Linux Namespace 介绍
我们经常听到说Docker 是一个使用了Linux Namespace 和 Cgroups 的虚拟化工具,但是什么是Linux Namespace 它在Docker内是怎么被使用的,说到这里很多人就会迷茫,下面我们就先介绍一下Linux Namespace 以及它们是如何在容器里面使用的。
概念
Linux Namespace 是kernel 的一个功能,它可以隔离一系列系统的资源,比如PID(Process ID),User ID, Network等等。一般看到这里,很多人会想到一个命令chroot,就像chroot允许把当前目录变成根目录一样(被隔离开来的),Namesapce也可以在一些资源上,将进程隔离起来,这些资源包括进程树,网络接口,挂载点等等。
比如一家公司向外界出售自己的计算资源。公司有一台性能还不错的服务器,每个用户买到一个tomcat实例用来运行它们自己的应用。有些调皮的客户可能不小心进入了别人的tomcat实例,修改或者关闭了其中的某些资源,这样就会导致各个客户之间互相干扰。也许你会说,我们可以限制不同用户的权限,让用户只能访问自己名下的tomcat,但是有些操作可能需要系统级别的权限,比如root。我们不可能给每个用户都授予root权限,也不可能给每个用户都提供一台全新的物理主机让他们互相隔离,因此这里Linux Namespace就派上了用场。使用Namespace, 我们就可以做到UID级别的隔离,也就是说,我们可以以UID为n的用户,虚拟化出来一个namespace,在这个namespace里面,用户是具有root权限的。但是在真实的物理机器上,他还是那个UID为n的用户,这样就解决了用户之间隔离的问题。当然这个只是Namespace其中一个简单的功能。
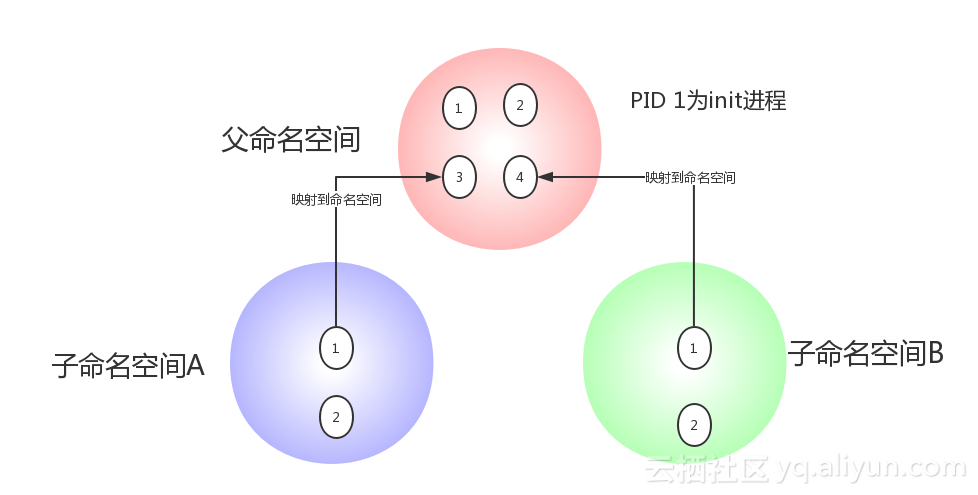
除了User Namespace ,PID也是可以被虚拟的。命名空间建立系统的不同视图, 对于每一个命名空间,从用户看起来,应该像一台单独的Linux计算机一样,有自己的init进程(PID为1),其他进程的PID依次递增,A和B空间都有PID为1的init进程,子容器的进程映射到父容器的进程上,父容器可以知道每一个子容器的运行状态,而子容器与子容器之间是隔离的。从图中我们可以看到,进程3在父命名空间里面PID 为3,但是在子命名空间内,他就是1.也就是说用户从子命名空间 A 内看进程3就像 init 进程一样,以为这个进程是自己的初始化进程,但是从整个 host 来看,他其实只是3号进程虚拟化出来的一个空间而已。
当前Linux一共实现六种不同类型的namespace。
| Namespace类型 | 系统调用参数 | 内核版本 |
|---|---|---|
| Mount namespaces | CLONE_NEWNS | 2.4.19 |
| UTS namespaces | CLONE_NEWUTS | 2.6.19 |
| IPC namespaces | CLONE_NEWIPC | 2.6.19 |
| PID namespaces | CLONE_NEWPID | 2.6.24 |
| Network namespaces | CLONE_NEWNET | 2.6.29 |
| User namespaces | CLONE_NEWUSER | 3.8 |
Namesapce 的API主要使用三个系统调用
clone()- 创建新进程。根据系统调用参数来判断哪种类型的namespace被创建,而且它们的子进程也会被包含到namespace中unshare()- 将进程移出某个namespacesetns()- 将进程加入到namesp中
UTS Namespace
UTS namespace 主要隔离nodename和domainname两个系统标识。在UTS namespace里面,每个 namespace 允许有自己的hostname。
下面我们将使用Go来做一个UTS Namespace 的例子。其实对于 Namespace 这种系统调用,使用 C 语言来描述是最好的,但是本书的目的是去实现 docker,由于 docker 就是使用 Go 开发的,那么我们就整体使用 Go 来讲解。先来看一下代码,非常简单:
package main
import (
"os/exec"
"syscall"
"os"
"log"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}
解释一下代码,exec.Command('sh') 是去指定当前命令的执行环境,我们默认使用sh来执行。下面的就是设置系统调用参数,像我们前面讲到的一样,使用CLONE_NEWUTS这个标识符去创建一个UTS Namespace。Go帮我们封装了对于clone()函数的调用,这个代码执行后就会进入到一个sh 运行环境中。
我们在ubuntu 14.04上运行这个程序,kernel版本3.13.0-65-generic,go 版本1.7.3,执行go run main.go,我们在这个交互式环境里面使用pstree -pl查看一下系统中进程之间的关系
|-sshd(19820)---bash(19839)---go(19901)-+-main(19912)-+-sh(19915)---
pstree(19916)
然后我们输出一下当前的 PID
# echo $$
19915
验证一下我们的父进程和子进程是否不在同一个UTS namespace
# readlink /proc/19912/ns/uts
uts:[4026531838]
