创建表的时候,可以设置普通列和分区列。在绝大多数情况下,可以把普通列理解成数据文件的数据,而分区列可以理解成文件系统的目录。所以表的存储空间的占用,讲的是普通列的空间占用。分区列虽然不直接存储数据,但是如同文件系统里的目录,可以起到方便数据管理,并在计算只指定具体的分区的时候,只查询对应分区减少计算量的作用。
分区列的设置
创建分区表的语法可以参考这里。这里分别举2个例子方便理解: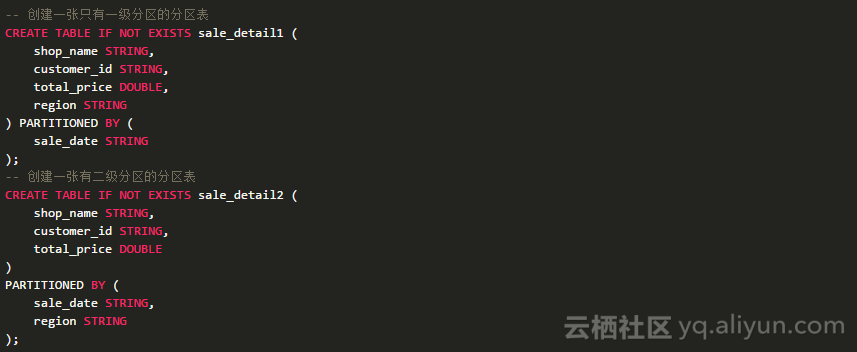
从这里可以看到分区表的创建方式。目前分区列只支持STRING类型。BIGINT目前是还在测试中,并无法保证其计算准确性,暂时还不建议大家使用。
目前分区表的分区列的个数不能超过6级,也可以理解成底层存储数据的目录层数不能超过6层。
分区的创建
关于分区和分区键的区别,可以先参考这个说明。对应到前面的说明,分区键的设置只是设置了一个规范,定义了表下的文件存储的目录规则需要是ds='xxx'。然后分区ds='20150101'对应一个目录,分区ds='20150102'对应到另外一个目录。
分区的作用
分区的作用主要有2部分。其一是能方便数据的管理。使用了分区后,一张表的数据被分到多个不同的分区里。比如日志表如果我们根据日期(天)进行分区,那么每个分区里都是单独一天的数据。如果有一天我们希望能归档历史数据到某个地方,或者删除过旧的数据,就只需要处理对应的分区即可。在这里还需要提一下Lifecycle设置生命周期的功能,可以设置数据的过期时间,单位为天。MaxCompute 会根据每张表的LastDataModifiedTime以及Lifecycle的设置来判断是否要回收此表。如果这张表是分区表,则根据各分区的LastDataModifiedTime判断该分区是否该被回收。所以假如设置了过期时间是100天,然后数据是每天同步到一个分区里,历史分区的数据写入后不再修改追加(LastDataModifiedTime不变),那么100天之前的历史数据会被自动删除,减少运维成本。
但是更加有意义的是,如果计算中使用方法得当,分区表参与计算的时候能只从指定的分区里读取数据作为输入,从而能减少计算量,缩短计算时间,还能减少费用。以下是一个典型的例子:ods_oplog表里有我模拟的2天(20161113、20161114)的日志(一共5条),ds作为分区。假如我的这次计算只需要20161113的数据,我们可以用SQL: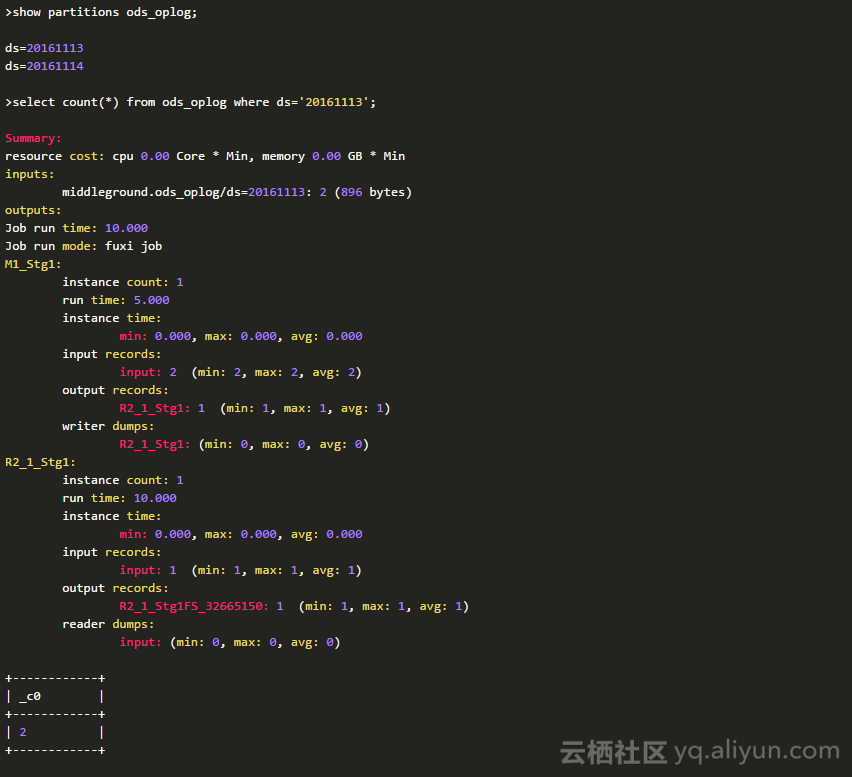
从这个SQL的执行计划和最后的结果来看,虽然表里有2个分区,但是因为使用了where ds='20161113',所以查询的时候只用到了ds='20161113'一个分区的数据,剩下的数据没有做为input参与计算。
使用限制
分区虽然好,但是也不能滥用。目前对分区主要有2个限制。首先是单个表的分区个数上限目前是6万个。其次是单次查询做执行计划解析的时候,查的分区数不能大于1万,否则会报这个错。对于这个问题,需要在设计表结构的时候,不要使用诸如用户ID一类的字段做分区列,否则一旦需要做全表查询的时候就可能报错了。
