在过去的几年间,数据科学这个概念已经被非常多的行业所接受。数据科学(源自于一个科学研究课题)最早是来自于一些试图去理解人类的智能并创造人工智能的科学家,但现在它已经被证明是完全可以带来真正的商业价值。
例如,我所在的公司:Zalando(欧洲最大的时尚品零售店)。在这里,数据科学和其他工具一起被用来提供数据驱动的推荐。推荐本身作为后端服务,被提供给很多地方,包括产品页面、分类目录页面、通讯电邮以及重新定位目标客户等。
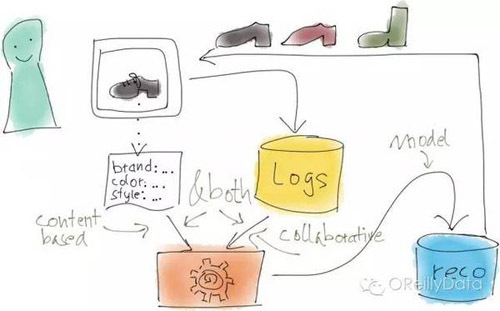
图1:图片来自Mikio Braun的演讲页
数据驱动产生推荐
实际上,有非常多的方法可以由数据驱动产生推荐。例如,在所谓的“协同过滤”里,所有用户的行为(比如浏览商品、对想买商品列表的操作、以及购买行为)都可以被收集起来作为推荐的基础,然后分析发现哪些商品有相似的用户行为模式。这种方法的优美之处在于计算机根本不用知道这些商品是什么。而它的缺点则是商品必须要有足够多的用户行为信息数据才能保证这个方法起作用。
另外一类产生推荐的方法是只看商品的属性。例如,推荐具有相同品牌的或者相同颜色的商品。当然,对这些方法还有非常多的扩展或者组合。

图2:图片由Antonio Freno友情提供并授权使用。引用自发表在KDD 2015会议的《One-Pass Ranking Models for Low-Latency Product Recommendations》论文
更简单一些的方法就是只通过计数来做推荐。但这种方法在实践里会有非常多的复杂的变形。例如,对个性化推荐,我们曾使用过“学习排序”的方法,即对商品集做个性化的排序。上图里所显示的就是这个方法需要最小化的损失函数。
不过,这里画出这个图的主要目的,还是来展示数据科学可能会引入的复杂度。这个函数自身使用了成对的加权指标,并带有正则化条件。这个函数的数学展现是很简化的,当然也就很抽象。这个方法不仅对于电商的推荐场景有用,还对当物品有足够特征的时候的所有类型的排序问题也有用。
将数据科学方法引入工业界
为了把类似上图的非常复杂的数学算法引入到生产系统中,我们需要做什么?数据科学和软件工程之间的界面应该是什么样?什么样的组织架构和队伍结构才最适合使用这些数据科学的方法?这些都是非常相关和合理的问题。因为这些问题的答案将会决定对于一个数据科学家或者是整个数据科学团队的投资是否能最终得到回报。
在下文里,我会根据我作为一个机器学习的研究人员以及在Zalando带领一个数据科学家和工程师团队的经验,来对这些问题做一些探讨。
理解数据科学(系统)与生产系统的关系
让我首先从了解数据科学系统与后端生产系统的关系开始,看看如果将两者进行集成。
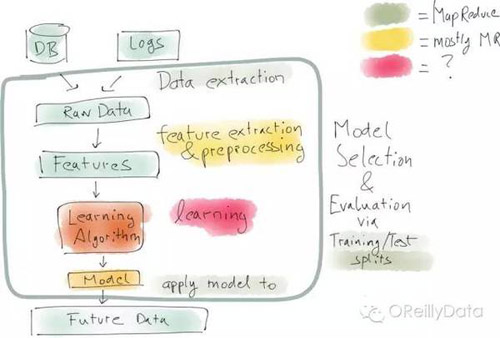
图3:图片来自Mikio Braun的演讲页
典型的数据科学工作流程(管道)如上图里所示:第一步总是从发现问题和收集一些数据(来自于数据库或者生产系统的日志)开始。取决于机构的数据准备好的程度,这一步有可能就是很困难的。首先,你有可能需要搞清楚谁能让你接触到所需的数据,并搞清楚谁能给你权限去使用这个数据。当数据可用后,它们就可能需要被再次处理,以便提取特征值。你希望这些特征可以为解决问题提供有用的信息。接着,这些特征值被导入学习的算法,并用测试数据对产生的结果模型做评估,以决定这个模型是否能较好地对新数据做预测。