# readlink /proc/19915/ns/uts
uts:[4026532193]
可以看到他们确实不在同一个UTS namespace。由于UTS Namespace是对hostname做了隔离,那么我们在这个环境内修改hostname应该不影响外部主机,下面我们来做一下实验。
在这个sh环境内执行
修改hostname 为bird然后打印出来
# hostname -b bird
# hostname
bird
我们另外启动一个shell在宿主机上运行一下hostname看一下效果
root@iZ254rt8xf1Z:~# hostname
iZ254rt8xf1Z
可以看到外部的 hostname 并没有被内部的修改所影响,由此就了解了UTS Namespace的作用。
IPC Namespace
IPC Namespace 是用来隔离 System V IPC 和POSIX message queues.每一个IPC Namespace都有他们自己的System V IPC 和POSIX message queue。
我们在上一版本的基础上稍微改动了一下代码
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}
可以看到我们仅仅增加syscall.CLONE_NEWIPC代表我们希望创建IPC Namespace。下面我们需要打开两个shell 来演示隔离的效果。
首先在宿主机上打开一个 shell
查看现有的ipc Message Queues
root@iZ254rt8xf1Z:~# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
下面我们创建一个message queue
root@iZ254rt8xf1Z:~# ipcmk -Q
Message queue id: 0
然后再查看一下
root@iZ254rt8xf1Z:~# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
0x5e8f3f1e 0 root 644 0 0
这里我们发现是可以看到一个queue了。下面我们使用另外一个shell去运行我们的程序。
root@iZ254rt8xf1Z:~/gocode/src/book# go run main.go
# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
通过这里我们可以发现,在新创建的Namespace里面,我们看不到宿主机上已经创建的message queue,说明我们的 IPC Namespace 创建成功,IPC 已经被隔离。
PID Namesapce
PID namespace是用来隔离进程 id。同样的一个进程在不同的 PID Namespace 里面可以拥有不同的 PID。这样就可以理解,在 docker container 里面,我们使用ps -ef 经常能发现,容器内在前台跑着的那个进程的 PID 是1,但是我们在容器外,使用ps -ef会发现同样的进程却有不同的 PID,这就是PID namespace 干的事情。
再前面的代码基础之上,我们再修改一下代码,添加了一个syscall.CLONE_NEWPID
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC | syscall.CLONE_NEWPID,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}
我们需要打开两个 shell,首先我们在宿主机上看一下进程树,找一下我们的进程的真实 PID
root@iZ254rt8xf1Z:~# pstree -pl
|-sshd(894)-+-sshd(9455)---bash(9475)---bash(19619)
| |-sshd(19715)---bash(19734)
| |-sshd(19853)---bash(19872)---go(20179)-+-main(20190)-+-sh(20193)
| | | |-{main}(20191)
| | | `-{main}(20192)
| | |-{go}(20180)
| | |-{go}(20181)
| | |-{go}(20182)
| | `-{go}(20186)
| `-sshd(20124)---bash(20144)---pstree(20196)
可以看到,我们的go main 函数运行的pid为 20190。下面我们打开另外一个 shell 运行一下我们的代码
root@iZ254rt8xf1Z:~/gocode/src/book# go run main.go
# echo $$
1
可以看到,我们打印了当前namespace的pid,发现是1,也就是说。这个20190 PID 被映射到 namesapce 里面的 PID 为1.这里还不能使用ps 来查看,因为ps 和 top 等命令会使用/proc内容,我们会在下面的mount namesapce讲解。
Mount Namespace
mount namespace 是用来隔离各个进程看到的挂载点视图。在不同namespace中的进程看到的文件系统层次是不一样的。在mount namespace 中调用mount()和umount()仅仅只会影响当前namespace内的文件系统,而对全局的文件系统是没有影响的。
