
知己知彼,无论你是想成为黑客(最好不要!)或防范未来黑客的入侵,都有必要来了解一下如何骗过由海量数据训练出来的深度学习模型。
只要有程序员还在编程,黑客们就会不遗余力地找寻利用这些程序的方法。恶意黑客更是会利用程序中最为微小的漏洞来侵入系统,窃取数据,对系统造成严重破坏。
但由深度学习算法驱动的系统应该是能够避免人为干扰的,对吧? 一个黑客怎么能够突破被TB(兆兆字节)级数据训练的神经网络呢?
然而事实证明,即使是最先进的深层神经网络也是很容易被欺骗的。只需要使用一些小技巧,你就可以迫使模型预测出你想要的任何结果:
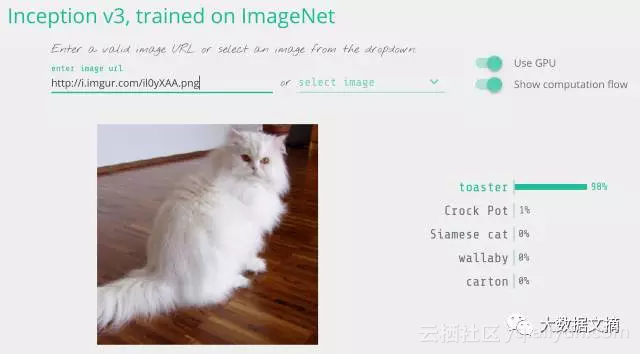
我们可以修改上面这幅喵星人照片好让它被模型识别为烤面包机。
因此,在你将启用由深层神经网络驱动的新系统之前,让我们详细了解一下如何去破坏系统以及如何保护自己的系统免受黑客的攻击。
神经网络帮助人们保护网络安全
现在我们假设自己经营着一个像Ebay这样的拍卖网站。在我们的网站上,我们想防止人们出售违禁物品——比如活的动物。
但是假如你有数百万的用户,执行这些规则将是非常困难的。我们可以聘请上百人去手动审查每一个拍卖清单,但这无疑将非常昂贵。相反,我们可以使用深度学习去自动检查拍卖照片是否属于违禁物品,并对那些违禁品照片进行标记。
这是一个典型的图像分类问题。为了搭建这个模型,我们将训练一个深层卷积神经网络来从合规物品中识别出违禁物品,之后将识别模型运行于网站上的所有照片。
首先,我们需要一个基于历史拍卖列表的含有成千上万个拍卖图片的数据集。 数据集需要既有合规物品图片又有违禁物品图片,以便于我们训练神经网络来区别他们:

然后着手开始训练神经网络,这里我们使用标准的反向传播算法。这个算法的原理是,我们通过一个训练图片,传递该图片的预期结果,然后回到神经网络中的每一层去轻微地调节他们的权重,从而使模型更好地产生该图片的正确输出:
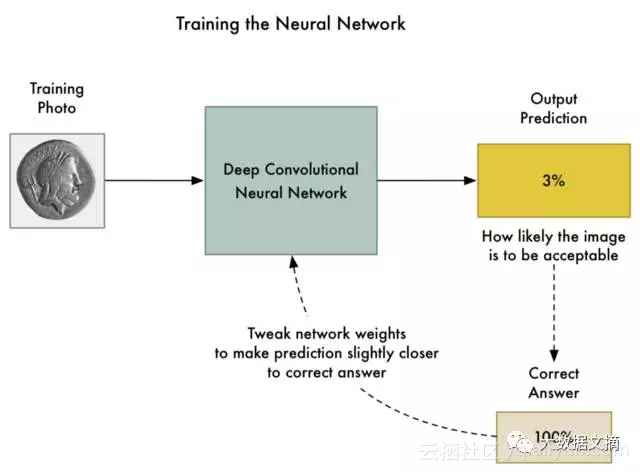
我们使用数千张照片重复上述过程上千次,直到模型以可接受的准确性稳定地输出正确结果为止。
最终我们将得到一个可以稳定地将图像分类的神经网络模型:
但事情往往并不如他们看起来的那么可靠…
卷积神经网络在对图像进行整体识别和分类上是非常强大的。他们在识别复杂形状和图案时并不受其在画面中所处位置的影响。在许多图像识别任务中,它们的表现可以媲美甚至于击败人类的表现。
对于这样高端的模型,如果将图像中的一些像素加黑或者变亮,对最终的预测结果不应该有很大的影响,对吧?是的,它有可能会轻微改变预测结果的可能性概率,但不会将图像的预测结果从“违禁品”改判为“合规品”。
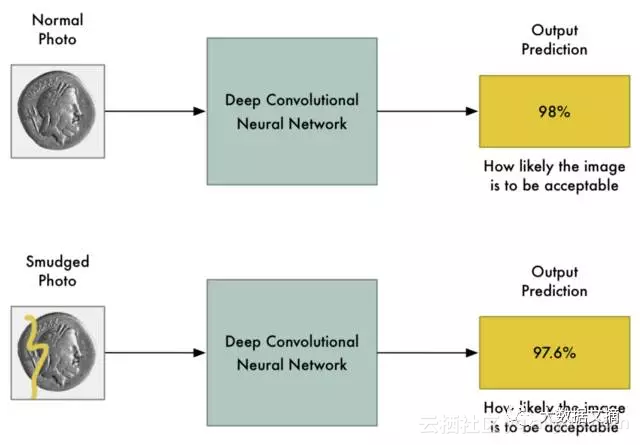
我们期望的是:输入照片的微小变化只会对最终预测结果造成微小的变化。
然而,2013年的著名论文《神经网络的有趣特性》发现了这并不总是真的。如果你确切地知道了要更改哪些像素点以及要对其做出多大的改变,你就可以有意地强制神经网络对于给定图像做出错误预测,而不需要对图像外观做出大的改动。
这意味着我们可以故意制作一张明显是违禁物品的照片,但使它完全骗过我们的神经网络模型。
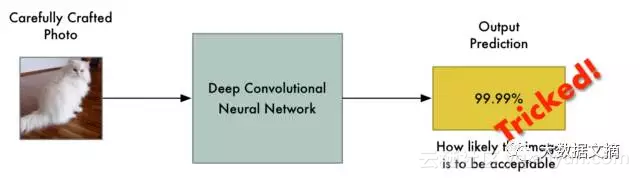
怎么会这样?机器学习分类器的工作原理就是找到意图区分事物之间的分界线。 以下图示是一个简单的二维分类器,它学习的目标是将绿球(合规)与红球(违规)区分开来:
现在,分类器的精度达到100%。它找到了一条可以将所有的绿球与红球完美分开的区隔线。
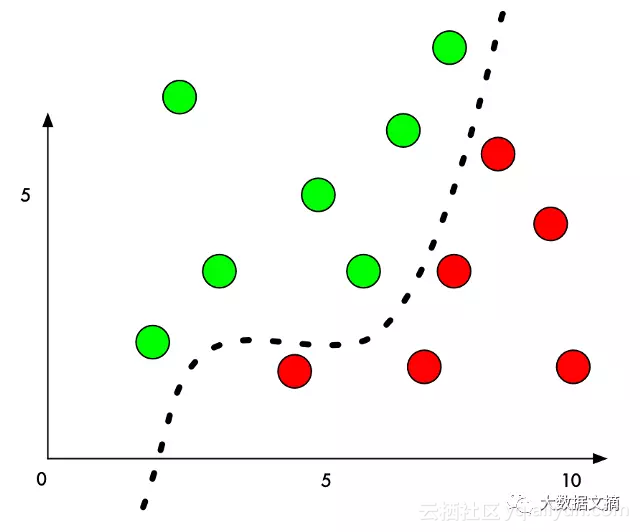
但是,如果我们想要调整一下模型使得一个红球被故意区分成绿球呢?我们最少要将红球移动多少才会使得它被推到绿球的判定区域呢?
