原文:人工神经网络简介和单层网络实现AND运算--AForge.NET框架的使用(五)
前面4篇文章说的是模糊系统,它不同于传统的值逻辑,理论基础是模糊数学,所以有些朋友看着有点迷糊,如果有兴趣建议参考相关书籍,我推荐《模糊数学教程》,国防工业出版社,讲的很全,而且很便宜(我买成7元钱)。
人工神经网络的简介
人工神经网络是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。它是一种运算模型,由大量神经元和相互的连接组成,每个神经元代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重(weight),用于模拟记忆。整个网络的输出则依网络的连接方式、权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
人工神经网络的优势很明显,主要体现在以下三个方面:
1.具有自学习功能
2.具有联想存储功能
3.具有高速寻找优化解的能力
更多知识请参阅相关资料
AForge.Net单层网络实现AND运算
AForge.Net中有关神经网络的实现主要在AForge.Neuro中,用install-package AForge.Neuro获取。

我们按照一般步骤来:
1.构建模型
AND运算的话不用多讲,整理一下输入输出:
[0,0] ===> [0]
[1,0] ===> [0]
[0,1] ===> [0]
[1,1] ===> [1]
可以很容易看出,输入是2个,输出是1个节点,层数单层足矣。
代码:
//整理输入输出数据 double[][] input = new double[4][]; double[][] output = new double[4][]; input[0] = new double[] { 0, 0 }; output[0] = new double[] { 0 }; input[1] = new double[] { 0, 1 }; output[1] = new double[] { 0 }; input[2] = new double[] { 1, 0 }; output[2] = new double[] { 0 }; input[3] = new double[] { 1, 1 }; output[3] = new double[] { 1 };
2.选择激励函数和学习规则
AForge.Net中的激励函数需实现IActivationFunction 接口,AForge.Net中实现了3种:
BipolarSigmoidFunction
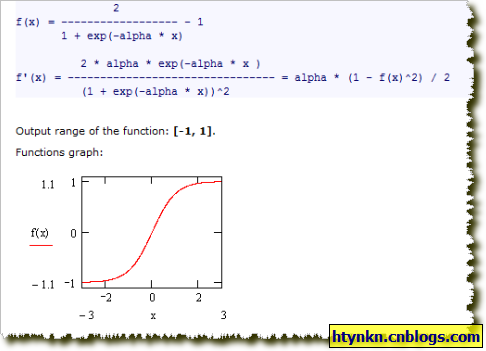
SigmoidFunction
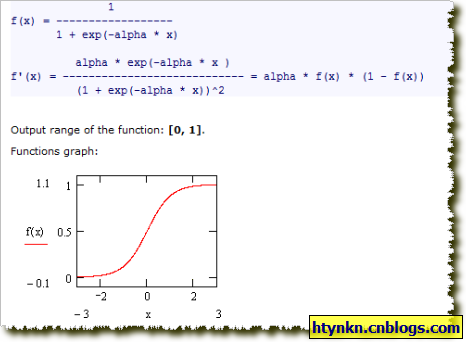
ThresholdFunction(阈函数)
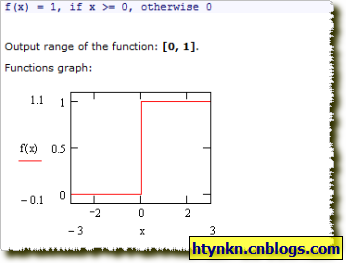
我们的激励函数(activation function)就选用阈函数了。
接下来考虑学习函数了。
AForge.Net中学习函数要实现ISupervisedLearning或者IUnsupervisedLearning接口,程序库实现了5种:
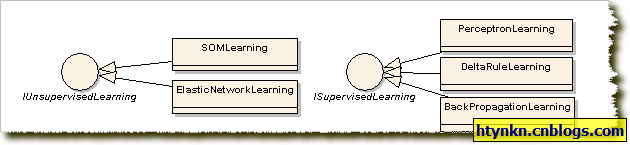
其中Perceptron Learning(感知学习)可以说是第一个神经网络的学习算法,它出现于1957年,常用于可线性分割的数据的分类。
代码:
//建立网络,层数1,输入2,输出1,激励函数阈函数 ActivationNetwork network = new ActivationNetwork(new ThresholdFunction(), 2, 1);
//学习方法为感知器学习算法 PerceptronLearning teacher = new PerceptronLearning(network);
3.训练网络
teacher.RunEpoch(input, output);
4.获取输出进行处理
因为本来就模拟算法,所以没有什么处理,我们模拟一下看效果就行了。
//模拟 for (int i = 0; i < 4; i++) { Console.WriteLine("input{0}: ===> {1},{2} sim{0}: ===> {3}", i, input[i][0], input[i][1], network.Compute(input[i])[0]); }
