1.4 从数据库中导入数据
使用一个专用的数据库测试平台比根据需要从磁盘中导入文件效率要高很多,这是由数据库本身特性决定的:
对大数据表的访问速度更快
在数据导入R前,提供了更快更有效的数据聚集和筛选方法
相比电子表格以及R对象实现的传统矩阵模型,能够提供更加结构化的关系
数据模型来存储数据
提供对数据的连接及合并操作
在同一时间支持对多个客户端的并发远程访问
提供了安全和有限的访问
提供可扩展及可配置的数据存储后台
DBI包提供了数据库操作的接口,可以作为R和不同关系数据管理系统(Relational Database Management System,RDBMS)之间的交互通道,例如MySQL、PostgreSQL、Oracle以及类似开放文档数据库等。一般并不需要安装各个数据库的相关包,因为作为一个接口,该包会在需要时被自动安装。
由于这些平台基本都是基于关系模型并采用SQL作为数据管理和查询工具,因此R与在这些不同平台中连接数据库与处理数据的方法都基本类似。但要注意在以上提到的数据库引擎之间还是存在一些比较重要的差别,也存在一些其他的开源和商业化的替代产品。我们不会深入讨论怎么选择这些数据库,也不会详细介绍构建数据仓库的方法,以及抽取、转换和装载(ETL)工作流的过程,我们的讨论仅局限于创建数据连接以及在R中如何管理数据。
SQL最初由IBM开发,距今已有40多年的历史,它是世界上最重要的程序语言之一——具有多种不同的实现版本。作为应用最为广泛的声明性语言之一,有许多关于使用SQL进行数据查询和管理的在线指南和免费课程。SQL可以说是数据科学家最重要的工具之一,就像我们家里的瑞士军刀一样。
因此,除R之外,对于诸如数据分析师这样的工作职位,精通RDBMS是非常普遍,也是非常重要的。
1.4.1 搭建测试环境
数据库后台服务器通常位于远离数据分析用户的服务器上,但为了测试需要,我们需要在本地环境安装实例。由于不同操作系统环境下的安装过程不同,我们不会介绍安装的细节内容,而更多地介绍软件下载的地址以及给出一些和安装有关的帮助文档和资源的链接。
请注意数据库安装和数据导入的过程很多是可选的,因此读者不需要完完全全地照搬我们给出的每一步操作指南——本书剩下的内容并不要求读者了解任何某一特定的数据库或具备类似的操作经验。读者如果不希望因为安装过多的临时数据库弄混了自己本机的环境,可以选择在虚拟机里面执行这些操作。Oracle的VirtualBox能够更好地支持多种特定操作系统和用户空间环境。
有关下载和导入VirtualBox的内容,请参考1.4.4节。
通过虚拟机,读者可以快速得到一个功能完整的一次性的数据库环境来验证本章提到的样例。在接下来的图示中,我们将为读者展示一个包含4个虚拟机的VirtualBox,其中三个在后台运行,能够实现部分测试功能。
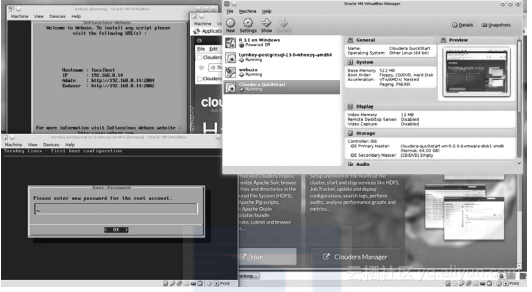
VirtualBox可以在Linux环境通过包管理器安装,也可以从http://www.virtualbox.org/wiki/Downloads下载安装资源。有关不同操作系统下的特定安装过程,请参考本书第2章。
现在安装和使用虚拟机已经非常简单,只需要导入和启动虚拟机镜像文件即可。一些虚拟机应用,也被称为虚拟设备,包括操作系统和部分的软件都已经预先设置好了,可以很简单地完成配置。
再次申明,如果读者不乐意做安装和测试新软件的工作,或者不希望花时间了解用来控制数据需求的基础操作,下面这些操作步骤不是必要的,你可以快速略过以下为开发人员和数据科学家准备的内容。
Internet上有关这些预先定义好可以运行在任何环境下的虚拟机系统的下载链接非常多,文件格式也多种多样,包括OVF和OVA等。比较通用的VirtualBox虚拟应用可以从http://virtualboximages.com/vdi/index或http://virtualboxes.org/images/下载。
虚拟应用应该导入到VirtualBox内使用,而是非OVF/OVA磁盘镜像应该附加到新增加的虚拟机上,因此,读者有可能需要更多的操作指引。
Oracle为满足数据科学家们以及其他开发者的需要,提供了丰富的虚拟镜像文件,访问地址为:http://www.oracle.com/technetwork/community/developer-vm/index.html。例如,Oracle Big Data Lite VM开发者的虚拟应用就具有以下这些重要的部分:
Oracle数据库
Apache Hadoop以及各种云计算工具
Oracle R分布
企业版Oracle Linux
