技术分享视频一
技术分享视频二
零点之战:双十一背后的分布式技术
共享业务的价值
- 数千应用、亿行Java代码、数十万运行实例
- 数千Java工程师与专家
- 24*7 服务亿级用户、每天数千万笔交易
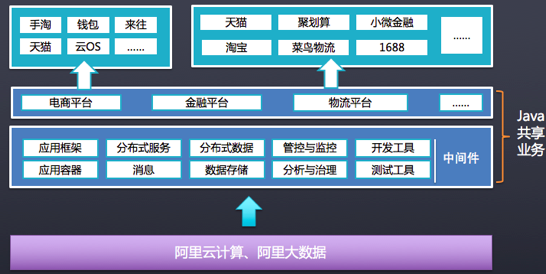
阿里电商分布式技术发展

阿里通过五彩石项目对淘宝和天猫进行了分布式化改造,将业务进行打通与拆分,形成共享服务。
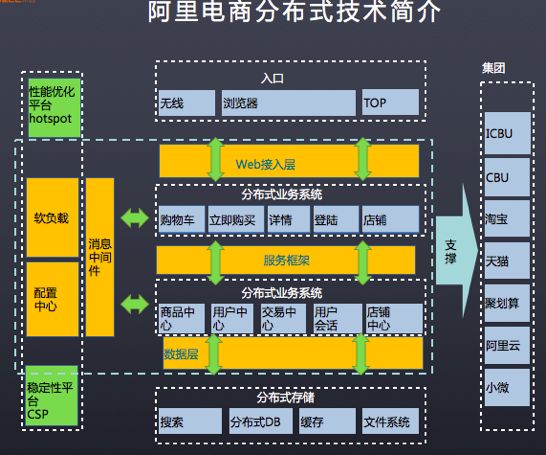
如上图所示,分布式的共享服务支撑着集团大量的业务,保证业务能提供优良的用户体验。
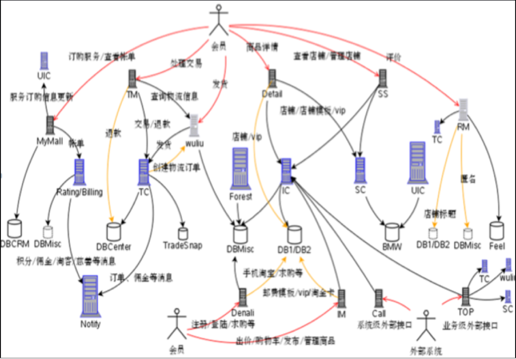
上图复杂的业务场景只是阿里电商业务的冰山一角。
双11的意义与挑战
双11大促的意义
- 日交易额从09年的5.9亿元狂飙至912亿,增长150倍
- 交易创建峰值从09年的400笔狂飙至14万笔,增长350倍
- 业务的狂欢,技术的盛宴
- 未来的技术储备,今年峰值是5年后的日常
- 全球最大交易场景零售体,用规模促进技术进步
双11大促的技术挑战
- 上百个系统用 n倍的服务器支撑m倍的流量
- 用户体验和资源投入的权衡,用合理的代价解决峰值
- 稳定性、扩展性、成本、效率、可运维
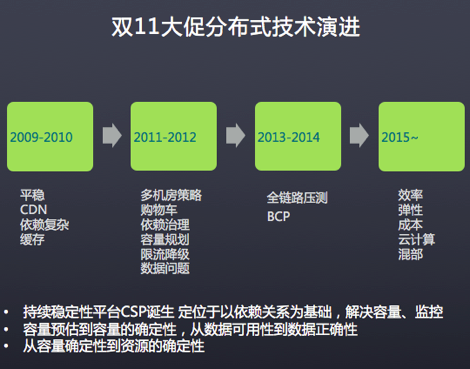
总结下每年双十一的关键词:
- 2009年:大促了么?2010年:CDN、带宽
- 2011年:商品打标、旺旺、降级 2012年:DB、超卖
- 2013年:无线、压测、单元化 2014年:安全、异地单元
- 2015年:异地多活、云化弹性架构
双十一带来的巨大流量推动中阿里分布式技术的发展,加速了技术的演进:
开放的技术文化
阿里是国内开源项目最多的公司,官方注册的开源项目303个,2015年新开源的项目65个。
具有众多高含金量的开源项目,点赞超过1000个的项目18个,社区大量参与的项目(fork超过100个)36个。
阿里有众多的Apache、Linux与XEN组织成员。
阿里参与社区开源的工程师超过300人。
有众多明星项目:
Jstorm并入到apache 顶级storm项目:
- Rocketmq在apache 中孵化
- fastjson Star 4,439 Fork 1,824
- tengine Star 4,019 Fork 1,182
- dubbo Star 3,631 Fork 3,761
阿里中间件性能挑战赛
阿里中间件技术部将双十一的场景开放出来,举办性能挑战赛,让大家来挑战双十一实时计算。
大赛提供了丰厚的奖励与硅谷游学基金,优秀选手将入围阿里校招绿色通道。
更有四位泰斗级导师坐镇,提供专业的指导服务。
部门介绍
阿里中间件技术部,是国内为数不多的极具技术挑战性的团队之一,依托于全球规模最大的阿里巴巴电子商务平台所带来的巨大流量和海量数据,以及对于电子商务平台固有的稳定性要求,使得团队有机会去面对一个又一个技术难题,创造一个又一个技术奇迹。在刚刚过去的“2016双十一网购狂欢节”中,912.17亿元销售奇迹背后的每一笔交易订单都和阿里中间件团队的技术小二们息息相关。