如果我们把分界线旁边那个红球的Y值少量增加,那么我们就几乎可以把它推到绿球的判定区域了:
所以要想欺骗一个分类器,我们只需要知道从哪个方向来推动这个点可以使它越过区隔线即可。如果我们不想使这个错误过于明显,理想情况下我们会使这个移动尽可能的小,以至于其看起来就像是一个无心之过。
在使用深层神经网络进行图像分类时,我们分类的每个“点”其实是由成千上万个像素组成的完整图像。这就给了我们成千上万个可以通过微调来使预测结果跨过决策线的可能值。如果我们可以确保自己对图像中像素点的调整不是肉眼可见般的明显,我们就可以做到在愚弄分类器的同时又不会使图像看起来是被人为篡改过的。
换句话说,我们可以选取一张真实物品的图像,通过对特定像素点做出非常轻微地修改使得图像被神经网络完全识别为另一件物品—而且我们可以精准地控制这个替代品是什么:
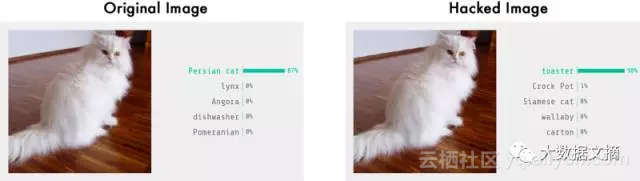
把一只猫变成烤面包机。图像检测结果来自与Keras.js的Web演示:https://transcranial.github.io/keras-js/#/inception-v3
如何欺骗神经网络
我们之前已经讨论了训练神经网络以分类照片的基本过程:
1.添加一张训练用图片;
2.查看神经网络的预测结果,看看其距离正确答案有多远;
3.使用反向传播算法来调整神经网络中每一层的权重,使预测结果更接近于正确答案。
4.在数千张不同的训练照片上重复步骤1-3。
那么相比于调整神经网络每一层的权重,如果我们直接修改输入图像本身直到得到我们想要的答案为止呢?
所以我们选用了已经训练好的神经网络,并再次“训练”它,不过这次我们将使用反向传播算法来直接调整输入图像而不是神经网络层的权重:
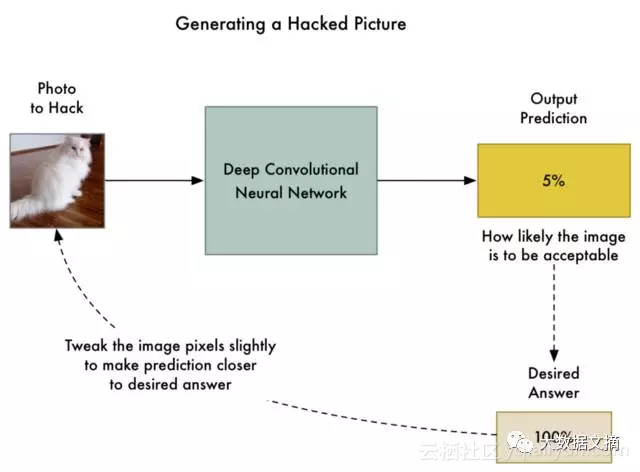
所以这里是新的算法:
1.添加一张我们想要“黑”的照片。
2.检查神经网络的预测结果,看看其距离我们想要的答案有多远。
3.使用反向传播算法来调整照片本身,使预测结果更接近于我们想要的答案。
4.使用相同的照片重复步骤1-3上千次,直到神经网络输出结果为我们想要的答案为止。
在此之后,我们将会得到一张可以欺骗神经网络的图片,同时并不改变神经网络本身。
唯一的问题是,由于算法在调整上没有任何限制,允许以任何尺度来调整任何像素点,所以图像的最终更改结果可能会大到显而易见:他们会出现变色光斑或者变形波浪区域

一张被“黑”过的照片,由于没有对像素点可被调整的尺度做约束,你可以看到猫周围有了绿色光斑和白色墙壁上出现的波浪形图案。
为了防止这些明显的图形失真,我们可以将算法加上一个简单的限定条件。我们限定篡改的图片中每一个像素在原始的基础上的变化幅度取一个微量值,譬如0.01%。这就使算法在微调图片的时候仍然能够骗过神经网络却不会与原始图片差别太大。
在加入限定后重新生成的图片如下:

在每个像素只能在一定范围内变化的限制条件下生成的被“黑”的图片。
即使这张图对人眼来说篡改后没有区别,却可以骗过神经网络!