上述的这个分析管道通常都是短期一次性的工作。一般是由数据科学家手工完成所有的步骤。数据科学家可能会用到如Python这样的编程语言,并包括很多的数据分析和可视化的库。取决于数据数量,有时候数据科学家也使用类似Spark和Hadoop这样的计算框架。但一般他们在一开始都只会使用整个数据集的一小部分来做分析。
为什么开始只用一小部分数据
开始只用一小部分数据的主要原因是:整个分析管道过程并不是一锤子买卖,而是非常多次反复迭代的过程。数据科学项目从本质上讲是探索性的,甚至在某种程度上是开放式的命题。虽然项目目标很清楚,但什么数据可用,或可用的数据是否适合分析,这些在项目一开始都不是很清楚。毕竟,选择机器学习作为方法就已经意味着不能仅仅只是通过写代码来解决问题。而是要诉诸于数据驱动的方法。
这些特点都意味着上述的分析管道是迭代的,并需要有多次改进,尝试不同的特征、不同的预处理模式、不同的学习方法,甚至是重回起点并寻找和实验更多的数据来源。
这整个过程本质上就是反复的,而且经常是高度探索性的。当做出的模型的整体的表现不错后,数据科学家就会对真实的数据运用开发的分析管道。到这时,我们就会面临与生成系统的集成问题。
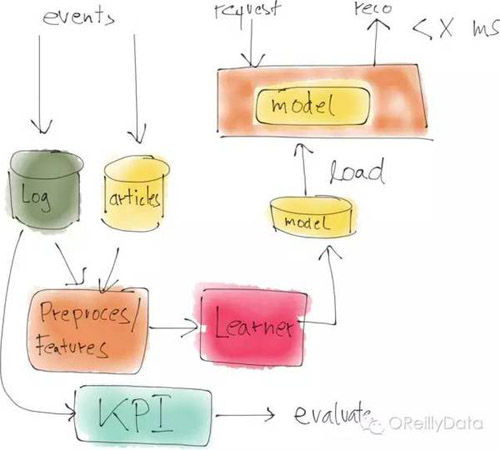
图4:图片来自Mikio Braun的演讲页
区分生产系统和数据科学系统
生产系统和一个数据科学系统的最主要区别就是生产系统是一个实时地、在持续运行的系统。数据一定要被处理而模型必须是经常更新的。产生的事件也通常会被用来计算关键业务性能指标,比如点击率等。而模型则通常会每隔几个小时就被用新数据再进行训练,然后再导入生产系统中去服务于新来的(例如通过REST接口送入的)数据。
这些生产系统一般都是用如Java这样的编程语言写的,可以支持高性能和高可靠性。
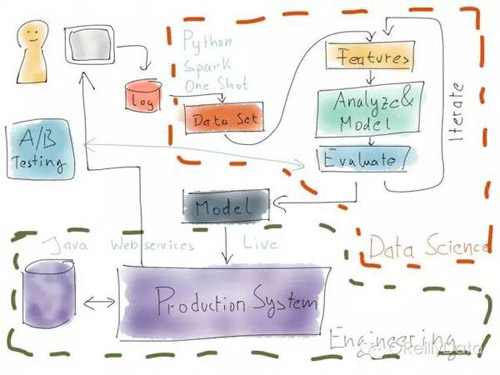
图5:图片来自Mikio Braun的演讲页
如果你把生产系统和数据科学系统并排放置,那么就会得到一个类似上图的情况。在右上角,是数据科学的部分。其典型特征是使用类似Python的语音或者是Spark的系统,但一般是一次性的手工触发的计算任务,并经过迭代来优化整个系统。它的产出就是一个模型,本质上就是一堆学习到的数字。这个模型随后被导入进生成系统。而生产系统则是一个典型的企业应用系统,用诸如Java语言写成的,并持续运行。
当然,上面的这个图有一些简化了。现实中,模型都是需要被重新训练的,所以一些版本的数据处理管道会和生成系统集成在一起,以便不时地更新生产系统里的模型。
请注意那个在生成系统里运行的A/B测试。它对应于数据科学一侧的评估部分。但这两部分经常并不完全具有可比性。例如不把离线的推荐结果展示给客户,就很难去模拟一个推荐的效果,但有这样做可能会带来性能的提升。