中间件技术部开发了一系列产品,支撑起了阿里整个集团的业务。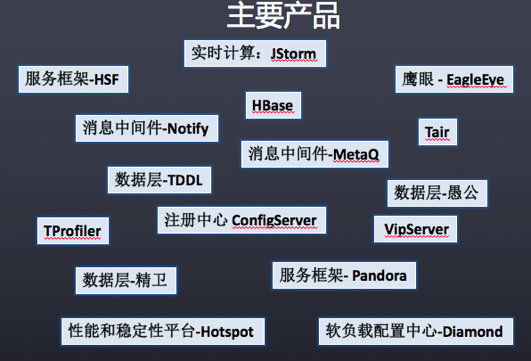
赛题与赛制介绍
这次大赛的技术背景主要有两个。一是实时计算,二是NoSql数据库。
- 实时计算,针对海量数据进行的,除了像非实时计算的需求(如计算结果准确)以外,实时计算最重要的一个需求是能够实时响应计算结果,开源社区比较火热的实时计算流式框架: Storm/Spark Streaming/Flink。
- NoSql数据库
- 支持单表PB级别海量数据的非关系型数据库,不受关系型数据库的Schema限制随意拓展,一般具有高可用、高性能、低成本、支持水平拓展等特性。
- NoSql数据库在阿里内部发展迅速,是OLAP领域数据存储的支柱
- 开源产品:HBase/MongoDB/Redis等。
业务背景如下图所示: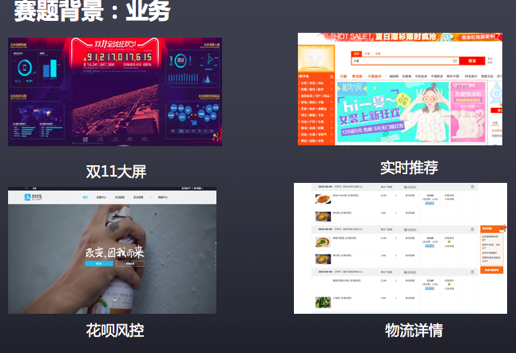
初赛赛题介绍
赛题:模拟实时统计阿里双十一交易数据
选手利用JStorm从RocketMQ拉取数据,按照要求实时计算出每分钟的统计结果,并将结果实时写入Tair。需要计算值如下:
- 每分钟淘宝/天猫交易额
- 每个整分时刻,无线和PC端历史总交易额的比值
比如计算2015/11/11 11:11:00整分时刻的交易比值,那么需要统计从交易开始时间到2015/11/11 11:12:00(不包含该时刻)这一区间内所有的交易值,来计算该整分时刻无线和PC端的比值。
数据构造:
- 对交易数据进行脱敏处理,对相应字段进行了刷选和整理,随机抽取
百万级别数据,按照一定的数据格式导入RocketMQ - 在RocketMQ中已经堆积好了两种消息,一种是订单消息,一种是支付
消息,一条订单消息可能对应多条支付消息 - 两种消息,堆积在三个Topic里面,付款消息堆积在付款Topic,来自天猫的订单消息堆积在天猫订单Topic里,来自淘宝的订单消息堆积在淘宝订单Topic里。
数据格式:订单消息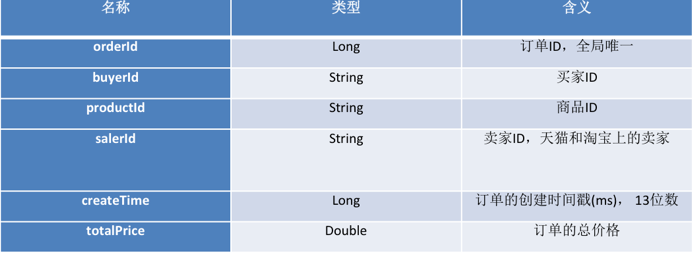
天猫订单Topic和淘宝订单Topic,都是这样的消息结构。
数据格式:支付消息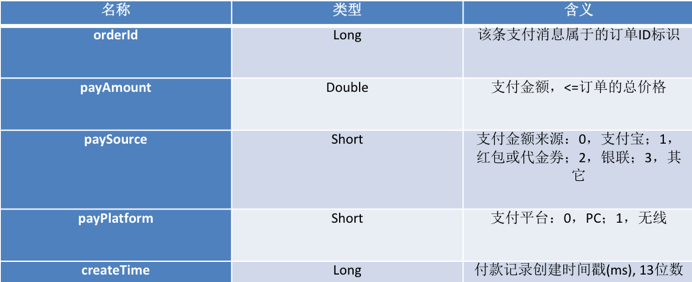
一个订单可能分为多次付款,对应多条付款消息,且产生的时间不一致,比如一般来讲来自银行部分的金额比来自支付宝的金额晚到账。赛题中指定的交易时间指的是支付消息的付款时间。
数据的导出和写入:
消息经过kryo序列化事先导入到RocketMq中,选手只要按照定义的数据格式,从Mq中拉取消息,kryo反序列出自己定义的对象,即可。
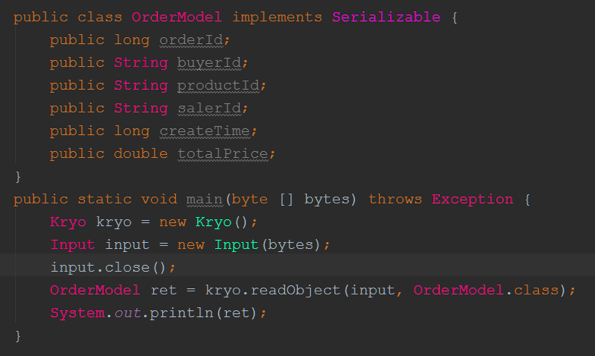
Tair 存储的是key-value 的结构,key字符串格式, value是number类型。
