本节书摘来自华章出版社《R语言数据分析》一书中的第3章,第3.3节,作者盖尔盖伊·道罗齐(Gergely Daróczi),潘怡 译,更多章节内容可以访问“华章计算机”公众号查看。
3.3 测试
正如在前述章节中讨论过的内容一样,借助microbenchmark包,我们可以在一台机器上重复执行若干遍函数,以获得一些可重现的性能测试结果。
现在,需要先定义作为测试基准的函数,以下一些函数都是从前面样例中挑选出来的:


前面已经介绍过dplyr包的summarise函数需要耗费一些时间用于数据预处理,因此下面我们将重新定义一个函数能够支持在聚集操作时生成新的数据结构:

类似地,在测试data.table时,也需要一些专门用于测试环境的附加变量,由于hlf?ights_dt已经根据DayofWeek的值进行了排序,我们可以为测试创建一个新的data.table对象:

更进一步地,说清楚该对象没有键值可能也有些必要:

现在,我们可以对data.table测试案例上定义函数,并且实现对象到data.table的转换,同时为了和dplyr一致,在转换后的data.table上添加键值:

到这一步,我们已经完成了测试的准备任务,下面可以导入microbenchmark包继续后面的工作了:

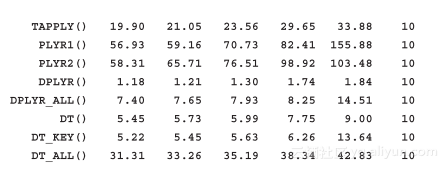
结果非常不错:从之前高于2000毫秒的执行时间,经过工具优化后,缩短为只需要大约1毫秒的时间:
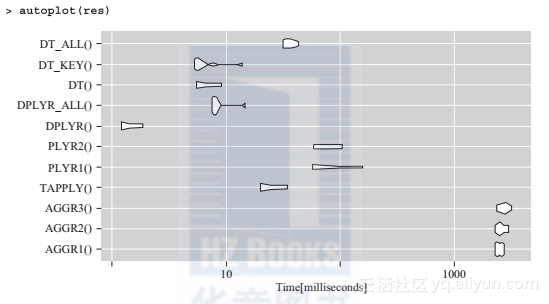
因此,看起来dplyr包是最有效的解决方法,尽管它需要考虑一些额外(对data.frame进行分组)的操作,该方法依然具有毋庸置疑的优势。事实上,如果我们已经准备好了一个data.table对象,就能够节约从data.frame转换到data.table的时间,而data.table的效果要比dplyr更好。不过我估计读者可能并未注意到两个高效方案在时间上的差别。在处理更大规模的数据集时,这两种方法性能都不错。
值得注意的是,dplyr包只能处理data.table对象,因此,我们不用固定在任意一种方法上,在必要时同时使用两种方法都可以。以下是一个POC样例:

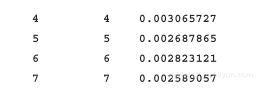
现在,我们已经对使用data.table或者是dplyr计算数据分组平均值的过程非常清楚了。但假如是更复杂的操作又该如何解决呢?