程序日志(AppLog)有什么特点?
- 内容最全:程序日志是由程序员给出,在重要的地点、变量数值以及异常都会有记录,可以说线上90%以上Bug都是依靠程序日志输出定位到
- 格式比较随意:代码往往经过不同人开发,每个程序员都有自己爱好的格式,一般非常难进行统一,并且引入的一些第三方库的日志风格也不太一样
- 有一定共性:虽然格式随意,但一般都会有一些共性的地方,例如对Log4J日志而言,会有如下几个字段是必须的:
- 时间
- 级别(Level)
- 所在文件或类(file or class)
- 行数(Line Number)
- 线程号(ThreadId)
处理程序日志会有哪些挑战?
1. 数据量大
程序日志一般会比访问日志大1个数量级:假设一个网站一天有100W次独立访问,每个访问大约有20逻辑模块,在每个逻辑模块中有10个主要逻辑点需要记录日志。
则日志总数为:
100W 20 10 = 2 * 10^8 条
每条长度为200字节,则存储大小为
2 10^8 200 = 4 * 10^10 = 40 GB
这个数据会随着业务系统复杂变得更大,一天100-200GB日志对一个中型网站而言是很常见的。
2. 分布服务器多
大部分应用都是无状态模式,跑在不同框架中,例如:
- 服务器
- Docker(容器)
- 函数计算(容器服务)
对应实例数目会从几个到几千,需要有一种跨服务器的日志采集方案
3. 运行环境复杂
程序会落到不同的环境上,例如:
- 应用相关的会在容器中
- API相关日志会在FunctionCompute中
- 旧系统日志在传统IDC中
- 移动端相关日志在用户处
- 网页端(M站)在浏览器里
为了能够获得全貌,我们必须把所有数据统一并存储起来。
如何解决程序日志需求
1.统一存储
目标:要把各渠道数据采集到一个集中化中心,打通才可以做后续事情。
我们可以在日志服务中创建一个项目来存储应用日志,日志服务提供30+种日志采集手段:无论是在硬件服务器中埋点,还是网页端JS,或是服务器上输出日志,都可以在实时采集列表中找到。
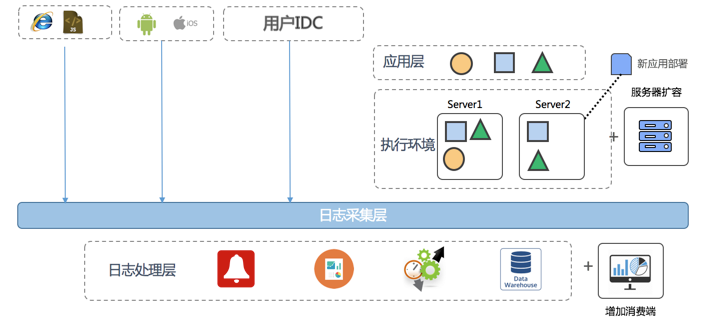
在服务器日志上,除了使用SDK等直接写入外,日志服务提供便捷、稳定、高性能Agent-Logtail。logtail提供windows、linux两个版本,在控制台定义好机器组,日志采集配置后,就能够实时将服务日志进行采集,这里有一个5分钟视频。
在创建完成一个日志采集配置后,我们就可以在项目中操作各种日志了。
可能有人要问到,日志采集Agent非常多,有Logstash,Flume,FluentD,以及Beats等,Logtail和这些相比有什么特点吗?