我们约定key 统一以“固定前缀_整分时间戳”方式命名的字符串,整分时间戳就是整分时刻对应的时间戳,可以表示该一分钟,例2015/11/11 08:11:00分钟对应的时间戳为1447200660(10位数),可表示2015/11/11 08:11:00 ~ 2015/11/11 08:12:00(不包含该时刻)这一分钟。

评判标准
针对两个维度进行评判:
(1) 平均准确度:对每个整分时刻的统计值进行验证,计算每一个统计值的准确度,然后求平均值,得到的就是平均准确度。
(2) 平均耗时:每个统计值的耗时是指从拓扑开始提交,到把这一统值写入Tair这一时段的时长。我们会计算出每个统计值的耗时,求平均值,得到的就是平均耗时。
优先根据平均准确度对各支队伍进行排名,准确度越高的,排名靠前;准确度一样的再根据平均耗时排名,耗时越短的队伍排名靠前。比赛周期每天给出的排名都是根据每只队列历史最优的成绩进行排名的。
初赛环境
备注:集群用容器隔离,可以保证每个拓扑运行间资源相互独立不受影响,同时限制每个拓扑最大可利用Worker数量不超过5个
复赛赛题介绍
赛题:交易订单查询
天猫与淘宝上每天产生了大量的交易订单,这些订单信息需要和其他信息做聚合,提供给各方进行查询。您的挑战是,如何将这些信息组织起来,构建一个简单的查询系统。
数据介绍:
- 为了保证数据安全,赛题数据使用系统产生的模拟交易数据
- 一共有三种类型的数据文件,交易信息,买家信息,商品信息。
文件的每行包含一条记录,记录中包含若干属性列。
他们通过交易ID,买家ID,卖家ID,商品ID相关联。可以通过类似关系型数据库中join的方式联系在一起 - 数据文件中的记录之间不保证顺序
- 数据非常大量,内存肯定放不下

查询方法:
- 提供交易ID,查询某次交易的某些属性。查询的属性可能不在交易信息中,需要到商品信息或买家信息中查询
- 查询某位买家某个时间范围内的所有交易信息。输出结果按交易ID排序
- 对某位卖家某个商品的所有交易信息进行求和,比如查询某个卖家商品的折扣券金额总和或总销售额
- 查询某位卖家某个商品的所有交易ID及其收货地址
评分标准: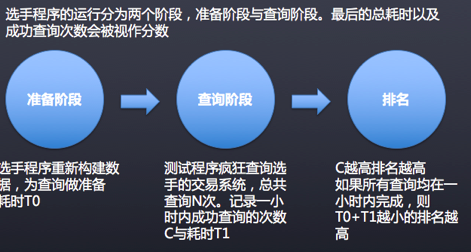
评测环境:
比赛流程
首先进行报名,熟悉比赛产品,并线下测试。
上传代码到 https://code.aliyun.com/,并上传打包脚本,具体规则关注比赛页面。
根据历史最优成绩,每天更新排名。
决赛流程:
1、材料准备:参与答辩队伍需提前准备评审材料,包括PPT材料、代码;
2、评审会:将以现场答辩会的形式进行,具体安排另行通知;
3、最终排名:组委会将根据参赛队伍的代码、历史成绩、评委打分,角逐出冠亚季军,颁发奖金及证书。
参赛规则
参赛对象
面向全社会开放,高等院校、科研单位、互联网企业等人员均可报名参赛。
注:大赛主办和技术支持单位如有机会接触赛题背景业务、产品、数据的员工,则自动退出比赛,放弃参赛资格。
组队规则
参赛队伍可以是单人组队,或者自由组合,但是最多不超过三人。
登陆 tianchi.aliyun.com,立即报名参赛!