Oracle如何删除表中重复记录
1 引言
在对数据库进行操作过程中我们可能会遇到这种情况,表中的数据可能重复出现,使我们对数据库的操作过程中带来读诸多不便,那么怎么删除这些重复没有用的数据呢?
平时工作中可能会遇到当试图对库表中的某一列或几列创建唯一索引时,系统提示 ORA-01452 :不能创建唯一索引,发现重复记录。
2 处理过程
重复的数据可能有这样两种情况:第一种是表中只有某些字段一样,第二种是两行记录完全一样。删除重复记录后的结果也分为2种,第一种是重复的记录全部删除,第二种是重复的记录中只保留最新的一条记录,一般业务中第二种的情况较多。
2.1 删除重复记录的方法原理
(1)在Oracle中,每一条记录都有一个rowid,rowid在整个数据库中是唯一的,rowid确定了每条记录是在Oracle中的哪一个数据文件、块、行上。
(2)在重复的记录中,可能所有列的内容都相同,但rowid不会相同,所以只要确定出重复记录中那些具有最大rowid的就可以了,其余全部删除。
2.2 删除部分字段重复数据
2.2.1 重复记录全部删除
想要删除部分字段重复的数据,可以使用下面语句进行删除,下面的语句是删除表中字段1和字段2重复的数据:
DELETE FROM 表名 a
WHERE (字段1, 字段2)
IN (SELECT 字段1,字段2
FROM 表名
GROUP BY 字段1,
字段2
HAVING COUNT(1) > 1)
;
上面的语句非常简单,就是将查询到的数据删除掉。不过这种删除执行的效率非常低,对于大数据量来说,可能会将数据库吊死。所以建议先将查询到的重复的数据插入到一个临时表中,然后进行删除,这样,执行删除的时候就不用再进行一次查询了。如下:
CREATE TABLE 临时表 AS (select 字段1,字段2,count(*) from 表名 group by 字段1,字段2 having count(*) > 1);
上面这句话就是建立了临时表,并将查询到的数据插入其中。下面就可以进行这样的删除操作了:
delete from 表名 a where 字段1,字段2 in (select 字段1,字段2 from 临时表);
这种先建临时表再进行删除的操作要比直接用一条语句进行删除要高效得多。
例子:
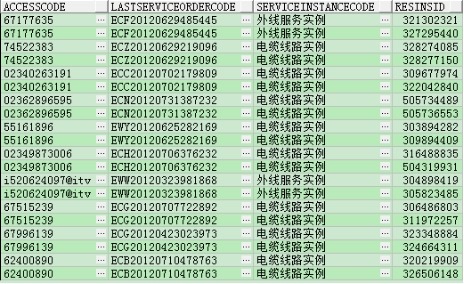
DELETE FROM tmp_lhr t
WHERE (t.accesscode, t.lastserviceordercode, t.serviceinstancecode) IN
(SELECT a.accesscode, a.lastserviceordercode, a.serviceinstancecode
FROM tmp_lhr a
GROUP BY a.accesscode,
a.lastserviceordercode,
a.serviceinstancecode
HAVING COUNT(1) > 1);

2.2.2 保留最新的一条记录
假如想保留重复数据中最新的一条记录啊!那怎么办呢?在oracle中,有个隐藏了自动rowid,里面给每条记录一个唯一的rowid,我们如果想保留最新的一条记录,我们就可以利用这个字段,保留重复数据中rowid最大的一条记录就可以了。
一、 如何查找重复记录?
SELECT *
FROM TABLE_NAME A
WHERE ROWID NOT IN (SELECT MAX(ROWID)
FROM TABLE_NAME D
WHERE A.COL1 = D.COL1
AND A.COL2 = D.COL2);
二、 如何删除重复记录? 1、 方法1
DELETE FROM TABLE_NAME
WHERE ROWID NOT IN (SELECT MAX(ROWID)
FROM TABLE_NAME D
group by d.col1,d.col2);
这种方法最简单!!!