最后,必须要意识到,这个系统并不是在安装部署完成后就“万事大吉了”。就如数据科学侧的人需要迭代多次来优化数据分析管道,整个实时系统也必须随着数据分布漂移来做迭代演进。由此新的数据分析任务就成为可能。对我而言,能正确做好这个“外部迭代”是对生产系统的最大的挑战,同时也是最重要的一步。因为这将决定你能否持续地改善生产系统,并确保你在数据科学上的初期投资取得回报。
数据科学家和程序员:合作的模式
到目前为止,我们主要关注的是生产环境里的系统是什么样。当然对于如何保证生产系统稳定和高效则有很多种方法。有时候,直接部署Python写的模型就足够了,但生产系统和探索分析部分的分离是肯定存在的。
你将会面对的艰巨挑战之一,就是如何协调数据科学家与程序员的合作。“数据科学家”依然是一个新的角色,但他们所做的工作与典型的程序员有着明显差异。由此导致的误解和沟通障碍就不可避免了。
数据科学家的工作通常是探索性的。数据科学项目一般始于一个模糊的目标、哪些数据可用的一些想法、以及可能的算法。但非常常见的情况是,数据科学家必须尝试多种想法,并从数据里获取洞察。数据科学家会写很多的代码,但是大部分都是用于测试想法,并不会被用于最终的解决方案。
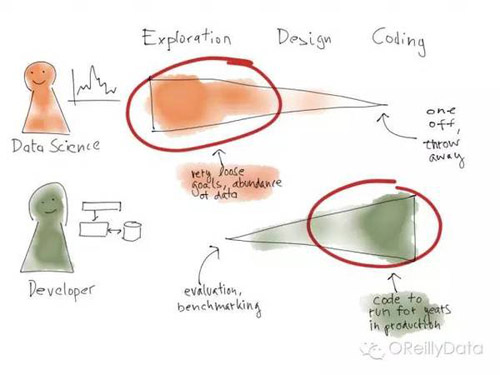
图6:图片来自Mikio Braun的演讲页
与数据科学家相反,程序员通常非常关注于编程。他们的目标是开发一个系统,实现所要求的功能。程序员有时会做一些探索性的工作,比如构建原型、验证概念或是测试性能基准。但他们的工作的主要目标还是写代码。
他们间的不同还明显地体现在代码的变化上。程序员通常会坚持一个非常明确定义的代码开发流程。一般包括创建自己工作流的分支,在开发完成后做评测检查,然后把自己的分支合并进主分支。大家可以并行开发,但必须在协商后才能把他们的分支合并进主分支。然后这个过程再重复进行。这整个过程都是确保主分支会以一个有序的方式演进。
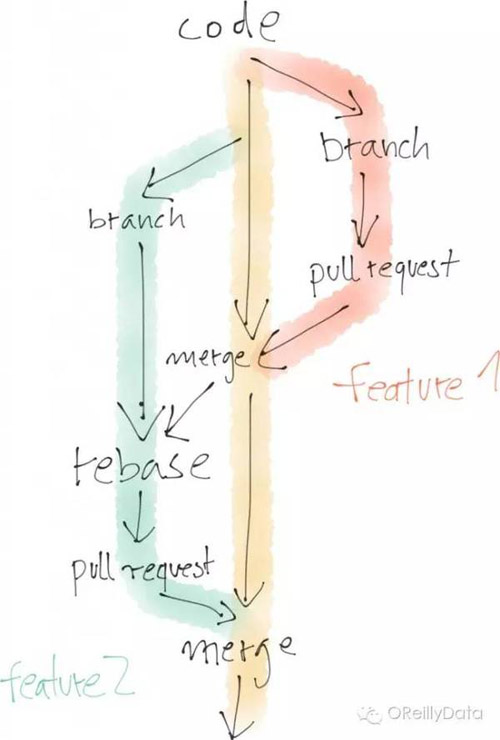
图7:图片来自Mikio Braun的演讲页
数据科学家也会写很多的代码。但正如我之前所说的,这些代码通常是为了验证想法。所以数据科学家可能是会写出一个版本1,但它并没有实现需求。然后又针对一个新的想法写了版本2,随后是2.1和2.2,直到发现还是不能实现需求而停止。再对更新的想法去写版本3和3.1。也许在这个时候,数据科学家意识到,如果采用2.1版里的某些方法并结合3.1版里的某些方法,就能获得一个更好的解决方案。这就带来了版本3.3和3.4,并可能由此形成了最终解决方案。
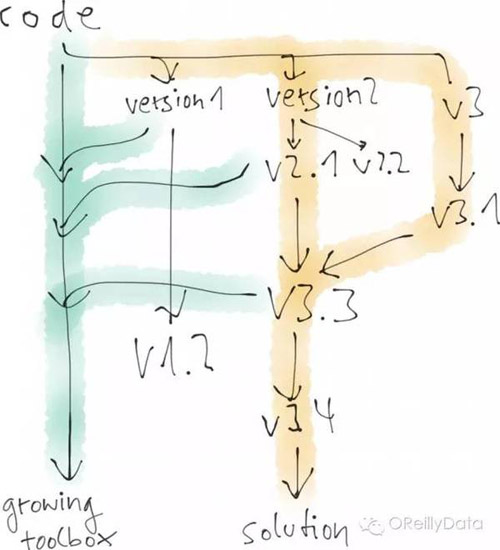
图8:图片来自Mikio Braun的演讲页
一个有意思的事情是,数据科学家实际上可能希望保留所有这些没成功的版本。因为之后的某个时间,也许它们又会被拿来测试新的想法。也许有些部分可以被放入一个“工具箱”里,逐步形成数据科学家自己的私人机器学习库。程序员更希望去删除“无用的代码”(因为他们知道如何快速地找回这些代码),而数据科学家则喜欢保留代码以防万一。
