Swarm Mode是Docker 1.12版开始推出的新功能,它将Docker Engine、swarm的集群管理和容器编排功能集成在一起,并新增了service概念及基于LVS的4层负载均衡功能(Routing Mesh)。
阿里云容器服务第一时间支持了Swarm Mode,并在上面做了很多功能扩充。这篇文章将介绍这些新功能以及它与旧Swarm集群的区别。
Swarm Mode简介
Swarm Mode集群的架构图如下图所示: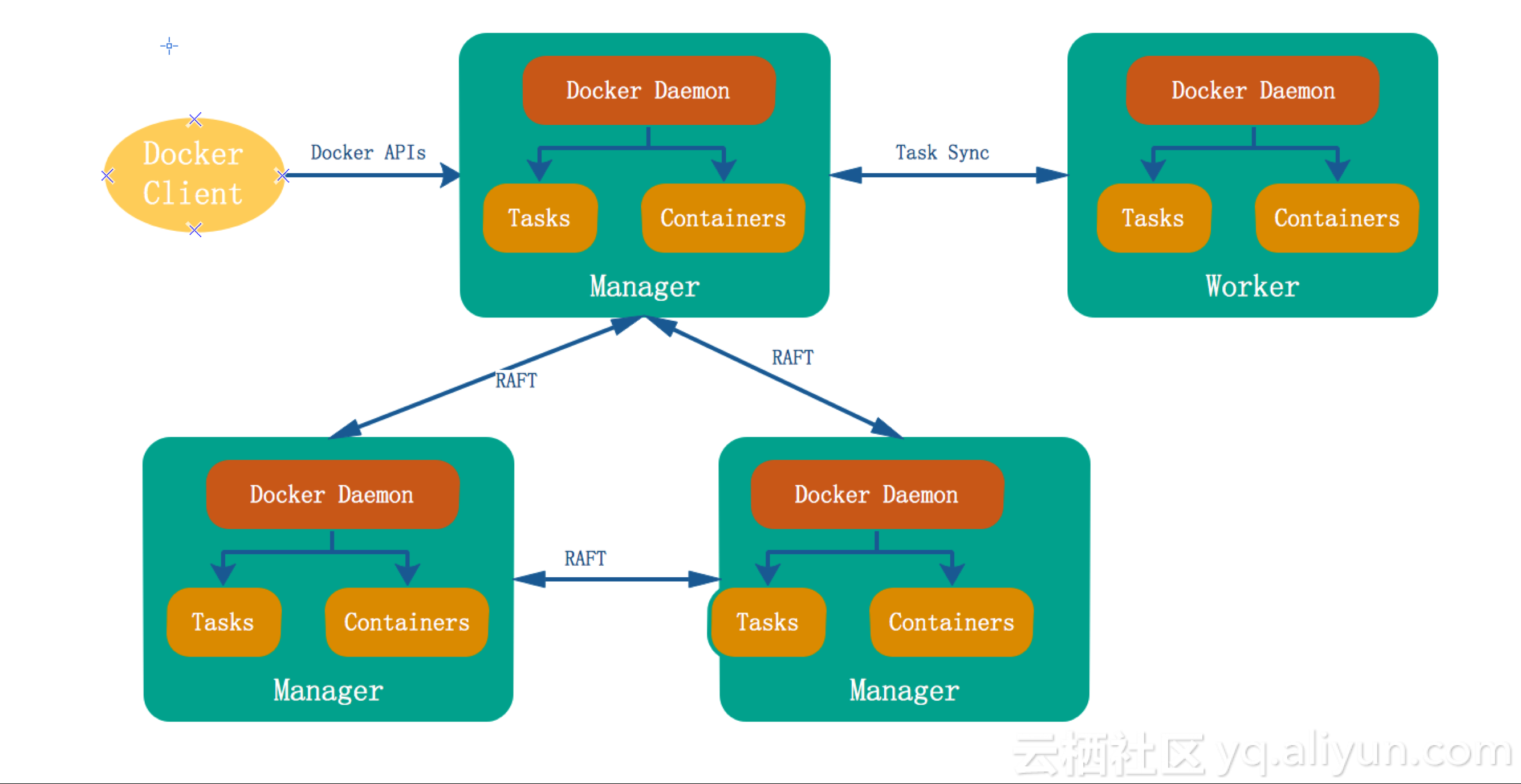
这个架构有以下一些特点:
- 无任何外部依赖。Manager之间通过Raft协议,组成一个分布式KVStore,替代了原Swarm中的etcd。
- Daemon身兼Engine、Manager、Agent三职
- Manager不直接发送命令给Worker的Daemon,只是同步Task信息
- 高可用架构,只需将Manager设置成>=3的奇数个
由于没有外部依赖,Swarm Mode集群的部署非常简单,只需要安装好DockerEngine,再设置好节点角色即可。
阿里云容器服务上的Swarm Mode集群
集群部署
部署Swarm Mode集群跟部署之前的Swarm集群没有什么差别,用户只需要在创建时选择集群类型即可,容器服务会自动完成docker安装、集群角色设置的工作。需要注意的是,为了实现高可用,集群至少需要有3个节点。
我们会默认设置3个Manager。当节点加入集群时,如果当前Manager数量不足3个,节点会被设置为Manager,否则会被设置为Worker。
这两种集群的差异主要有:
| Swarm集群 | SwarmMode集群 | |
|---|---|---|
| 管控 | 全部在容器服务内部,用户机器都是工作机。用户机器挂掉不影响集群。 | Manager在用户机器上,当健康的Manager机器少于两台时,集群无法工作。另外,重置Manager机器会丢失集群管控数据,相当于manager下线。 |
| 编排模板 | 支持compose V1、V2 | 支持compose V1、V2、V3,V1、V2是swarm应用,V3是swarm mode应用 |
| 容器启动参数 | 支持几乎docker run的所有参数 | 不支持privileged、host network、host pid等参数 |
| 修改应用配置 | 只有有变化的服务会被重启。 | 目前所有服务都会被重启,后续会改进成只重启有变化的服务。 |
| 健康检查 | 容器不健康时,只会从路由中摘掉容器 | 容器不健康时,会从路由中摘掉容器,同时重启容器 |
| 容器迁移 | 容器挂掉时,原地重启;或者配置reschedule环境变量,当机器掉线时迁移 | 自动保证服务的容器数量,数量不足时会重启或者迁移容器 |
| 有状态应用 | 更新容器时,继承原容器的数据卷,保证数据不丢失 | 更新容器时不继承数据卷,除非使用命名数据卷,否则数据会丢失 |
| 基于SLB的负载均衡 | 需要用户手工配置SLB的监听及后端机器;一个SLB只能绑定一个服务 | 自动配置SLB;一个SLB可以绑定多个服务 |
| 蓝绿发布 | 支持基于routing和SLB的蓝绿发布 | 只支持基于routing的蓝绿发布 |
应用部署
我们支持通过编排模板和交互界面两种方式来部署应用。
编排模板(compose)
Swarm Mode集群只支持compose v3和compose v3.1,其语法格式参见https://docs.docker.com/compose/compose-file/ 。
下面是一个简单的示例
version: "3.1"
services:
nginx:
image: nginx:latest