完整代码:
//整理输入输出数据 double[][] input = new double[4][]; double[][] output = new double[4][]; input[0] = new double[] { 0, 0 }; output[0] = new double[] { 0 }; input[1] = new double[] { 0, 1 }; output[1] = new double[] { 0 }; input[2] = new double[] { 1, 0 }; output[2] = new double[] { 0 }; input[3] = new double[] { 1, 1 }; output[3] = new double[] { 1 };
for (int i = 0; i < 4; i++) { Console.WriteLine("input{0}: ===> {1},{2} output{0}: ===> {3}",i,input[i][0],input[i][1],output[i][0]); }
//建立网络,层数1,输入2,输出1,激励函数阈函数 ActivationNetwork network = new ActivationNetwork(new ThresholdFunction(), 2, 1);
//学习方法为感知器学习算法 PerceptronLearning teacher = new PerceptronLearning(network);
//定义绝对误差 double error = 1.0; Console.WriteLine(); Console.WriteLine("learning error ===> {0}", error);
//输出学习速率 Console.WriteLine(); Console.WriteLine("learning rate ===> {0}",teacher.LearningRate);
//迭代次数 int iterations = 0; Console.WriteLine(); while (error > 0.001) { error = teacher.RunEpoch(input, output); Console.WriteLine("learning error ===> {0}", error); iterations++; } Console.WriteLine("iterations ===> {0}", iterations); Console.WriteLine(); Console.WriteLine("sim:");
//模拟 for (int i = 0; i < 4; i++) { Console.WriteLine("input{0}: ===> {1},{2} sim{0}: ===> {3}", i, input[i][0], input[i][1], network.Compute(input[i])[0]); }
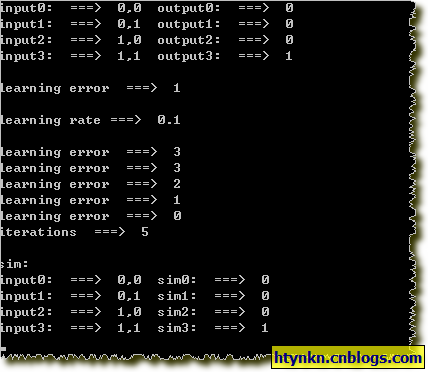
效果:
人工神经网络和模糊系统结合前景
我解释一下为什么说完模糊逻辑以后要说人工神经网络。虽然模糊逻辑和神经网络是两个截然不同的领域,它们的基础理论相差较远,一个是新模型,一个是新集合理论。但从客观实践和理论的溶合上讲是完全可以令它们结合的。把模糊逻辑和神经网络相结合就产生了—种新的技术领域:这就是模糊神经网络。
常见的形式有:
1.逻辑模糊神经网络
2.算术模糊神经网络
3.混合逻辑神经网络
我个人感觉二者的结合其实就是一个学习和优化权系数的问题。
对于逻辑模糊神经网络采用基于误差的学习算法,对于算术模糊神经系统一般用模糊BP算法,遗传算法。这两块的相关技术都比较成熟了。而对于混合逻辑神经网络,一般没有特定算法,而且多用于计算而非学习。
可能有朋友觉得前两种也是比较新的,我起初也是这样想的,但我检索了近十年的相关论文(从万方下的),大部分思想和方法都可以从诸如Cybernetics等杂志的早期数据中(1980年上下)找到。
最后附上3篇有关Perceptron Learning的资料:http://www.ctdisk.com/file/4525564