
Summary: At the Alibaba Cloud MaxCompute session during the 2017 Computing Conference, Dai Xiening, Senior Technical Expert of Alibaba Cloud, shared the information about the index and optimization practices of MaxCompute. He started from the data models of MaxCompute, shared experience on Hash Clustering and Range Clustering, analyzed the index optimization and join optimization with examples of application, and finally made a brief summary.

The highlights of the speech are as follows:
MaxCompute serves as both a computing engine and storage engine. With 99% of the data of Alibaba stored on this platform, it has always been our goal to optimize storage efficiency and thus improve computational efficiency.
Data models of MaxCompute
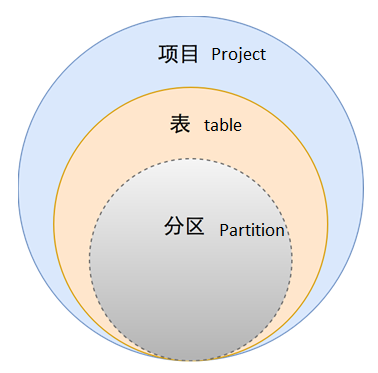
Now, the data models of MaxCompute include project, table, and partition. The data under the partition is stored disorderly where no data organization is defined.
So, can we improve the efficiency under the partition by defining data clustering, sorting, and index? The answer is yes.
MaxCompute 2.0 provides two clustering methods: Hash Clustering and Range Clustering.
Hash Clustering
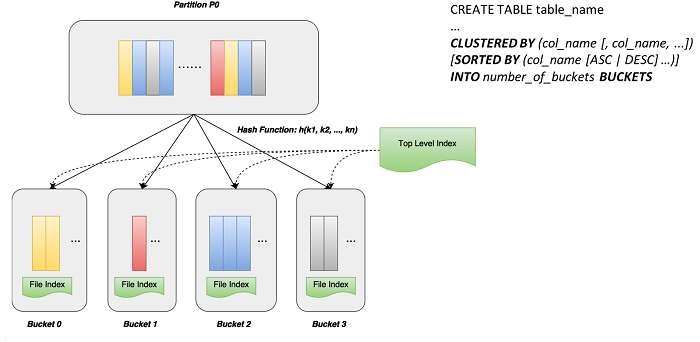
In Hash Clustering, users can specify several columns as the key chain in creating table. MaxCompute runs the hash function based on these columns, and stores the records with the same hash value in a cluster. The records with the same hash value are represented by different colors. Meanwhile, we define whether the clustering data is orderly or disorderly stored with syntaxes. For example, data is stored orderly if "sorted by" clause is specified. In this way, two results are produced: index is created in each file; and with top level index above the cluster, top level index defines the clustering number in the table, the detailed hash function, and the specified columns. All these help our later query.
Range Clustering
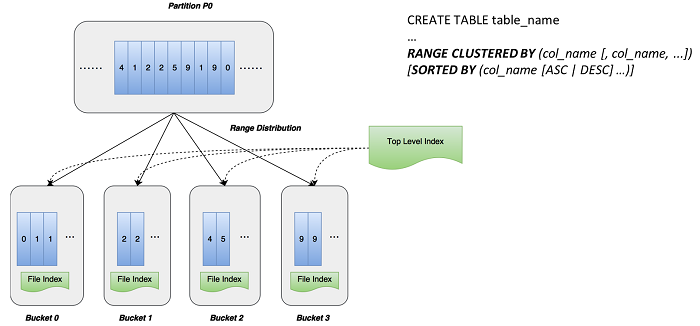
Range Clustering is more flexible and advanced than Hash Clustering. In Range Clustering, with Range Clustering columns specified, MaxCompute uses the "range clustered by" clause to sort all the files based on the value field of column. In addition, MaxCompute also clusters the files in a reasonable way to reduce data problems in parallel processing, considering the clustering principles such as cluster size and cluster difference rationalization. For example, we sort the nine records in the preceding figure and divide them into four clusters. With a "sorted by" clause specifying the data storage in each cluster, two levels of index are created after sorting: document level index and top level index. Top level index maintains each cluster, which corresponds to each range and interval.
Index-based query optimization
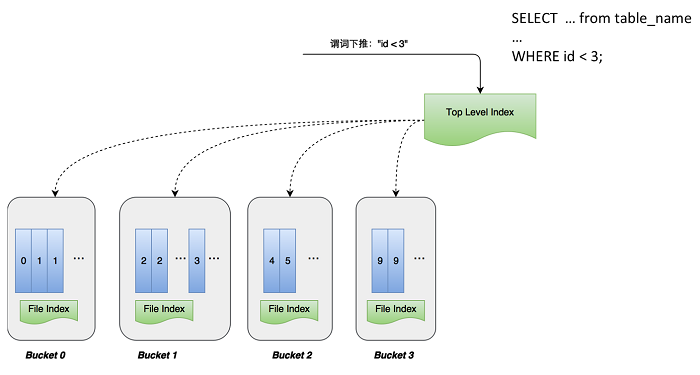
So, how to optimize it? For example, if I implement the data clustering and index sorting for the id column, the predicate is pushed down to the storage level. Using the predicate information as the filtering condition, a primary index with all cluster information is performed in top level index. Then, the query condition of id<3 filters Bucket 2 and Bucket 3. Besides, the predicate can be pushed down to the bottom of the file. Because bucket1 both has the values less than 3 and equal to 3, we can filter the data again in the file to further reduce the data amount. Before using the data cluster index, the query of id<3 needs to scan all the data in the table. Now, a huge amount of data can be filtered with index, so the efficiency is greatly improved.
