0.说明
模块是用来组织Python代码方法的方法,而包则是用来组织模块的,充分利用好包和模块将有利于开发出结构清晰的大型程序。
1.什么是模块
所谓模块,其实就是一个包含了特定功能代码的.py文件,在这个.py文件中,主要有如下的代码类型:
- 包含数据成员和方法的类
- 一组相关但彼此独立的操作函数
- 全局变量
使用import语句就可以导入一个模块中的相关属性。
2.模块和文件
模块是按照逻辑上来组织Python代码的方法,而体现在物理层面上,它就是一个文件,因此,一个文件被看作是一个独立模块,一个模块也可以被看作是一个文件。模块的文件名就是模块的名字加上扩展名.py。
与其他可以导入类的语言不同,在Python中导入的是模块或模块属性。
(1)模块名称空间
名称空间是Python非常重要的一个概念,所谓名称空间,其实指的是一个名称到对象的关系映射集合。可以因为每个模块都定义了它自己的唯一的名称空间,所以不同模块间不会出现名称交叉现象,通过句点属性的访问方式,即使两个模块里有相同名称的变量,由于模块名称的不同,也不会发生名称冲突。
(2)搜索路径和路径搜索
模块的导入(使用import语句)需要一个叫做“路径搜索”的过程,即在文件系统“预定义区域”中查找要导入的模块文件,而这些预定义区域其实是Python搜索路径的集合,这里需要注意下面两个概念:
- 路径搜索:指查找某个文件的操作,是动词
- 搜索路径:需要查找的一组目录,是名词
如果模块名称不在搜索路径中,就会触发ImportError异常:
|
1 2 3 4 |
|
而默认搜索路径是在编译或安装时指定的,可以在两个地方修改:
- 设置环境变量PYTHONPATH
- 在sys.path中添加搜索路径
启动Python解释器后,搜索路径会被保存在sys模块的sys.path变量中:
|
1 2 3 |
|
返回的是一个列表,第一个元素表示的是当前目录。可以通过向这个列表添加元素(使用append或insert)来增加搜索路径:
|
1 2 3 4 5 6 |
|
如果有多个相同的模块名称,Python解释器会使用沿着搜索路径顺序找到的第一个模块。
另外使用sys.modules可以找到当前导入了哪些模块和它们来自什么地方,如下:
|
1 2 |
|
可以看到,与sys.path不同,sys.modules返回的是一个字典,其中key为模块的名称,键值为模块的路径。
3.名称空间
名称空间是名称(标识符)到对象的映射,向名称空间添加名称的操作过程涉及绑定标识符到指定对象的操作,同时会给该对象的引用计数加1。主要有以下几种名称空间:
- 内建名称空间:由__builtins__模块中的名字构成,Python解释器启动时自动加载
- 全局名称空间:加载完内建名称空间后加载
- 局部名称空间:执行一个函数时会产生该名称空间,函数执行结束后就会释放
其中,关于__builtins__模块和__builtin__模块的区别,可以查看这篇博文:《Python中__builtin__和__builtins__的深入探讨》
(1)名称空间与变量作用域比较
名称空间是纯粹意义上的名字和对象的映射关系,而作用域指出了从用户代码的哪些物理位置可以访问到这些名字。其关系如下:
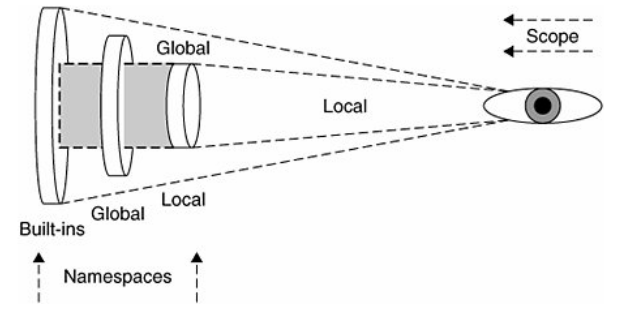
显然就很清晰了。
(2)名称查找、确定作用域、覆盖
访问一个属性时,解释器必须要在三个名称空间中的一个找到它,首先是局部名称空间,如果没有找到,则查找全局名称空间,如果还是查找失败,就查找内建名称空间,最后还是失败了,就会引发NameError异常。
显然上面的名称查找过程充分地体现了作用域覆盖的特性。
(3)无限制的名称空间
可函数中,可以通过func.attribute给函数添加属性属性,从而创建了另外一个名称空间,而在面向对象编程中,也可以通过类似的方式给一个实例,一个实例就是一个名称空间:
