简介
云原生技术栈是下一代应用转型的必然选择,它包含了微服务架构,DevOps和容器技术。对于微服务架构来说,应用是“第一公民”,他逐渐蚕食原来底层软件或者硬件的功能,例如服务注册与发现以及负载均衡;而对于容器平台来说,容器是“第一公民”,他提供了容器注册与发现和负载均衡,同时容器技术将应用和外面的世界做了隔离,这样很多应用运行的假设就会失效。那当微服务应用运行在容器中的时候,我们会遇到哪些常见问题?我们又该如何解决呢?
企业应用在向微服务架构转型的过程中,微服务如何划分是最基本的问题。我们可以通过业务架构的梳理来理解业务,并同时使用领域设计的方法进行微服务的设计。其次,我们需要做系统设计,系统设计会更关注性能、可用性、可扩展性和安全性等;当然,我们还需要做接口设计,定义微服务之间的契约。
Java在企业中被广泛应用,当前,选择Spring Cloud作为微服务开发框架成为一个广泛的趋势。微服务架构的复杂性需要容器技术来支撑,应用需要容器化,并使用CaaS平台来支撑微服务系统的运行。
本文探讨的主题是来自于企业级Java应用在容器化过程中遇到的基础问题(与计算和网络相关),希望以小见大探讨微服务转型过程中遇到的挑战。
容器内存限制问题
让我们来看一次事故,情况如下:当一个Java应用在容器中执行的时候,某些情况下会容器会莫名其妙退出。
1.Dockfile如下:
FROM airdock/oracle-jdk:latest
MAINTAINER Grissom Wang <grissom.wang@daocloud.io>
ENV TIME_ZONE Asia/Shanghai
RUN echo "$TIME_ZONE" > /etc/timezone
WORKDIR /app
RUN apt-get update
COPY myapp.jar /app/ myapp.jar
EXPOSE 8080
CMD [ "java", "-jar", "myapp.jar" ]
2.运行命令
docker run –it –m=100M –memory-swap=100M grissom/myapp:latest
3.日志分析
执行docker logs container_id,出现了java.lang.OutOfMemoryError
4.问题初步分析
因为我们在执行容器的时候,对内存做了限制,同时在Java启动参数重,没有对内存使用做限制,是不是这个原因导致了容器被干掉呢?
当我们执行没有任何参数设置(如上面的myapp)的 Java 应用程序时,JVM 会自动调整几个参数,以便在执行环境中具有最佳性能,但是在使用过程中我们逐步发现,如果让 JVM ergonomics (即JVM人体工程学,用于自动选择和行为调整)对垃圾收集器、堆大小和运行编译器使用默认设置值,运行在容器中的 Java 进程会与我们的预期表现严重不符(除了上诉的问题)。
首先我们来做一个实验:
1.在我本机(Mac)上执行docker info命令
Server Version: 17.06.0-ce
Kernel Version: 4.9.31-moby
Operating System: Alpine Linux v3.5
OSType: linux
Architecture: x86_64
CPUs: 2
Total Memory: 1.952GiB
Name: moby
2.执行docker run -it -m=100M –memory-swap=100M debian cat /proc/meminfo
MemTotal: 2047048 kB = 2G
MemFree: 609416 kB = 600M
MemAvailable: 1604928 kB = 1.6G
虽然我们启动容器的时候,指定了容器的内存限制,但是从容器内部看到的内存信息和主机上的内存信息几乎一致。
因此我们找到原因了:docker switches(-m,-memory和-memory-swap) 在进程超过限制的情况下,会指示 Linux 内核杀死该进程。但 JVM 是完全不知道限制,因此会很有可能超出限制。在进程超过限制的时候,容器进程就被杀掉了!