声明:从个人角度而言,Oracle不是我对数据库后台的首选,但该产品确实在与平台无关的虚拟化环境方面做得很棒,比方说基于他们的商业化产品提供的免费虚拟开发版本。简而言之,用Oracle做后台是没错的。
如果读者不能通过网络访问已经安装好的虚拟机,可以更改一下其网络设置,如果仅本机访问,可以使用Host-only adapter项,否则可以使用限制少的Bridged Networking项。后者需要为虚拟机保留一个额外的IP地址,使得虚拟机可以通过网络访问。更多详细内容及样例请参考1.4.4节。
Turnkey GNU/Linux库(http://www.turnkeylinux.org/database)也可以作为创建开源数据库引擎虚拟应用的另一选择,其上镜像文件均基于Debian Linux,全部开源,目前已经能够支持MySql、PostgresSql、MongoDB和CouchDB。
Turnkey Linux最大的优势就是其包含免费开源的非专有性软件。另外,磁盘镜像文件的规模也更小,仅包含数据库引擎需要的核心文件,使得它的安装速度更快,对硬盘和内存空间的要求更低。
对于最近很热门的Docker,我强烈建议读者了解并掌握它的概念,因为使用它来完成软件配置惊人地快捷。像Docker这样的容器可以被看成一个独立的文件系统,包括操作系统、库、工具、数据,这些内容全部位于Docker镜像提供的抽象层上,也意味着我们可以在自己的本地主机仅使用一行命令就能启动带有部分仿真数据的数据库,而开发类似的定制镜像也非常容易。请参阅https://github.com/cardcorp/card-rocker,这是我的R以及和Pandoc有关的Docker镜像。
1.4.2 MySQL和MariaDB
MariaDB是采用社区模式开发的,是MySQL的一个完全开源的分支,由MySQL的主要创始人Michael Widenius启动和引导。后来与SkySQL合并,很多前MySQL的研发人员和投资者都加入了这个项目。Sun Microsystem在购买了MySQL后开始开发MariaDB,目前由Oracle拥有,数据库引擎的开发也转移了。
在本书中为了简单起见,我们将这两种引擎都称为MySQL,因为MariaDB可以被看成MySQL的简易版本,因此以下样例在两种引擎中都可用。
尽管MySQL的安装在很多操作系统上都非常简单(https://dev.mysql.com/downloads/mysql/),读者最好在虚拟机上来完成安装。Turnkey Linux提供了一个功能完整的精简版,免费安装文件在http://www.turnkeylinux.org/mysql。
R语言提供了多种从MySQL中查询数据的方法。例如,使用RMySQL包,不过它的安装对一部分读者来说可能有点困难。如果读者使用Linux操作系统,记住要同时安装MySQL的开发包和MySQL客户端,以便能够在本机完成包的编译。由于MySQL版本太多了,因此在CRAN上没有为Windows用户提供二进制包,这部分用户应该从source完成包的编译:
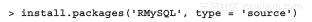
Windows用户可以在http://www.ahschulz.de/2013/07/23/installing-rmysqlunder-windows/上面找到详细的安装步骤指南。
为了简单,我们默认MySQL为本地服务器模式,端口为3306,数据库连接的用户名和口令分别为user/password。我们的工作表为hf?lights_db数据库中的hf?light表,和之前介绍SQLite样例中的一样。如果读者是采用远程终端或虚拟机模式访问,请根据样例更改相应的host,username等参数信息。
当成功完成MySQL服务器安装后,我们必须创建一个测试数据库,以便在之后操作中将其导入到R。现在,让我们启动MySQL命令行工具来创建数据库和测试用户。
请注意以下样例是运行在Linux环境下的,如果是Windows用户,请完善文件的路径以及exe文件的扩展名来完成MySQL命令行工具的启动:
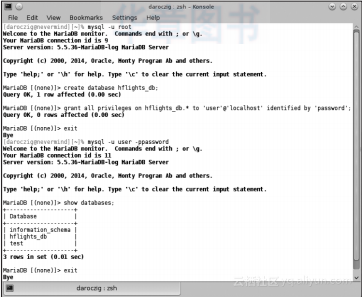
前面,我们在命令行中以root(管理员)用户身份连接MySQL服务器时也获取了类似截图。我们接着创建了一个名为hf?lights_db的数据库,将数据库所有的访问权限都赋给了一个名为user的新用户,该用户的密码为password。然后,我们简单地验证了是否能用该用户名及密码来连接数据库,就退出了MySQL客户端。
为了导入数据到R会话中,我们必须首先连接数据库并获得服务器访问的授权许可,可以在附加RMySQL时自动装载DBI包:

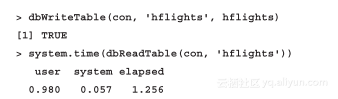
现在将MySQL连接命名为con,在下次连接中,将部署hf?lights数据库:

函数dbWriteTable将hf?ilghts数据框以同名方式写入之前定义好的连接,其后的命令显示了当前访问的数据库中所有的表的信息,等同于SQL命令中的SHOW TABLES的作用。现在,我们已经将原始的CVS文件导入到MySQL中,接下来我们再确认一下完成所有数据读入需要的时间:

我们也可以使用DBI包中dbGetQuery直接来达到同样效果:

同时,为了简化后面的样例,我们再次使用了sqldf包,该包表示“在数据框上执行SQL查询”。事实上,sqldf是DBI的dbSendQuery函数的封装器,某些参数是默认的,返回结果为data.frame。它能够处理包括SQLite、MySQL、H2和PostgreSQL等多种数据库引擎。可以在sqldf.driver中指明某种特定需要处理的数据库引擎,如果该值为NULL,那么系统会检测上述后台数据库是否正确加载了R包。
由于前面我们已经导入了RMySQL,因此sqldf会默认使用MySQL而非SQLite引擎。不过我们还是要指明要使用的连接,否则函数会试图新建一个连接——并忽视掉我们所提供的复杂用户名及密码组合,更不用说难以理解的数据库名称了。可以在每个sqldf表达式中声明该连接,也可以在全局选项一次定义:
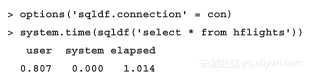
前面三种执行方式之间并没有显著的差别,与之前测试的结果相比,1秒多一点的执行时间看起来还不错——尽管使用data.table来装载整个数据集依然需要比较多的时间。如果我们仅需要处理一部分数据子集该怎么办呢?让我们尝试选取那些以Nashville为终点的航班信息,就像之前在SQLite中做的一样:

与SQLite的测试结果相比,MySQL的结果并没有太多过人之处,因为SQLite可以得到小于100毫秒的结果。但是值得注意的是这种方式的user时间和system时间都为零,这是SQLite没办法达到的。
system.time的返回值是自系统启动评估所经历的时间,这里的user时间和system时间对用户来说稍微有点难以理解,但幸好它们是由操作系统自己检测的。大体上,user时间指函数(R或者MySQL服务器)调用所需占用的CPU时间,而system时间指系统内核以及其他操作系统进程(例如打开一个要读取的文件)所需要的时间总和。可以调用?proc.time获得更多详细信息。
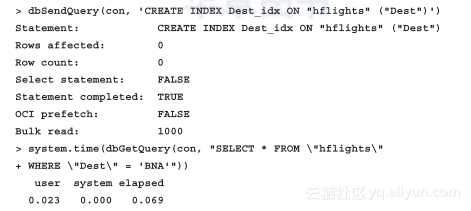
这两个时间为零意味着读取数据子集不需要耗费CPU资源,SQLite花在这上面大概需要100毫秒,这可能吗?如果我们在Dest属性上建立索引又会怎样呢?

SQL索引的存在能够极大提高带WHERE条件的SELECT语句的执行效率,有了索引,MySQL就不用为了确定最终结果而去遍历整个数据库对每一行记录都进行比较。数据集规模越大,索引的效果就越明显。不过需要注意的是,如果是对数据子集进行反复操作使用索引会更有价值,但如果每次处理的结果基本都是数据的全集,则更适合用顺序处理的方法。
例如:

看起来结果优化很多!当然,不仅仅是MySQL,我们也能在SQLite数据库上建立索引。为了再做一次测试,我们将sqldf驱动重新指定为SQLite,它之前被RMySQL包给覆盖了:

从结果可知两种数据库引擎在获取数据子集所花的时间都不到1秒,与之前耗费了大量时间的data.table操作相比优化了很多。
尽管对之前一些样例的测试SQLite比MySQL性能更优,但在很多情况下仍然更适合选择MySQL。原因如下:首先,SQLite是基于文件系统的数据库,这意味着数据库是放在附加在运行R的机器的文件系统上,也就是说R会话和SQLite数据库操作是在同一台机器上执行。类似地,MySQL可以处理大数据集,可以在用户管理和基于规则的控制方面有更多的优化,并且实现了对数据集的并发访问。而聪明的数据科学家知道该如何依据任务的不同特性来选择不同的数据库后台。让我们再看看在R中我们有哪些选择!
1.4.3 PostgreSQL
如果MySQL是最流行的开源关系数据库管理系统,PostgreSQL则以“世界上最先进的开源数据库”闻名。这意味着与功能简单但速度更快的MySQL相比,PostgreSQL功能更丰富,例如数据分析功能,这也使得PostgreSQL经常被看成开源版的Oracle。
这个比方现在听起来有点可笑,特别是Oracle已经收购了MySQL。而在过去的20到30年里,RDMBS发生了非常大的变化,PostgreSQL也不再像过去那样慢了。另一方面,MySQL也增加了一些新的功能——例如,MySQL通过InnoDB引擎也实现了ACID特性,支持对数据库操作的回滚。但在这两大类流行的数据库引擎之间依然存在一些不同,读者可以根据需要来选择合适的数据库。现在,我们来看一下如果数据提供者较MySQL更喜欢PostgreSQL会怎样!
安装PostgreSQL的过程和安装MySQL差不多。读者可以从http://www.enterprisedb.com/products-services-training/pgdownload上下载一个图形安装工具,再使用操作系统的包管理器来安装该软件。或者基于某个虚拟应用,例如Turnkey Linux,可以从http://www.turnkeylinux.org/postgresql获得一个精简但配置好的免费的磁盘镜像文件。
样例下载:读者可以使用自己的账号从http://www.packtpub.com下载Packt出版公司提供的样例源代码。如果读者是从其他渠道购买的本书,可以访问http://www.packtpub.com/support,注册成功后直接通过邮件获得源代码文件。
当成功安装好并启动服务器后,让我们来创建测试数据库——就像之前安装好MySQL以后做的工作一样。
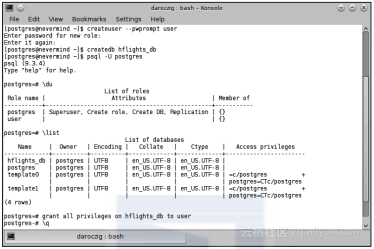
这里的语法和前面的样例稍有不同,我们使用了一些命令行工具来完成创建用户和创建数据库的任务。其中的帮助程序是PostgreSQL自带的,在MySQL里面也可以使用mysqladmin来达到类似目的。
当设置好了最初的测试环境后,或者我们已经准备好了数据库连接实例,我们可以在RPostgreSQL包的帮助下完成之前提到的一些数据库管理任务:

如果读者的R会话在执行下面的样例时弹出了某些陌生的错误信息,非常有可能是因为装载的R包之间有冲突。读者可以重新启动一个干净的R会话,或者去掉之前附加的R包,例如:detach ('package:RMySQL', unload = TRUE)。
连接数据库的操作也是类似的(服务器默认的监听端口为5432):

让我们验证一下是否已经连接到正确的数据库实例上,此时hflights表应该是个空表:

接下来在PostgreSQL里面处理样例表,并验证一下以前说用PostgreSQL要比用MySQL更慢的谣言是否属实:
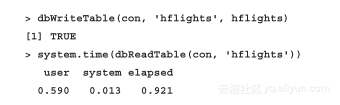
看起来有点惊人!再看一下对数据子集的处理:

在没使用索引的条件下,执行时间也小于100毫秒!请注意Dest上面多出来的引号,因为PostgreSQL会将不带引号的列名默认处理成小写,而数据表中并不存在一个“dest”的列,所以为了避免出错采取这样的处理。接下来可以像MySQL一样建立索引,也可以一样让结果得到优化。
1.4.4 Oracle数据库
Oracle数据库的Express版本可以从:http://www.oracle.com/technetwork/database/data-base-technologies/expressedition/downloads/index.html处下载并安装。尽管该版本功能并不完整,也存在诸多局限,但Express版本免费,适合用于在本机上建立对资源要求不那么高的应用。
Oracle数据库被称为世界上最流行的数据库管理系统,它需要专门的授权才能使用,这与之前我们讨论过的两类开源数据库不同,Oracle提供的产品对许可期限有要求。另一方面,这也意味着有专门的团队对其提供支持,而这常常是企业级应用所必需的。Oracle数据库自1980年诞生伊始,一直以功能丰富著称,例如数据共享、主机-主机复制和完全ACID支持等。
也可以从Oracle预编译开发虚拟环境下载一个用于测试的Oracle数据库(http://www.oracle.com/technetwork/community/developer-vm/index.html),或者从Oracle Technology Network Developer Day(http://www.oracle.com/technetwork/database/enterprise-edition/databaseappdev-vm-161299.html)下载一个更小的为移动客户端定制的镜像文件。下面的说明将以后者为例。
当在Oracle完成版权授予注册得到一个免费的使用资格后,我们可以下载OTN_Developer_Day_VM.ova虚拟应用。然后使用File菜单下的Import appliance命令将其导入到Virtual Box中,选择ova文件,点击“Next”:
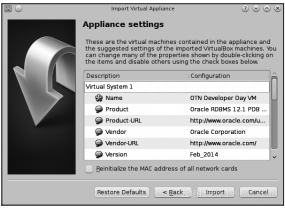
然后再点击“Import”,同意版本使用条件。可能需要花一点时间来完成镜像文件(15GB)的导入:
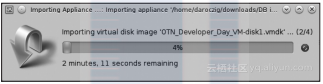
完成导入后,首先要更新网络配置,使得可以通过网络来访问虚拟机上的数据库文件。可以通过从“NAT”切换到“Bridged Adapter”完成设置:
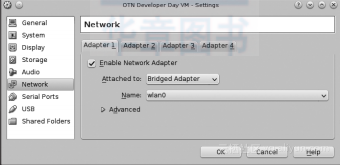
然后在Virtual Box启动新生成的虚拟机,当Oracle Linux启动后,就可以使用默认的oracle口令登录。
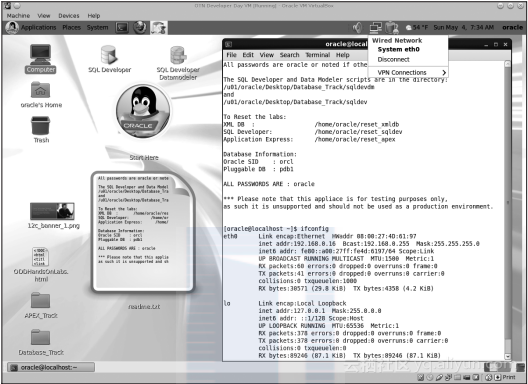
尽管已经为虚拟机设置了桥接网络模式,VM也可以使用一个真正的IP地址直接连接到实际的局域网络内,此时还不能通过网络来访问该虚拟机。为了使用默认的DHCP配置来完成连接,将鼠标移动到上面的红色按钮,找到网络项,选择System eth0项。几秒钟后,就可以从本机访问虚拟机了,此时客户机也已经能够联网。读者可以通过在控制台执行ifconf?ig或者ip addr show eth0命令来验证。
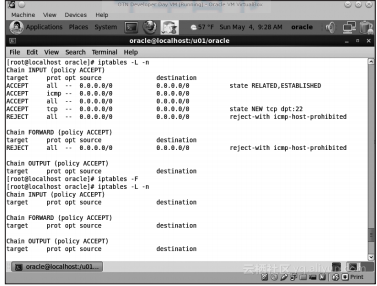
不过,这个已经启动的Oracle数据库实例还不能被虚拟机以外的应用访问。开发版本的VM有严格的防火墙设置,首先应该取消该防火墙。要查看哪些规则在起作用,可以运行标准的iptables-L-n命令或者执行iptables-F来废除所有的规则:
现在我们就可以通过远程访问这个已经启动了的Oracle数据库了。接下来我们再来准备R客户端。在某些操作系统上安装ROracle包可能有点困难,因为没有这样已经预编译好的包,读者需要在编译之前手动安装Oracle Instant Client Lite以及SDK库。如果编译器对之前安装Oracle库的路径存在疑问,请用--conf?igure-args参数,--with-oci-lib参数和--with-oci-inc来配置路径文件。更多相关内容可以参考包安装帮助文档:http://cran.r-project.org/web/packages/ROracle/INSTALL。
例如,在Arch Linux系统下,读者可以在AUR上完成Oracle库的安装,然后在从CRAN上下载R包后以批处理方式执行以下命令:

完成包的导入和安装后,使用DBI::dbConnect连接数据库的操作和前面的过程非常类似。这里只需要再增加一个额外的参数。首先,在dbname参数中指定数据库的主机名或者直接访问的IP地址,然后为了节约时间和空间,连接开发者机器上已经建好的PDB1数据库而不是前面用过的hf?lights_db数据库,因为数据库管理这个问题稍微有点偏离我们的主题了:

再为Oracle关系数据库建立一个连接:
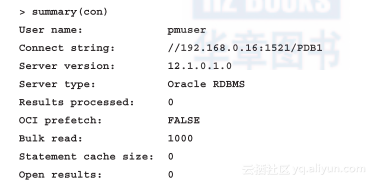
现在让我们来看一下在开发虚拟机带的免费数据库有什么内容:

一个名为TICKER的数据表,对股票数据采用三类标记建立了三种视图。将hf?lights表存放到同一数据库中不会产生不良后果,我们也可以马上通过读取整个表,对Oracle数据库的速度进行测试:
非常相似的子集包含3481条实例:

注意表名两边的引号,在前述MySQL和PostgreSQL样例中,SQL语句不需要增加这些标记,但是在Oracle数据库中我们必须添加,因为我们的表名全部使用了小写字母,而Oracle默认对象名称全部使用大写字符。因此最好的方法就是像我们一样,用双引号进行区分,就可以使用小写字符来标注表名了。
在MySQL中不需要用引号去标注表名和列名,而R在访问PostgreSQL数据库中必须要使用转义字符标注变量名称,在Oracle数据库中必须要使用双引号进行标注—这也证明了在标准ANSI SQL范围下不同风格的SQL之间的细微差别(例如,MySQL,PostgreSQL,Oracle的PL/SQL以及Microsoft的Transact-SQL)。更重要的是,不要让你的项目全部依赖于某一种数据库引擎,在公司政策允许的条件下,应该根据情况选择合适的DB。
与PostgreSQL的结果相比,Oracle数据库的结果不那么让人心动,让我们看一下带索引的查询:
我将完整的测试留给读者自己完成,这样读者就能根据自己的确切需求设计查询,可以肯定的是不同搜索引擎对不同样例的执行效率肯定是有所区别的。
为了让这个测试过程更流畅也更易于实现,让我们尝试R中另外一种连接数据库的方法,尽管它可能在性能上要差一点。如果要比较在R中用不同方法连接Oracle数据库的差别,可以参考https://blogs.oracle.com/R/entry/r_to_oracle_database_connectivity。
1.4.5 访问ODBC数据库
如前所述,为了从某些服务终端安装特定R包,而不得不安装特定的客户端软件、库、不同数据库的头文件,某些时候比较无聊并且难度也不低。不过幸好,我们可以尝试反着来做这件事。例如,在数据库中安装类似应用程序接口(Application Programming Interface,API)这样的中间件软件,这样R或者其他工具,就能以一种标准且简便的方式访问数据库。不过值得注意的是,由于需要在应用程序和DBMS之间进行转换,因此这样一种方式是以牺牲效率为代价的。
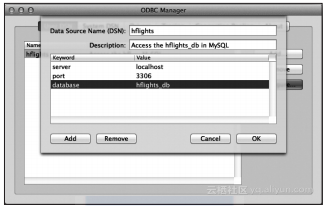
RODBC包提供了对类似这种功能的支持。开放数据库互联(Open Database Connectivity,ODBC)驱动能够支持大多数数据库系统,即使是CSV和Excel文件也没问题。RODBC包对任何安装了ODBC驱动的数据库都能够提供一种标准化的方式实现数据访问。作为一个与平台无关接口,它支持SQLite、MySQL、MariaDB、PostgreSQL、Oracle数据库、Microsoft SQL、Microsoft Access,以及Windows和Linux上的IBM DB2。下面简单使用一个样例进行说明,我们将先连接本地主机(或虚拟机)的MySQL。设置好数据源(Database Source Name DSN)的详细信息,包括:
数据库驱动
主机名或地址,端口号,也可以选择Unix socket
数据库名称
连接需要的用户名、口令
可以在安装好unixODBC程序后,在命令行编辑Linux上odbc.ini和odbcinst.ini两个文件完成。对于MySQL驱动,需要在/etc文件夹下增加如下配置信息:

odbc.ini文件包含了前面说的DSN配置信息,明确了数据库和服务器的名称:

也可以使用Mac OS或Windows上的图形编辑器,如下图所示:
当配置好DSN后,就可以在命令行里开始连接数据库:

让我们访问一下之前存放在数据库中的数据:

需要几秒钟的时间完成,这就是使用高层接口访问数据库实现操作的便捷性所付出的代价。如果要删除和更新数据也可以使用除了odbc*函数这种低层函数以外的类似的高层函数(例如sqlFetch)。例如:

读者可以使用同一查询命令来访问其他系统支持的数据库引擎,但要确保配置好每个后台的DSN,并且在执行完毕后记得关闭连接:
RJDBC包提供对Java数据库连接(JDBC)驱动的支持。
1.4.6 使用图形化用户面连接数据库
谈到高级接口,R的dbConnect包支持使用图形用户界面连接MySQL:
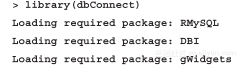

图形化操作不需要配置参数,就像一个简单的对话窗口一样
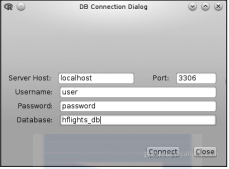
确定了连接内容后,我们可以很容易地浏览原始数据以及列的类型,同时执行特定的SQL查询。查询生成器可以帮助新手从数据库中获取需要的样本子集:
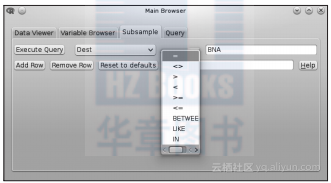
dbConnect包提供了一个实用的函数sqlToR,使用该函数我们可以将SQL的查询结果直接在GUI界面内转换为R对象。不过,dbConnect包对RMySQL存在严重的依赖性,这也就意味着只能在MySQL环境下使用该包,目前针对该接口也没有更进一步的升级计划。
1.4.7 其他数据库后台
除了前面讨论过的流行的数据库系统,我们还将在本节对其他一些数据库后台进行简单介绍。
例如,像MonetDB这样一类基于列的数据库管理系统,经常被用于支持高性能数据挖掘,这些数据库中可能存储了包含几百万行以上和数千列的大型数据集。R提供了MonetDB.R包对MonetDB数据库系统提供了多种支持,这也是2013年useR!会议的热门话题。
应用变得日益广泛的NoSQL系统也提供了类似的方法,不过它们不支持SQL,而是采用基于模式自由(schema-free)的数据存储方式。Apache Cassandra也是一个典型的面向列的高效的分布式数据库管理系统。RCassandra包支持基础Cassandra特性,用户也可以使用RC.*函数族使用Cassandra查询语言。HBase数据库引擎源于Google的Bigtable思想,由rhbase包支持,RHadoop部分项目可以在https://github.com/RevolutionAnalytics/RHadoop/wiki获得。
对于海量并行处理,HP的Vertica和Cloudera的开源Impala都能在R中进行访问,因此我们能够以比较好的性能实现对海量数据的查询。
MongoDB是最具代表性的NoSQL数据库,它提供了面向文本的类似JSON格式的数据存储方式,支持动态模式。对MongoDB的开发一直比较活跃,它也支持一些类SQL的功能,例如查询语言和索引等,目前有很多R包支持对MongoDB数据库后台的存取。例如,RMongo包使用的是mongo-java-driver,该包依赖Java,对数据库访问提供了比较高层的接口。还有rmongodb包,由MongoDB团队开发和维护,更新频率较高,文档也比较多,但是由于rmongodb提供了对原始MongoDB函数以及BSON对象的访问,而不是专注在面向一般R用户的转换层,因此RMongo反而与R的结合更加紧密。
CouchDB,我个人很喜欢适合无模式项目的数据库,支持JSON对象和HTTP API,实现了非常方便的文档存储。CouchDB很容易集成到诸如R Script等应用中,例如RCurl包,尽管你可能发现R4CouchDB与数据库交互的速度更快。
Google BigQuery也支持类似的基于REST的HTTP API,提供类SQL语言,实现了对驻留在谷歌基础设施上百万兆字节数据访问。CRAN目前还不提供对bigrquery的下载服务,但我们可以很容易地通过devtools包从GitHub上下载安装它,这两个包的作者都是Hadley Wickham:

如果要在Google BigQuery上测试该包的功能,读者可以注册一个免费账号,然后从谷歌获得demo数据集,每天支持的请求不超过10?000。请注意目前仅提供对数据库的只读访问。