|
1 2 3 4 5 6 7 8 9 10 |
|
4.导入模块
(1)import语句
使用import语句可以导入模块,建议以这样的顺序导入模块:
- Python标准库模块
- Python第三方模块
- 应用程序自定义模块
解释器执行import语句时,如果在搜索路径中找到该模块,就会进行加载,该过程遵循下面的原则:
- 如果在一个模块的顶层导入,它的作用域是全局的
- 如果在函数中导入一个模块,它的作用域是局部的
- 如果模块是被第一次导入,它将加载并执行
对于最后一点,可以验证如下:
|
1 2 3 |
|
test模块中只有一个print语句,可以看到后面再次导入时并不执行该print语句。
(2)from-import语句
可以使用from-import语句导入指定的模块属性,即把指定名称导入到当前作用域(全局名称空间或局部名称空间,取决于导入的位置)中,语法如下:
|
1 |
|
当然,可以多行导入:
|
1 2 |
|
也可以使用from-import-as:
|
1 |
|
5.导入模块的特性
当模块被导入时,会有如下的特性:
- 载入时执行模块
加载模块会导致这个模块被“执行”,也就是被导入模块的顶层代码将直接被执行,这通常包括全局变量以及类和函数的声明,如果有检查__name__的操作,那么它也会被执行。
当然,应该把尽可能多的代码封装到函数,只把函数和模块定义放入模块的顶层是良好的模块编程习惯。
- 导入(import)和加载(load)
一个模块只被加载(执行)一次,无论它被导入多少次。前面已经有相应的例子。
- 导入到当前名称空间
即把模块的名称空间导入到当前作用域(全局名称空间或局部名称空间,取决于导入的位置),这样的话,如果当前作用域拥有相同名称的变量,就会被覆盖。
- 关于__future__
可以通过下面的导入语句使用Python的一些新特性:
|
1 |
|
- 警告框架
需要使用到时再查看相关文档。
- 从ZIP文件中导入模块
- “新的”导入钩子
6.模块内建函数
如下:
- __import__()
import语句实际上是调用了该函数,语法如下:
|
1 |
|
即可以这样来导入sys模块:
|
1 |
|
- globals()和locals()
使用globals()和locals()可以分别输出包含全局名称空间和局部名称空间的一个字典,只是在全局名称空间下,globals()和locals()的输出是相等的,因为这时的局部名称空间就是全局名称空间。
一个技巧是,可以通过这两个函数来调用全局或局部变量,在这开发中可能会用到,如下:
|
1 2 3 4 5 6 7 |
|
- reload()
使用reload()可以重新加载一个已经导入的模块,对于前面只有print语句的test模块,测试如下:
|
1 2 3 4 5 6 |
|
不过使用reload()时需要遵循下面的原则:
- 模块必须是全部导入,而不能是使用from-import
- reload()的参数是模块名字本身,而不是其字符串,即是reload(test)而不是reload('test')
7.包
包是一个有层次的文件目录结构,它定义了一个由模块和子包组成的Python应用程序执行环境。
(1)目录结构
有如下的包及其结构:
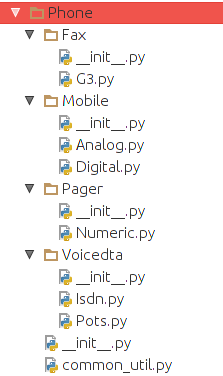
在包外运行Python交互器,则下面的导入方式都是可以的:
|
1 2 3 4 5 6 7 8 9 10 11 |
|
只是上面的导入方式其实都是绝对导入。
(2)__init__.py
只要是包,都必须包含__init__.py文件,否则只是一个普通的目录结构,而不是包,关于__init__.py,有如下特性:
- 导入一个包,实际上是导入这个包的__init__.py文件(模块)
对于上面的包结构,如果Phone/__init__.py的内容如下:
|
1 2 |
|
则导入Phone包时输出如下:
|
1 2 |
|
此时只是把Phone加入到当前名称空间中:
|
1 2 |
|
因为导入一个包实际上是导入这个包的__init__.py模块,所以,只要不在这个模块中的名称空间,都无法通过Phone来访问,即使已经导入了Phone:
|
1 2 3 4 5 6 7 8 |
|
因为上面的__init__.py模块中并没有Mobile和Pager这两个变量,即这两个变量不在其名称空间中,因为__init__.py中定义了一个packageName变量,所以可以通过Phone来访问:
|
1 2 |
|
- 在__init__.py中可以先导入一些模块或子包,使得可以通过上层包访问子包
上面的例子中,显然不能通过Phone来访问它的子包Mobile,现在可以在Phone/__init__.py中来先导入Phone的几个子包:
|
1 2 |
|
就可以通过Phone来访问了:
|
1 2 3 4 5 |
|
当然,如果想要访问子包下的模块,也是不行的,原因是一样的:
|
1 2 3 4 |
|
- 使用__all__变量来导入所有子包
如果需要使用from Package import *的方式来导入包下的所有模块,则需要定义__all__变量,实际上,该语句中的*表示的即是__all__列表中所包含的包名(或模块名)。
Phone/__init__.py内容如下:
|
1 2 3 |
|
使用from Package import *语句导入:
|
1 2 3 |
|
可以发现只有Fax,Pager,Voicedta这三个子包被导入了,但是Mobile这个子包并没有被导入,那是因为它不在__all__变量所定义的列表中。
(3)绝对导入与相对导入
使用下面的方式,都为绝对导入:
|
1 2 |
|
这时候,解释器会从sys.path定义的路径中去搜索需要导入的包或模块。当然,使用相对于当前路径的导入式的话有时候可以加快导入速度,相对导入可以使用下面的方式:
|
1 |
|
不过需要遵循下面的原则:
- 必须是使用from import语句
- from 关键字后面一定有句点标识.
- 只适用在包中
这三个原则都非常重要,尤其是最后一个,如果不清楚该原则的话,会导致错误使用相对导入从而带来不必要的各种纠结。
关于这一点,可以参考《Python cookbook》的相关内容:《10.3 使用相对路径名导入包中子模块》
8.模块的其他特性
(1)自动载入的模块
主要是__builtin__模块,它会正常地被载入,这和__builtins__模块相同。
(2)阻止属性导入
如果不想让某个模块属性被"from module import *"导入,那么可以给不想导入的属性名称加上一个下划线(_)。不过如果导入了整个模块,这个隐藏数据的方法就不适用了。
manage模块内容:
|
1 2 |
|
举例如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
|
(3)不区分大小的导入
主要取决于操作系统的文件系统是否区分大小写。
(4)源代码编码
在Python模块文件中,默认是使用ASCII编码,如果需要使用其他编码方法,比如Unicode编码,则可以在一个Python模块文件的开头这样写:
|
1 2 |
|
或者:
|
1 |
|
(5)导入循环
允许正确的导入循环,如果出现不能解决的导入循环问题,可以尝试在出现导入循环的两个模块中的一个模块中的import语句移到最后,或根据实际情况来进行解决。
(6)模块执行
可以执行一个Python模块,参考后面的内容。
9.相关模块
需要使用时参考相关文档即可。