解决问题的一种思路就是使用JVM参数来限制内存的使用,这个需要根据JVM内存参数的定义来做巧妙的设置,但是幸运的是从Java SE 8u131和JDK 9开始,Java SE开始支持Docker CPU和内存限制。
具体实现逻辑如下: 如果-XX:ParalllelGCThreads或-XX:CICompilerCount未指定为命令行选项,则JVM将Docker CPU限制应用于JVM在系统上看到的CPU数。然后JVM将调整GC线程和JIT编译器线程的数量,就像它在裸机系统上运行一样,其CPU数量设置为Docker CPU限制。如果-XX:ParallelGCThreads或-XX:CICompilerCount指定为JVM命令行选项,并且指定了Docker CPU限制,则JVM将使用-XX:ParallelGCThreads和-XX:CICompilerCount值。
对于Docker内存限制、最大Java堆的设置还有一些工作要做。要在没有通过-Xmx设置最大Java堆的情况下告知JVM要注意Docker内存限制,需要两个JVM命令行选项:
-XX:+ UnlockExperimentalVMOptions
-XX:+ UseCGroupMemoryLimitForHeap。
-XX:+ UnlockExperimentalVMOptions是必需的,因为在将来版本中,Docker内存限制的透明标识是目标。当使用这两个JVM命令行选项,并且未指定-Xmx时,JVM将查看Linux cgroup配置,这是Docker容器用于设置内存限制的方式,以透明地指定最大Java堆大小。 Docker容器也使用Cgroups配置来执行CPU限制。
服务注册与发现
在微服务的场景中,运行的微服务实例将会达到成百上千个,同时微服务实例存在失效,并在其他机器上启动以保证服务可用性的场景,因此用IP作为微服务访问的地址会存在需要经常更新的需求。
服务注册与发现就应用而生,当微服务启动的时候,它会将自己的访问Endpoint信息注册到注册中心,以便当别的服务需要调用的时候,能够从注册中心获得正确的Endpoint。
如果用Java技术栈开发微服务应用,Spring Cloud(https://spring.io/)将会是大家首选的微服务开发框架。Spring Cloud Service Discovery就提供了这样的能力,它底层可以使用Eureka(Netflix),ZooKeeper,ETCD。这里我们以使用Spring Cloud Eureka为例(使用Spring Cloud Eureka的文档可以参考http://cloud.spring.io/spring-cloud-static/spring-cloud-netflix/1.3.1.RELEASE/)。
在本机运行如下命令:
java -jar target/discovery-client-demo-0.0.1-SNAPSHOT.jar
该应用会将自己的信息注册到本地Eureka。我们可以通过打开Eureka的Dashboard,看到如下信息: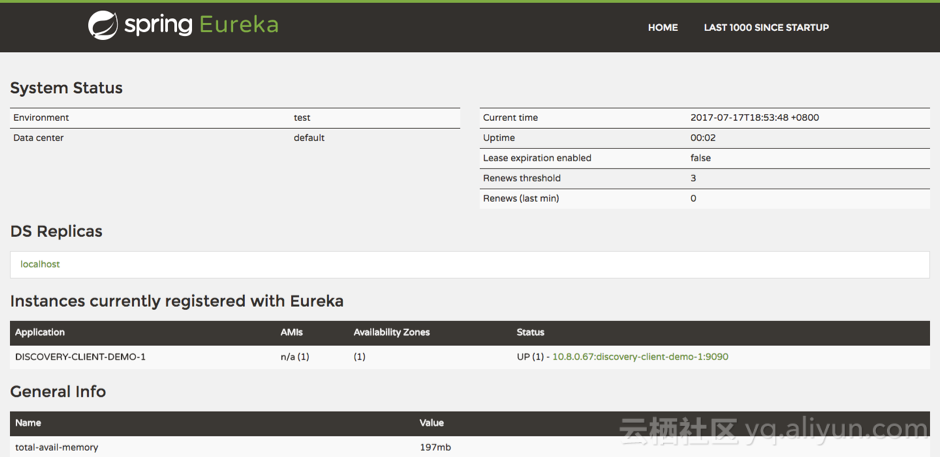
图 1 物理机上运行Eureka Client
我们可以看到应用的如下信息:
• 名称:discovery-client-demo
• IP: 10.8.0.67
• Port: 9090
但是我们在容器化场景中,遇到了问题。Dockerfile如下:
FROM airdock/oracle-jdk:latest
MAINTAINER Grissom Wang <grissom.wang@daocloud.io>
ENV TIME_ZONE Asia/Shanghai
RUN echo "$TIME_ZONE" > /etc/timezone
WORKDIR /app
RUN apt-get update
COPY target/discovery-client-demo-0.0.1-SNAPSHOT.jar /app/discovery-client-demo.jar