上述的两大不同意味着,在现实中,直接让程序员和数据科学家共同工作可能会出问题。标准的软件工程流程对数据科学家的探索性工作模式并不合适,因为他们的目标是不同的。引入代码评测检查和有序的分支管理、评测、合并分支的工作流对数据科学家而言并不合适,还会减慢他们的工作。同样的,把探索性的模式引入生产系统开发也不会成功。
为此,如何才能构建一个合作模式来保证两边都能高产出的工作?可能第一直觉就是让他们相互分离地工作。例如,完全分开代码库,并让数据科学家独立工作,产出需求文档,再由程序员团队实现。这种方法也行得通,但流程通常会非常得慢,且容易出错。因为重新开发实现一遍就可能会引入错误,尤其是在程序员并不熟悉数据分析算法的情况下。同时能否进行外部迭代来改进系统的表现也依赖于程序员是否有足够的能力来实现数据科学家的需求。
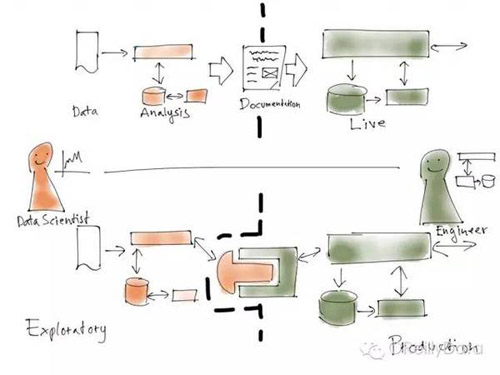
图9:图片来自Mikio Braun的演讲页
幸运的是,很多数据科学家实际上是希望能成为好的程序员,或是反过来。所以我们已经开始试验一些更直接和更能帮助加快流程的合作模式。
例如,数据科学家和程序员的代码库依然是分离的,但部分生产系统会提供清晰定义的接口来方便数据科学家把他们的方法嵌入进系统。与这些生产系统的接口进行沟通的代码必须严格地依据软件开发实践流程,但这是数据科学家的工作。用这种方式,数据科学团队可以在自己的代码快速地迭代,同时也就是完成了对生产系统的迭代。
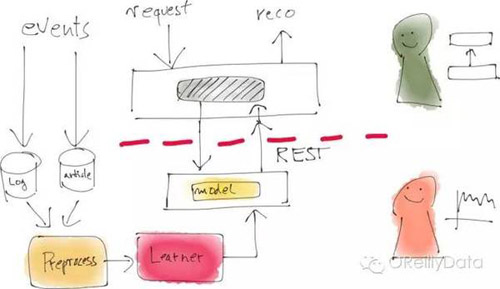
图10:图片来自Mikio Braun的演讲页
这种架构模式的一个具体实现是采用“微服务”方法。即让生产系统去调用数据科学家团队开发的微服务来获取推荐。用这个方式,整个数据科学家使用的离线分析管道还可以被调整用来做A/B测试,甚至是加入生产系统而不用程序员团队重新开发实现。这种模式会要求数据科学家具有更多的软件工程技能,但我们看到越来越多的数据科学家已经具有这样的技能集。事实上,后来我们修改了Zalando的数据科学家的职衔为“研究工程师(数据科学)”来反应这种实际情况。
采用类似这样的方法,数据科学家可以快速实践,对离线数据做迭代研究,并在生产系统环境里迭代开发。整个团队可以持续地把稳定的数据分析方法迁移进生产系统。
持续适应并改进
至此,我概述了一个能把数据科学引入生产系统的架构的典型模式。需要理解的一个关键概念就是这样的系统需要持续地适应并改进(这和几乎所有的针对实际数据的数据驱动项目类似)。能够快速迭代,实验新的方法,使用A/B测试验证结果,这一切都非常重要。
依据我的经验,保持数据科学家团队和程序员团队的分离是不可能达成这些目标的。与此同时,很重要的是,我们也要承认两个团队的工作方式确实是不同的,因为他们的目标不一样(数据科学家的工作更加具有探索性,而程序员更关注于开发软件和系统)。
通过允许各自团队能工作在更适合他们的目标的方式,并定义一些清晰的接口,是有可能集成两个团队,并保证新的方法可以被快速地试错的。这会要求数据科学家团队具有更多的软件工程技能,或是至少能有软件工程师来桥接起两个世界。
本文作者:Mikio Braun
来源:51CTO