看到这里,也许就会想到chroot()。它也是将某一个子目录变成根节点。但是mount namespace不仅能实现这个功能,而且能以更加灵活和安全的方式实现。
mount namespace是Linux 第一个实现的namesapce 类型,因此它的系统调用参数是NEWNS(new namespace 的缩写)。貌似当时人们没有意识到,以后还会有很多类型的namespace加入Linux大家庭。
我们针对上面的代码做了一点改动,增加了NEWNS 标识。
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}
首先我们运行代码后,查看一下/proc的文件内容。proc 是一个文件系统,它提供额外的机制可以从内核和内核模块将信息发送给进程。
# ls /proc
1 14 19872 23 34 43 55 739 865 bus filesystems kpagecount pagetypeinfo sysvipc
10 145 2 24 348 44 57 75 866 cgroups fs kpageflags partitions timer_list
100 1472 20 25 35 45 58 76 869 cmdline interrupts latency_stats sched_debug timer_stats
11 1475 20124 26 353 47 59 77 894 consoles iomem loadavg schedstat tty
1174 15 20129 27 36 48 6 776 9 cpuinfo ioports locks scsi uptime
1192 154 20144 28 37 49 60 78 937 crypto ipmi mdstat self version
12 155 20215 29 38 5 607 796 945 devices irq meminfo slabinfo version_signature
1255 16 20226 3 39 50 61 8 9460 diskstats kallsyms misc softirqs vmallocinfo
1277 17 20229 30 391 51 62 827 967 dma kcore modules stat vmstat
1296 18 20231 31 40 52 63 836 99 driver key-users mounts swaps xen
13 19 21 32 41 53 7 860 acpi execdomains keys mtrr sys zoneinfo
1309 19853 22 33 42 54 733 862 buddyinfo fb kmsg net sysrq-trigger
因为这里的/proc还是宿主机的,所以我们看到里面会比较乱,下面我们将/proc mount到我们自己的namesapce下面来。
# mount -t proc proc /proc
# ls /proc
1 consoles execdomains ipmi kpagecount misc sched_debug swaps uptime
5 cpuinfo fb irq kpageflags modules schedstat sys version
acpi crypto filesystems kallsyms latency_stats mounts scsi sysrq-trigger version_signature
buddyinfo devices fs kcore loadavg mtrr self sysvipc vmallocinfo
bus diskstats interrupts key-users locks net slabinfo timer_list vmstat
cgroups dma iomem keys mdstat pagetypeinfo softirqs timer_stats xen
cmdline driver ioports kmsg meminfo partitions stat tty zoneinfo
可以看到,瞬间少了好多命令。下面我们就可以使用 ps 来查看系统的进程了。
# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 20:15 pts/4 00:00:00 sh
root 6 1 0 20:19 pts/4 00:00:00 ps -ef
可以看到,在当前namesapce里面,我们的sh 进程是PID 为1 的进程。这里就说明,我们当前的Mount namesapce 里面的mount 和外部空间是隔离的,mount 操作并没有影响到外部。Docker volume 也是利用了这个特性。
User Namesapce
User namespace 主要是隔离用户的用户组ID。也就是说,一个进程的User ID 和Group ID 在User namespace 内外可以是不同的。比较常用的是,在宿主机上以一个非root用户运行创建一个User namespace,然后在User namespace里面却映射成root 用户。这样意味着,这个进程在User namespace里面有root权限,但是在User namespace外面却没有root的权限。从Linux kernel 3.8开始,非root进程也可以创建User namespace ,并且此进程在namespace里面可以被映射成 root并且在 namespace内有root权限。
下面我们继续以一个例子来描述.