现在让我们来码代码
首先我们需要一个事先训练过的神经网络用来欺骗。我们不用重新开始训练,而是使用谷歌创建的神经网络。。
Keras是一个著名的深度学习框架,里面有几个预先训练过的神经网络。我们会使用其中的谷歌Inception v3 深度学习神经网络的拷贝。这个神经网络有过训练,曾经检测过超过一千种不同的物体。
下面是Keras中用此神经网络负责图像识别的基本代码。(文本代码详见链接)https://gist.github.com/ageitgey/8a010ee99f55fe2ef93cae7d02e170e8#file-predict-py
在继续下去之前确保你预先安装了Python 3和Keras:
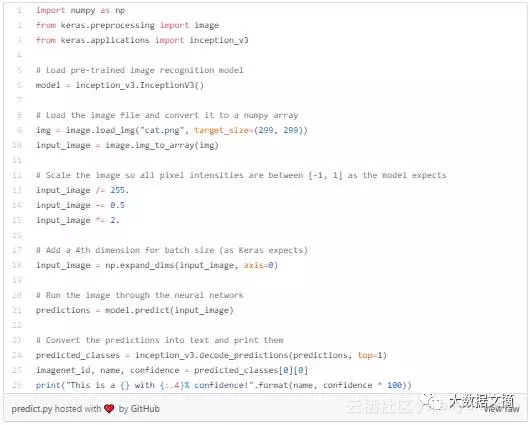
我们运行之后,它正确检测到了我们的图片是一只波斯猫:

现在我们微微篡改一下图片直到能够骗过这个神经网络让它认为图片是一个烤面包机。
Keras没有内置的可以通过输入图片训练的方法只有训练神经网络层,所以我只能提高技巧手动编写训练步骤的代码。
下面是我的代码:(文本代码详见链接)https://gist.github.com/ageitgey/873e74b7f3a75b435dcab1dcf4a88131#file-generated_hacked_image-py
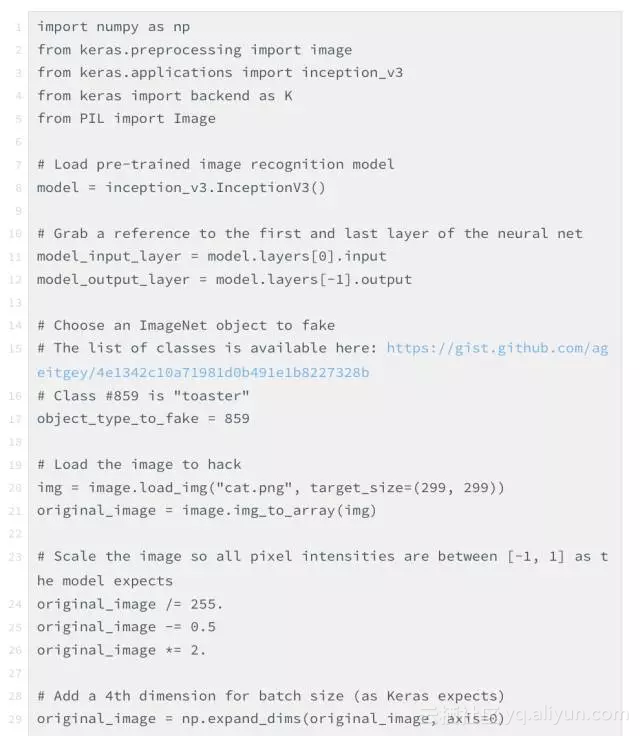



运行后,最终我们可以得到能够骗过神经网络的图片。

注意:如果你没有GPU,这可能需要几个小时的时间运行。如果你有并且配置了Keras和CUDA,应该花不了几分钟。
现在我们将篡改后的图片放入原始模型中重新运行来测试其是否成功。

我们成功了!神经网络被我们欺骗了,把猫当成烤面包机了!
