2.3.1 HDFS常用命令hdfs dfs
在讲解这个命令前,先对hdfs dfs、hadoop fs、hadoop dfs这3个命令进行区分。
- hadoop fs:通用的文件系统命令,针对任何系统,比如本地文件、HDFS文件、HFTP文件、S3文件系统等。
- hadoop dfs:特定针对HDFS的文件系统的相关操作,但是已经不推荐使用。
- hdfs dfs:与hadoop dfs类似,同样是针对HDFS文件系统的操作,官方推荐使用。
该命令的操作在代码清单2-18中列出。
代码清单2-18 hdfs dfs命令
[root@master hadoop-2.6.0]# bin/hdfs dfs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] <path> ...]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-usage [cmd ...]]
其中斜体加粗的命令是比较常用的,一般可以根据命令名称推断出该命令的功能及用法。同时,也可以使用-usage命令查看某个具体名,如代码清单2-19所示。
代码清单2-19 hdfs dfs –usage用法
[root@master hadoop-2.6.0]# bin/hdfs dfs -usage put
Usage: hadoop fs [generic options] -put [-f] [-p] [-l] <localsrc> ... <dst>
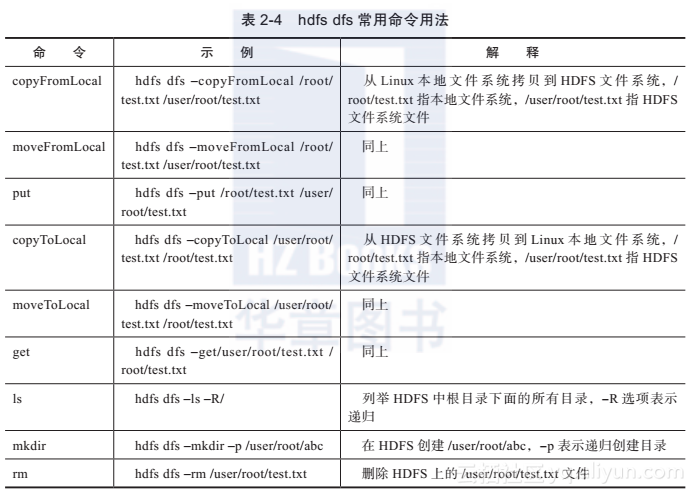
这里,针对常用的命令做简单介绍,如表2-4所示。
时间: 2024-11-03 17:51:26