- 使用便捷:提供API、远程管理与监控功能,融入阿里集团百万级服务器日志采集管理经验,配置一个采集点到几十万设备只需要几秒钟
- 适应各种环境:无论是公网、VPC、用户自定义IDC等都可以支持,https以及断点续传功能使得接入公网数据也不再话下
- 性能强,对资源消耗非常小:经过多年磨练,在性能和资源消耗方面比开源要好,详见对比测试
2. 快速查找定位
目标:无论数据量如何增长、服务器如何部署,都可以保证定位问题时间是恒定的
例如有一个订单错误,一个延时很长,我们如何能够在一周几TB数据量日志中快速定位到问题。其中还会涉及到各种条件过滤和排查等。
- 例如我们对于程序中记录延时的日志,调查延时大于1秒,并且方法以Post开头的请求数据:
Latency > 1000000 and Method=Post*
- 对于日志中查找包含error关键词,不包含merge关键词的日志
- 一天的结果

- 一周的结果
- 更长时间结果
这些查询都是在不到1秒时间内可以返回



3. 关联分析
关联有两种类型,进程内关联与跨进程关联。我们先来看看两者有什么区别:
- 进程内关联:一般比较简单,因为同一个函数前后日志都在一个文件中。在多线程环节中,我们只要根据线程Id进行过滤即可
- 跨进程关联:跨进程的请求一般没有明确线索,一般会通过RPC中传入TracerId来进行关联
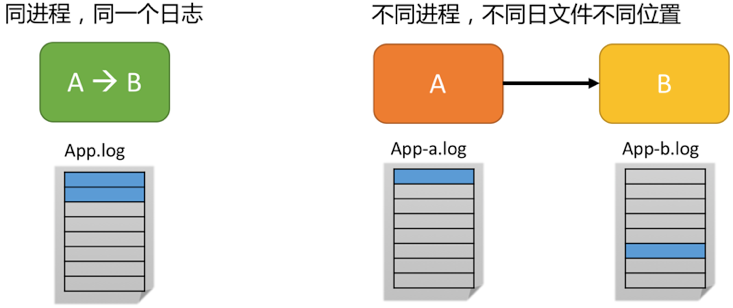
3.1 上下文关联
还是以使用日志服务控制台距离,线上通过关键词查询定位到一个异常日志:
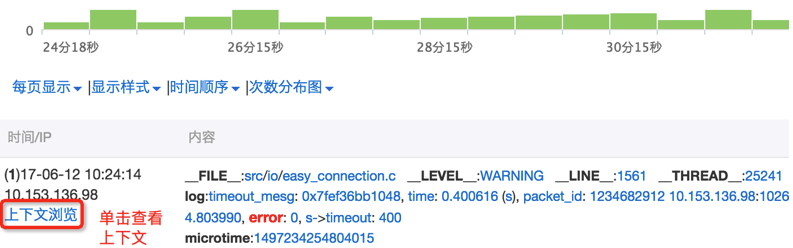
点击上下文查询后,既跳转到前后N条上下文
- 显示框可以通过“更早”、“更新”等按钮加载更多上下文
- 也可以点击“返回普通搜索模式”进一步排查通过筛选框筛选ThreadID,进行精准上下文的过滤

更多上下文查询文档请参见文档索引查询下上下文查询
3.2 跨进程关联
跨进程关联也叫Tracing,最早的工作是Google在2010年的那篇著名“Dapper, a Large-Scale Distributed Systems Tracing Infrastructure”,之后开源界借鉴了Google思想做成过了平民化的各种Tracer版本。目前比较有名的有:
- Dapper(Google): 各 tracer基础
- StackDriver Trace (Google),现在兼容了ZipKin