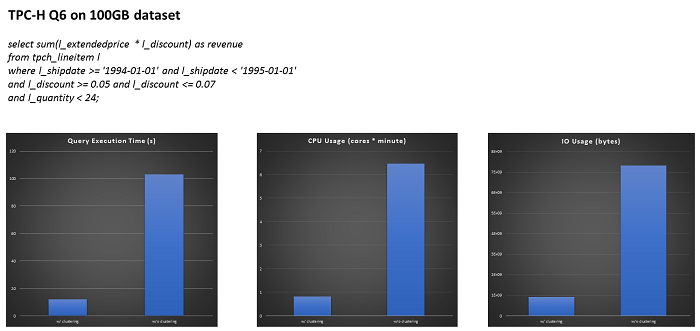
The preceding figure shows the TPC-H Q6 query. TPC-H is the standard test set in the database and big data field. According to the data achieving from the 100 GB test dataset, the left bar is the time with index and the right bar is the time without index. It clearly shows that the efficiency is increased by about ten times. With the help of index, the query execution time, CPU service time, and IO service time are decreased, and a lot of IO operations and data loading are reduced.
Join optimization
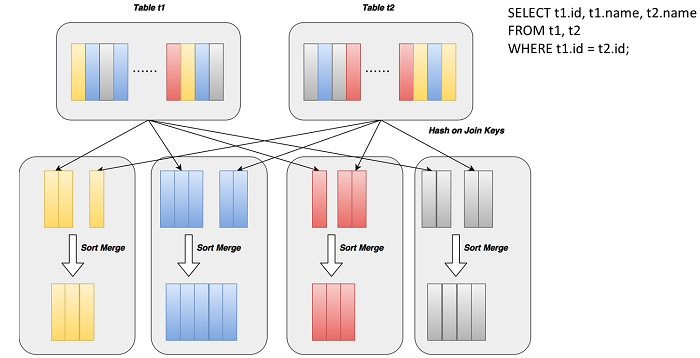
Besides the index applied to the filter, we also offer Join optimization. When performing sort merge join, you join the data of two data sources on one machine. Generally, you must use Hash function to divide the data sources into several clusters, so that records with the same join key are sorted into the same cluster and then the two data sources are sorted in each cluster. After sorting, you can perform merge join to find the data with the same key value. This process is complicated and time-consuming because you must run Hash function and write the data on one machine, and then transmit the data to another one to read it, for which twice disk I/O is needed. The whole process is called data shuffle.
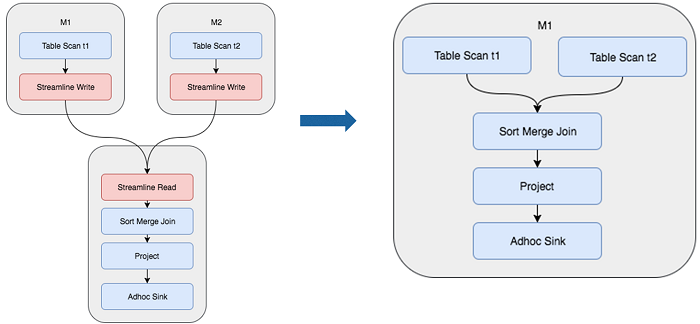
As what the figure shows, two table scans are loaded from the data disc and data shuffle is performed between streaming read and streaming write. If the data has been clustered and sorted and the data organization is stored in the disc, shuffle and sorting are not needed when performing join. This is the so called Join optimization. The process is shown in the preceding figure on the right. If M1 and M2 have performed sorting by the Hash Clustering, the plan is directly executed as shown in the preceding figure.
TPC-H Q4
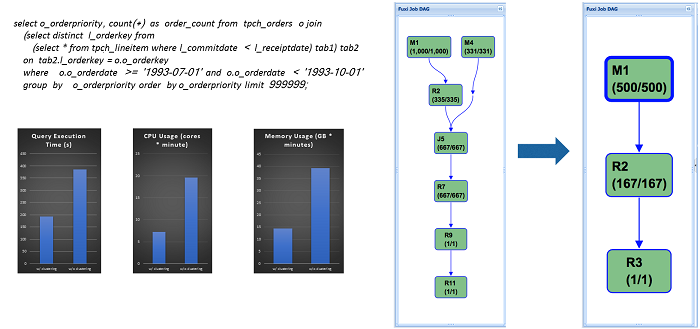
Before performing the Hash Clustering, the execution plan is showed in the preceding figure on the right. There are seven stages with multiple Join and Shuffle operations. If the table is changed as a Hash cluster table and the Hash Clustering is performed for the Join key, only three stages are necessary, thus simplifying the execution plan and doubling the efficiency.