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS |
syscall.CLONE_NEWUSER,
}
cmd.SysProcAttr.Credential = &syscall.Credential{Uid: uint32(1), Gid: uint32(1)}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
os.Exit(-1)
}
我们在原来的基础上增加了syscall.CLONE_NEWUSER。首先我们以root来运行这个程序,运行前在宿主机上我们看一下当前用户和用户组
root@iZ254rt8xf1Z:~/gocode/src/book# id
uid=0(root) gid=0(root) groups=0(root)
可以看到我们是root 用户,我们运行一下程序
root@iZ254rt8xf1Z:~/gocode/src/book# go run main.go
$ id
uid=65534(nobody) gid=65534(nogroup) groups=65534(nogroup)
Network Namespace
Network namespace 是用来隔离网络设备,IP地址端口等网络栈的namespace。Network namespace 可以让每个容器拥有自己独立的网络设备(虚拟的),而且容器内的应用可以绑定到自己的端口,每个 namesapce 内的端口都不会互相冲突。在宿主机上搭建网桥后,就能很方便的实现容器之间的通信,而且每个容器内的应用都可以使用相同的端口。
同样,我们在原来的代码上增加一点。我们增加了syscall.CLONE_NEWNET 这里标识符。
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS |
syscall.CLONE_NEWUSER | syscall.CLONE_NEWNET,
}
cmd.SysProcAttr.Credential = &syscall.Credential{Uid: uint32(1), Gid: uint32(1)}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
os.Exit(-1)
}
首先我们在宿主机上查看一下自己的网络设备。
root@iZ254rt8xf1Z:~/gocode/src/book# ifconfig
docker0 Link encap:Ethernet HWaddr 02:42:d7:5d:c3:b9
inet addr:192.168.0.1 Bcast:0.0.0.0 Mask:255.255.240.0
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
eth0 Link encap:Ethernet HWaddr 00:16:3e:00:38:cc
inet addr:10.170.174.187 Bcast:10.170.175.255 Mask:255.255.248.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:5605 errors:0 dropped:0 overruns:0 frame:0
TX packets:1819 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:7129227 (7.1 MB) TX bytes:159780 (159.7 KB)
eth1 Link encap:Ethernet HWaddr 00:16:3e:00:6d:4d
inet addr:101.200.126.205 Bcast:101.200.127.255 Mask:255.255.252.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:15433 errors:0 dropped:0 overruns:0 frame:0
TX packets:6888 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:13287762 (13.2 MB) TX bytes:1787482 (1.7 MB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
可以看到我们宿主机上有lo, eth0, eth1 等网络设备,下面我们运行一下程序去Network namespce 里面去看看。
root@iZ254rt8xf1Z:~/gocode/src/book# go run main.go
$ ifconfig
$
我们发现,在Namespace 里面什么网络设备都没有。这样就能展现 Network namespace 与宿主机之间的网络隔离。
小结
本节我们主要介绍了Linux Namespace,一共有六种类别的Namespace, 我们分别简单的介绍了一下,然后以 Go 语言为例子做了一下 demo,让大家方便有一个直观的认识,我们会在后面的章节中使用到这些知识,而且对于这些namespace的应用,后面章节会有更加复杂的例子等待着大家。
相关图书推荐<<自己动手写 docker>>