- Zipkin:twitter开源的Tracing系统
- Appdash:golang版本
- 鹰眼:阿里巴巴集团中间件技术技术部研发
- X-ray:AWS在2016年Re:Invent上推出技术
如果从0开始使用Tracer会相对容易一些,但在现有系统中去使用,则会有改造的代价和挑战。
今天我们可以基于日志服务,实现一个基本Tracing功能:在各模块日志中输出Request_id, OrderId等可以关联的标示字段,通过在不同的日志库中查找,即可拿到所有相关的日志。
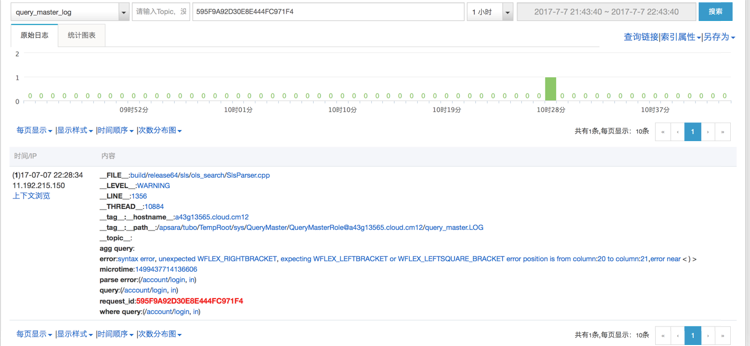
例如我们可以通过SDK查询 前端机,后端机,支付系统,订单系统等日志,拿到结果后做一个前端的页面将跨进程调用关联起来,以下就是基于日志服务快速搭建的Tracing系统。
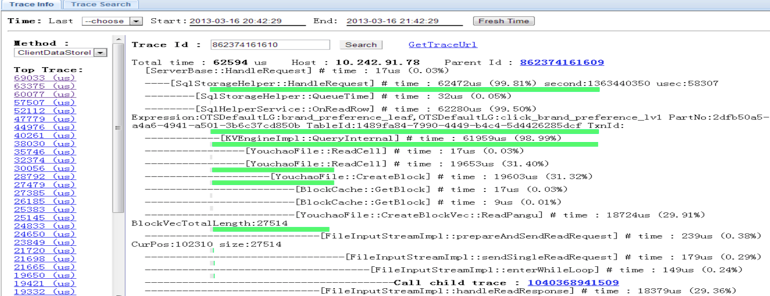
4. 统计分析
查找到特点日志后,我们有时希望能做一些分析,例如线上有多少种不同类型的错误日志?
- 我们先通过对"__level__"这个日志级别字段进行查询,得知一天内有2720个错误:
__level__:error

- 接下来,我们可以根据file,line这两个字段(确定唯一的日志类型)来进行统计聚合
__level__:error | select __file__, __line__, count(*) as c group by __file__, __line__ order by c desc
就能够拿到所有错误发生的类型和位置的分布了
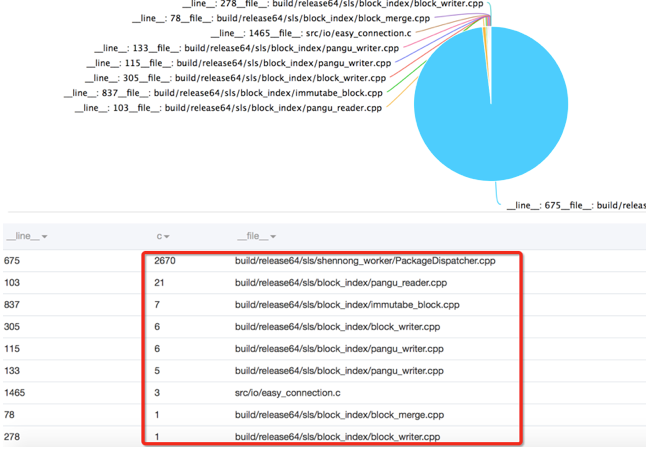
其他还有诸如根据错误码、高延时等条件进行IP定位与分析等,更多可以参见访问日志分析案例。
5. 其他
1.备份日志审计
可以将日志备份至OSS或存储成本更低的IA,或直接到MaxCompute,详情参见日志投递
2.关键词报警
目前有如下方式可以进行报警
1. 在日志服务中将日志查询另存为一个定时任务,对结果进行报警,参见文档
2. 通过云监控日志报警功能,参见文档
3.日志查询权限分配管理
可以通过子账号+授权组方法隔离开发、PE等权限,参见文档
最后说一下价格与成本,程序日志主要会用到日志服务LogHub + LogSearch功能,这里有一个和开源方案对比,在查询成本上是开源方案25%,使用非常便捷,另你开发工作事半功倍。