1.6 聚合通信
除了进程间点对点的消息通信,MPI还提供大量针对一组进程间通信的函数,基于一组进程的通信称之为聚合通信。聚合通信的进程都需要调用相同的聚合通信函数。通过大量的聚合通信算法研究,聚合通信采用具有高性能的聚合通信实现算法[73,270,284],因此该通信方式在并行编程中广泛应用。
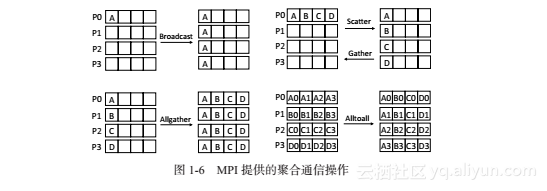
聚合通信有以下三种类型:
(1)同步。MPI_Barrier函数用于同步通信域内的所有进程,执行到MPI_Barrier函数的进程必须等待,直到所有进程均执行到MPI_Barrier函数,所有进程才会进入下一步程序操作。
(2)数据迁移。MPI提供大量通用的数据迁移函数。例如,MPI_Bcast函数将根进程中的数据发送到通信域中的其他进程上。MPI_Scatter函数将数据缓冲区中的数据分发到通信域中其他进程上。MPI_Gather函数功能与MPI_Scatter函数相反,该函数将其他进程上的数据收集到根进程上。MPI_Allgather函数功能与MPI_Gather函数类似,区别在于MPI_Allgather函数除了根进程外,通信域中其他进程也收集相同的数据。MPI_Alltoall函数实现组内进程数据全交换,每一个进程可向其他进程发送不同的数据,也可接收其他进程发送的数据。上述聚合通信函数如图1-6所示。除了基本的聚合通信函数外,MPI还提供其他聚合通信函数,从而允许用户向每个进程发送不等数量的数据。
(3)聚合运算。MPI提供归约和扫描操作,实现数据算术运算,例如求解最小值和最大值、求和、逻辑与运算以及其他用户自定义的计算算法。MPI_Reduce函数提供归约操作,结果保存在根进程中。MPI_Allreduce函数功能类似于MPI_Reduce函数,但结果保存在所有进程中。MPI_Scan函数对于每一个进程i,对进程0,…,i上的数据进行归约操作,结果存放到进程i上。MPI_Exscan函数功能类似于MPI_Scan函数,区别在于MPI_Exscan函数不对自身进程上的数据进行归约操作。MPI_Reduce_scatter函数同时包含归约和分发两项功能。
图1-7 一种比图1-2中代码更加高效的数据发送通信方式。MPI_Reduce函数用于对所有进程上的数据进行求和操作,并将结果保存在0号进程上
所有聚合通信函数均提供阻塞和非阻塞两种通信方式。上述聚合通信函数均为阻塞式通信,只有通信完成后,聚合通信函数才返回。非阻塞式通信函数在名称中会加入字母“I”,例如MPI_Ibcast或者MPI_Ireduce。非阻塞聚合通信函数初始化通信后立即返回,无需等待通信操作完成。用户通过调用测试或者等待函数,获取通信操作完成情况或者等待通信操作完成。MPI提供大量计算和通信重叠的聚合通信函数,例如MPI_Ibarrier等函数。
在图1-7中,通过MPI_Bcast函数,实现将0号进程上相同的数据广播到其他进程上。同时,通过MPI_Reduce函数,实现将所有进程上的数据进行求和运算(MPI_SUM为MPI提供预定义的求和操作),并将结果保存在0号进程上。