deploy:
mode: global
ports:
- 80:80
扩展功能
下面的表格列举了原Swarm集群上的扩展功能在Swarm Mode集群上的支持情况。
| 功能 | Swarm集群 | Swarm Mode集群 |
|---|---|---|
| 服务的健康检查 | aliyun.probe标签 | compose中的healthcheck一节。该功能由DockerEngine原生提供 |
| 滚动更新(rolling update) | aliyun.rolling_updates标签 | compose中的update_config一节。该功能由Swarm Mode原生提供,可设置更新的批量、间隔时间、失败后的动作等。 |
| 服务依赖 | aliyun.depends标签 | compose中的depends_on一节。服务会按照依赖关系顺序启动,默认等待3分钟,如果服务3分钟后依然没有达到运行状态,会忽略并继续部署其他服务,但最终部署结果是失败。 |
| 服务的容器数量 | aliyun.scale标签 | compose中的replicas一节。该功能对应于Swarm Mode的Replicated Service,当容器故障时,会自动创建新容器,始终保证replicas等于指定的数量。 |
| 全局服务 | aliyun.global标签 | compose中的mode一节。该功能对应于Swarm Mode的Global Service,当新节点加入集群里,会自动创建相应容器。 |
| 负载均衡 | aliyun.routing、aliyun.lb标签 | 参考下面的负载均衡一节。 |
| 日志 | aliyun.log_标签 | 没有变化。 |
| 数据卷 | compose的volumes一节 | 使用方法没有变化,但使用本地数据卷时,如果主机文件夹不存在,不会自动创建,需要用户手工创建。 |
| 监控与自动扩缩容 | aliyun.auto_scaling、aliyun.reschedule标签 | 没有变化。 |
| 外部服务 | compose的external一节 | 不支持。 |
| 容器重新调度 | 环境变量中的reschedule:on-node-failure | 默认提供,不需要设置。 |
| 高可用性调度 | 环境变量中的availability:az | 将在Docker CE 17.06 中的compose模板中支持Topology aware调度。 |
路由与负载均衡
原Swarm集群支持7层(aliyun.routing)和4层(aliyun.lb)路由,Swarm Mode集群也支持这两种模式,且语法不变,如下面的编排模板所示:
version: "3"
services:
nginx:
image: nginx:latest
ports:
- 80
deploy:
mode: replicated
replicas: 1
labels:
aliyun.routing.port_80: web
aliyun.lb.port_80: tcp://slbtest:8080
aliyun.routing.port_80: web:将web子域转发到nginx服务的80端口。这种模式下,不需要暴露容器端口到主机,即如果只用这种方式,上面模板中的ports一节可以省略。aliyun.lb.port_80: tcp://slbtest:8080:将slbtest这个SLB实例的8080端口绑定到nginx服务的80端口。老的Swarm集群,要求用户手工将slbtest的后端绑定一个端口,但Swarm Mode中不需要,我们会自动根据用户暴露的端口,自动修改slb的后端。另外,Swarm Mode中,同一集群的不同服务可以共享同一个SLB。