EXPOSE 8080
CMD [ "java", "-jar", "discovery-client-demo.jar" ]
假设我们现在在本机使用Docker run命令执行容器化discovery-client-demo,命令行如下:
docker run -d --name discovery-client-demo1 -e eureka.client.serviceUrl.defaultZone=http://10.8.0.67:8761/eureka/ -e spring.application.name=grissom -p 8080:8080 discovery-client-demo:latest
docker run -d --name discovery-client-demo2 -e eureka.instance.prefer-ip-address=true –e eureka.client.serviceUrl.defaultZone=http://10.8.0.67:8761/eureka/ -e spring.application.name=grissom2 -p 8081:8080 discovery-client-demo:latest
前后两个容器的区别在于,第二个指示应用注册的使用IP,而默认是Hostname。
打开Eureka的Dashboard,我们可以看到如下信息: 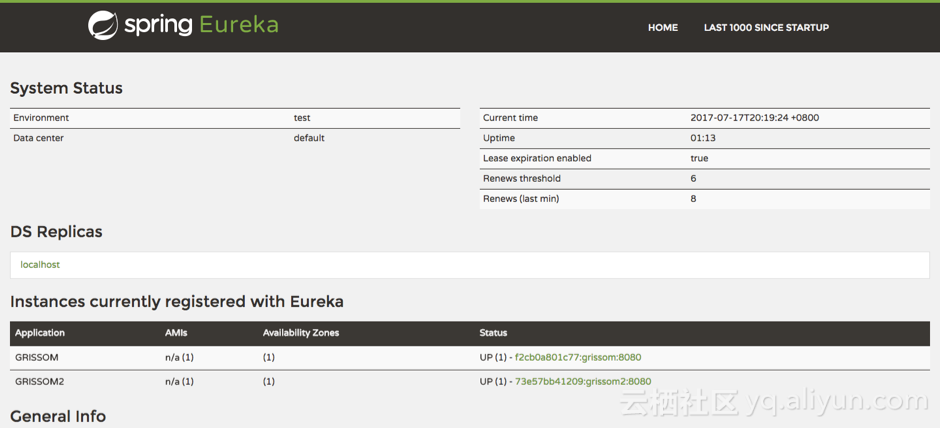
图 2 容器中运行Eureka Client
调用Eureka的Apps接口,我们可以看到更加详细的信息: 
图 3 注册应用的详细信息
这个时候我们发现了问题,两个应用注册的信息中,Hostname, IP和端口都使用了容器内部的主机名,IP和端口(如8080)。这就意味着在Port-Mapping的场景下,应用注册到Eureka的时候,注册信息无法被第三方应用使用。
解决这个问题的第一个思路如下: 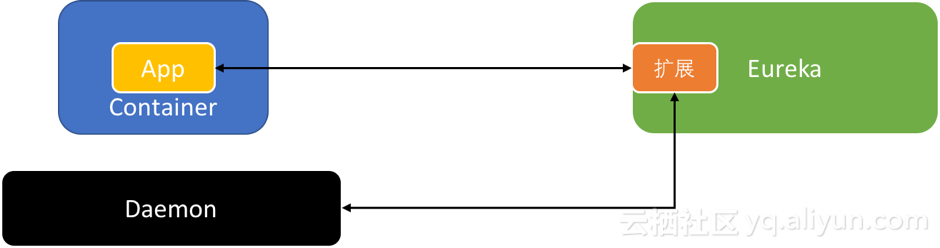
图 4 对Eureka进行扩展
我们对Eureka进行扩展,对所有客户端过来的请求进行拦截,然后从Docker Daemon中拿到正确的外部访问信息来进行替换,从而确保注册到Eureka中的信息是外部能够访问的。
该方案需要做的工作:
• 需要同时对Eureka Client和Server改造,能够在Client上报的信息中加入container ID等信息。
• Eureka服务端需要加入一个过滤器,需要对所有的注册请求进行处理,根据container ID将内部hostname,IP和端口改为外部可以访问的IP和端口。
该方案的挑战:
• 因为只有容器被创建后才有ID,无法在启动参数中指定,因此应用在容器启动的时候,无法拿到容器的ID。
• 对于Eureka Server和Client的改造,无法贡献回社区,因此需要自己维护版本,存在极大的风险。
AWS的EC2 提供了实例元数据和用户数据的API,它可以通过REST API的方式供运行在EC2内部的应用使用。API形式如下:
http://169.254.169.254/latest/meta-data/
其中IP地址是固定的一个IP地址。
因此我们也可以提供一个类似的元数据和用户数据API,供容器内部的应用调用。同时为了减少对应用的侵入,我们可以在应用启动之前执行一个脚本来获取相应的信息,并设置到环境变量中,供应用启动后读取并使用,流程如下: 
图 5 方案流程
总结
本文总结了使用Java开发的企业级应用在向微服务架构应用转型过程中,在容器化运行过程中遇到的常见问题、原因分析及解决方法。总结下来,由于容器技术的内在特性,我们需要对应用做一些改造,同时相应的工具如JVM也需要对容器有更好的本地支持。
原文链接:http://geek.csdn.net/news/detail/238739