我们用被“黑”了的图片可以干什么?
这种被“黑”图片的操作被称为“创造对抗性的例子”。我们很有针对性的做出了让机器学习模型产生错误的一些数据。这个操作很巧妙,但在实际生活中有什么用呢?
研究者发现这些篡改图片有一些很令人惊喜的性质:
当被“黑”图片被打印出来后居然仍然可以欺骗神经网络!因此你可以用这些特殊的图片欺骗镜头和扫描仪,而不仅仅是电脑里上传图片的那种系统。
当神经网络被欺骗之后,如果其它的神经网络也是用类似的数据来训练的,即使设计完全不同,也能被这种特殊的图片欺骗。
因此我们可以用这些篡改图片做许多事情!
但是关于我们如何创造出这些特殊图片还具有很多限制——我们的操作需要能够直接进入神经网络的权限。因为我们实际上是“训练”神经网络来欺骗自身,我们需要它的拷贝版。在实际生活中,没有公司会让你下载的到他们受过训练的神经网络的代码,这也就意味着我们无法来进行这个攻击性的操作了……对吗?
并没有!研究者近日发现,我们可以利用探测另外一个神经网络的动向来镜像同步自己网络的方法,训练自己的替代性的神经网络。
然后你就可以用替代性的神经网络来生成被“黑”图片,这依然可以骗过原来的网络!这招叫做黑箱攻击。
这种攻击的范围没有限制,后果可以很可怕!下面是一些黑客能够做到的例子:
欺骗自动驾驶汽车使其认为看到的“停车”路标是一个绿灯——这可以引起车祸!
欺骗内容过滤系统使其无法识别出具有攻击性的和非法的信息。
欺骗ATM支票扫描系统使其错误的识别支票上面的实际金额信息。(如果你被抓到的话还可以很合理的推卸掉自己的罪责!)
这些攻击方法不仅限于图片篡改。你可以用同样的方式去欺骗处理其他种类数据的分类器。譬如,你可以欺骗病毒扫描仪将你的病毒错误地识别为安全的!
我们如何防止这样的攻击?
现在我们知道了神经网络是可以被欺骗的(包括其他的机器学习模型),我们如何防止呢?
简单来说,还没有人是能完完全全保证安全的。防止这类攻击的方法仍然在研究中。要始终紧跟最新的研究进展,最好的方式是跟进Ian Goodfellow和Nicolas Papernot写的cleverhans博客,他们俩是这一领域里最具有影响力的研究者。
但是我们目前已经知道的一些事情是:
如果你只是简单的创造很多被“黑”的图片,并将这些纳入到你之后的训练数据中,这会使你的神经网络更容易抵抗这些攻击。我们称之为对抗性训练,这也许是目前最可以考虑的一种防御手段。
有另外一种有效果的方法叫做防御性蒸馏法,这种方法是训练另一个模型来模仿你原有的模型。但这是一种新的方法并且相当复杂,所以除非有特殊的需求,我还不想继续研究这个方法。
目前为止,研究人员尝试了其他所有能想到的防御这些攻击的方法,都失败了。
既然我们还没有最后的定论,我建议你在使用神经网络的时候考虑一下这种攻击会对你的工作带来什么样的损失,至少可以降低一些风险。
譬如,如果你只有一个单一的机器学习模型作为鉴别保密信息源的唯一安全防线,即使它不会被欺骗,也并不是一个好主意。但是假如你只是用机器学习作为一个中间处理过程,还是有人工鉴别的操作,也许就会没事。
换句话说,将机器学习模型和其他手段一样看成不是完全可靠的技术。想一想如果某个用户故意黑进你的系统欺骗你的网络,这会带来什么样的后果,你需要怎么样处理来降低这种风险。