的维度粒度下的属性。
常规维度关系
星型模型,没什么好说的,上图:
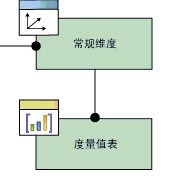
应用模型关系
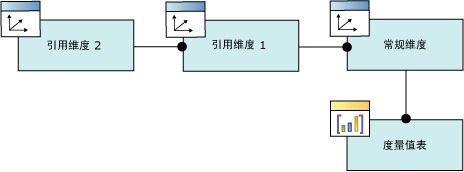
雪花型模型,上图:
多对多维度关系
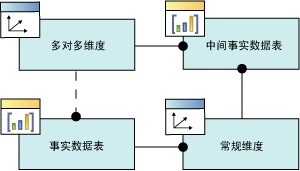
事实维度关系
事实维度(通常称为退化维度)是通过事实数据表而非维度表中的属性列构造的标准维度。 有用的维度数据有时存储在事实数据表中以减少重复。
5、计算
终于讲到一个我很感兴趣的话题了,这儿的应该也是操作数据仓库的核心之一。计算是一种多维表达式 (MDX) 表达式或脚本,用于在 SSAS中定义多维数据集中的计算成员、命名集或范围分配。我的理解是,使用计算后可以在原有的一些度量值的基础上生成新的度量值,在之后的浏览cube的时候新的度量值将和原来的一起使用。使用脚本命令可以让计算变得复杂灵活的满足业务需求。
6、关键绩效指标
在业务术语中,关键绩效指标 (KPI) 是一个用于测定业务绩效的可计量度量值。一个简单的KPI由基本信息、目标、获取的实际值、状态值、走向值以及在其中查看的KPI的文件夹组成。例如,一个单位的销售部门可以使用每月的毛利润作为 KPI,但同一单位的人力资源部门可以使用每季度流失的雇员作为 KPI。 这是一个比较重要的指标,目前暂时理解到这个程度。
7、操作 Action
操作的主要目的是为了提供给客户端应用程序并可由客户端应用程序使用的已存储 MDX 语句。他是在服务器端定义的客户端的执行命令。我的理解和数据库引擎中的存储过程相似。
8、分区Partition
分区是部分度量值组数据的容器。简单的分区对象由基本信息(名称、存储模式和处理模式)、切片定义、聚合设计等组成。SSAS使用分区来管理和存储量度值组的数据和聚合。分区对多维数据集的业务用户不可见。允许多维数据集的源数据和聚合数据分布在多个硬盘驱动器和多个服务器计算机中。分区和极大的提高查询性能、负载性能和多维数据集的易维护性。分区的结构必须与其度量值组的结构匹配。
分区存储
MOLAP、ROLAP、HOLAP
主动缓存(分区)
提供了多个主动缓存配置选项,您可以利用它们来最大化性能,最小化滞后时间以及安排处理。
远程分区
远程分区的数据存储在另一个 Microsoft SQL Server Analysis Services 实例上,而没有存储在包含分区定义(元数据)及其父多维数据集的实例上。
可写入的分区
都说使用了分区后可提高查询性能,到底是如何提高性能的呢?
9、透视
透视是多维数据集的只读视图。透视可控制多维数据集所包含对象的可见性。 可在透视中显示或隐藏以下对象:
维度、属性、层次结构、度量值组、度量值、关键绩效指标 (KPI)、计算(计算成员、命名集和脚本命令)、操作。