目前还有一个问题,如果查询只根据二级分区进行过滤,因为没有指定一级分区所以会扫描所有一级分区,也一样可能会出现这个错误。
SQL
关于SQL里查询条件怎么使用到分区带来的好处,前面的分区的例子其实已经提到了。只是需要注意的是,目前分区列需要是STRING类型,所以SQL里要写成ds='20161113'不要写成ds=20161113以避免自动类型转换后得到预期外的结果。
对于分区表,数据写入的时候需要指定数据写入的分区,用文档里的例子:
insert overwrite table sale_detail_insert partition (sale_date='2013', region='china')
select customer_id, shop_name, total_price from sale_detail;
再对应到前面提到的文件和目录的说法,因为数据的目录不存放具体的数据,只需要指定数据具体写到哪个目录后,把普通列的数据select出来后写入到表里就可以了。
但是确实有一些场景,需要把查询结果,根据某个字段的值,智能得写入到对应的分区里,那就需要用到动态分区,具体的语法可以参考
create table total_revenues (revenue bigint) partitioned by (region string);
insert overwrite table total_revenues partition(region)
select total_price as revenue, region
from sale_detail;
以上两功能的详细说明都可以参考文档。
JAVA
在JAVA里,分区的对应的就是com.aliyun.odps.PartitionSpec了。这个类有2个构造,除了无参构造,还有一个传入字符串的。
public PartitionSpec(String spec)
通过字符串构造此类对象
参数:
spec - 分区定义字符串,比如: pt='1',ds='2'
这是一个实际使用,需要传入PartitionSpec 的例子(使用SDK创建一个新的分区)
Account account = new AliyunAccount(accessId, accessKey);
Odps odps = new Odps(account);
odps.setEndpoint(endpoint);
odps.setDefaultProject(project);
Tables ts = odps.tables();
Table t = ts.get("p2");
String partition = "area='CN',pdate='20160101'";
PartitionSpec partitionSpec = new PartitionSpec(partition);
t.createPartition(partitionSpec);