2、 方法2
DELETE FROM TABLE_NAME A
WHERE ROWID NOT IN (SELECT MAX(ROWID)
FROM TABLE_NAME D
WHERE A.COL1 = D.COL1
AND A.COL2 = D.COL2);
3、 方法3 临时表
由此,我们要删除重复数据,只保留最新的一条数据,就可以这样写了:
create table 临时表 as select a.字段1,a.字段2,MAX(a.ROWID) dataid from 正式表 a GROUP BY a.字段1,a.字段2;
DELETE FROM 正式表 a
where a.rowid NOT IN (SELECT b.dataid
FROM 临时表 b
WHERE a.字段1 = b.字段1
and a.字段2 = b.字段2);
commit;
例子:
DELETE FROM tmp_lhr t
WHERE t.rowid not in (SELECT MAX(ROWID)
FROM tmp_lhr a
GROUP BY a.accesscode,
a.lastserviceordercode,
a.serviceinstancecode);
DELETE FROM tmp_lhr t
WHERE t.rowid !=
(SELECT MAX(ROWID)
FROM tmp_lhr a
WHERE a.accesscode = t.accesscode
AND a.lastserviceordercode = t.lastserviceordercode
AND a.serviceinstancecode = t.serviceinstancecode);
2.2.3 删除以某个字段为准的记录
----任意保留一条记录
DELETE FROM ods_entity_info_full_lhr_01 T
WHERE T.ROWID NOT IN (SELECT MAX(A.ROWID)
FROM ods_entity_info_full_lhr_01 A
GROUP BY entity_code,
entity_type);
---保留 entity_id 最大的一条记录
DELETE FROM ods_entity_info_full_lhr_01 a
WHERE a.rowid NOT IN
(SELECT t.rowid
FROM ods_entity_info_full_lhr_01 t
WHERE (t.entity_code, t.entity_type, t.entity_id) IN
(SELECT entity_code,
entity_type,
MAX(entity_id)
FROM ods_entity_info_full_lhr_01
GROUP BY entity_code,
entity_type));
2.3 删除完全重复记录
对于表中两行记录完全一样的情况,可以用下面三种方式获取到去掉重复数据后的记录:
1. select distinct * from 表名;
2. select * from 表名 group by 列名1,列名2,... having count(*)>1
3. select * from 表名 a where rowid<(select max(rowid) from 表名 b where a.列名1=b.列名2 and ...)
2.3.1 方法1
DELETE FROM tmp_lhr t
WHERE t.rowid not in (SELECT MAX(ROWID)
FROM tmp_lhr a
GROUP BY a.accesscode,
a.lastserviceordercode,
a.serviceinstancecode);
2.3.2 方法2
可以将查询的记录放到临时表中,然后再将原来的表记录删除,最后将临时表的数据导回原来的表中。如下:
CREATE TABLE 临时表 AS (select distinct * from 表名);
truncate table 正式表;
insert into 正式表 (select * from 临时表);
drop table 临时表;
2.3.3 方法3
DELETE FROM xr_maintainsite E
WHERE E.ROWID > (SELECT MIN(X.ROWID)
FROM xr_maintainsite X
WHERE X.Maintainid = E.Maintainid
AND x.siteid = e.siteid);--这里被更新表中所有字段都需要写全
2.4 采用row_number分析函数取出重复的记录然后删除序号大于1的记录
给出一个例子:
delete from aa where rowid in(select rid from(select rowid rid,row_number() over (partition by name order by id) as seq from aa) where seq>1);
3 测试案例
SYS@raclhr1> CREATE TABLE T_ROWS_LHR_20160809 AS SELECT * FROM SCOTT.EMP;
Table created.
SYS@raclhr1> INSERT INTO T_ROWS_LHR_20160809 SELECT * FROM T_ROWS_LHR_20160809;
14 rows created.
SYS@raclhr1> COMMIT;
Commit complete.
SYS@raclhr1> INSERT INTO T_ROWS_LHR_20160809 SELECT * FROM T_ROWS_LHR_20160809;
28 rows created.
SYS@raclhr1> COMMIT;
Commit complete.
SYS@raclhr1> SELECT COUNT(1) FROM T_ROWS_LHR_20160809;
COUNT(1)
----------
56
SYS@raclhr1> DELETE FROM T_ROWS_LHR_20160809
2 WHERE ROWID NOT IN (SELECT MAX(ROWID)
3 FROM T_ROWS_LHR_20160809 D
4 group by D.EMPNO,D.ENAME,D.JOB,D.MGR,D.DEPTNO);
42 rows deleted.
SYS@raclhr1> SELECT COUNT(1) FROM T_ROWS_LHR_20160809;
COUNT(1)
----------
14
SYS@raclhr1> COMMIT;
Commit complete.
4 经验总结
重复数据删除技术可以提供更大的备份容量,实现更长时间的数据保留,还能实现备份数据的持续验证,提高数据恢复服务水平,方便实现数据容灾等。Oracle数据库重复数据删除技术有如下优势:更大的备份容量、数据能得到持续验证、有更高的数据恢复服务水平、方便实现备份数据的容灾。
通过摸索,相信你能发现更多更高效删除Oracle重复数据的方法。
About Me
...............................................................................................................................● 本文作者:小麦苗,只专注于数据库的技术,更注重技术的运用
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-07-01 09:00 ~ 2017-07-31 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
...............................................................................................................................
拿起手机使用微信客户端扫描下边的左边图片来关注小麦苗的微信公众号:xiaomaimiaolhr,扫描右边的二维码加入小麦苗的QQ群,学习最实用的数据库技术。