Use cases
Query of transaction records on Taobao
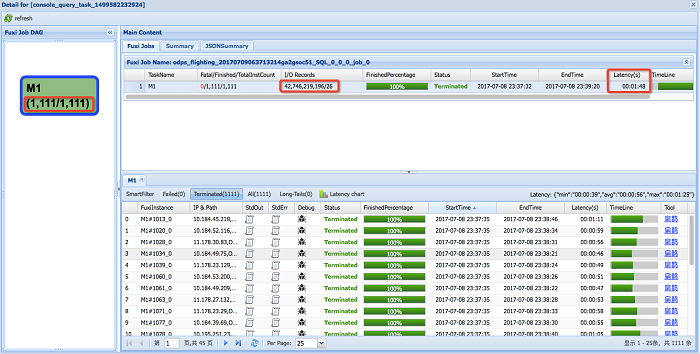
Given that there are tens of billions of or hundreds of billions of transaction records on Taobao, it is as difficult as finding a needle in a haystack to query the shopping records of a user in the last week with the user ID. The execution result on the system before the optimization is shown in the following figure. Over 1,000 workers scanned the table with more than 40 billion records and 26 records were found in 1 minute and 48 seconds.
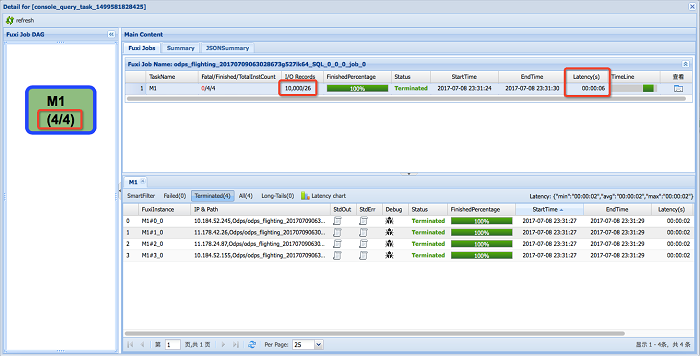
However, if we define the user ID as the primary key and sort the data by the Hash Clustering, the query is accomplished with only 4 Mappers scanning 10,000 records in 6 seconds.
Incremental upgrades of the transaction table of Taobao
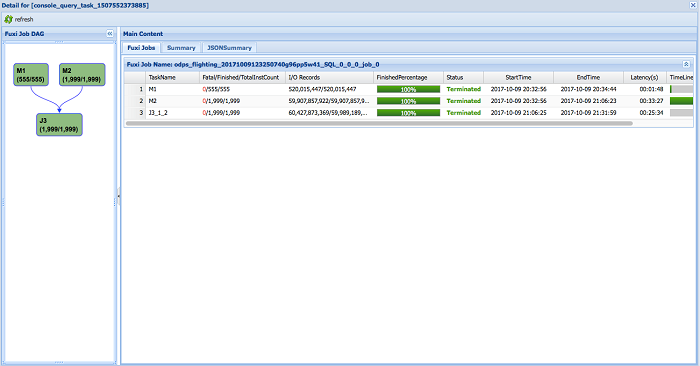
As the data source cited by many BUs of Alibaba, the core transaction table of Taobao must be as accurate as possible. There are incremental updates frequently, such as inserting or upgrading the increment data into the original table in a periodic manner. But it is rather time-consuming to shuffle the full table and the increment table in each update since the full table may contain large data volume with tens of billions of or even hundreds of billions of records, as compared to the incremental table with one tenth or one hundredth of the full table. When it comes to the shuffle of the full and increment table for M1 and M2 in the following figure, it took 1 minute and 49 seconds to shuffle the increment table and 33 minutes with 2,000 workers for the full one.
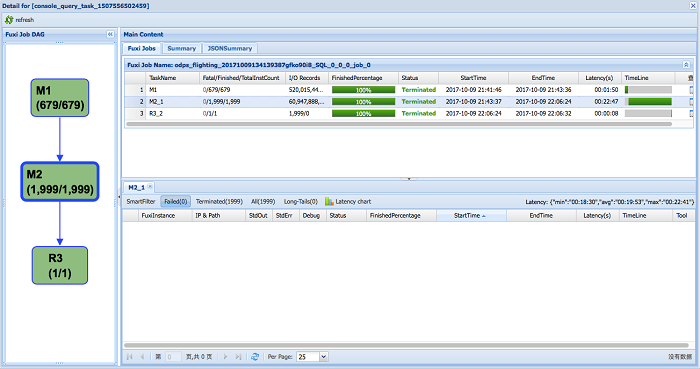
If the full table is sorted by the Hash clustering, you only need to shuffle the incremental table in each update, instead of shuffling the full table repeatedly. In this way, the Join running time is reduced from 60 minutes to 22 minutes.
Conclusion
● By using the data clustering, sorting, and index, MaxCompute can process data in a more efficient manner.
● The predicate push-down helps reduce the I/O of the table scanning and runtime filtering.
● The data clustering and sorting spares repeated Shuffle operations, simplifying the execution plan and saving both time and resources.