各位MaxCompute的用户及运维朋友,在日常使用中,您有没有遇到这种场景: 我作业提交了这么久,为啥还没看到计算任务执行?作业提交后状态一直是 RUNNING ,到底执行到了什么阶段?作业提交后只能等,也不知道完成的进度如何?为何当前作业一直在等待,到底什么作业正在占用着我的计算资源?
现在,为了解决用户的这些痛点,MaxCompute 正式上线了作业队列展示功能。用户可以通过 MaxCompute Studio 和 Logview 查看作业执行的详细阶段,查看计算集群的等待队列,从此不再对提交作业的执行状态一无所知。
用户可以根据队列详情优化自己的作业优先级和调度机制,从而进一步提高计算资源的利用率。
本文首先对MaxCompute作业执行的各个阶段进行说明,然后以MaxCompute Studio为例,说明如何查看作业排队位置,查看队列详情以及作业状态转换历史信息。
注意:本文所说的作业只针对SQL和MR类型,MaxCompute之上运行的其他类型的作业,可能会有不同的调度机制。
作业执行阶段的说明
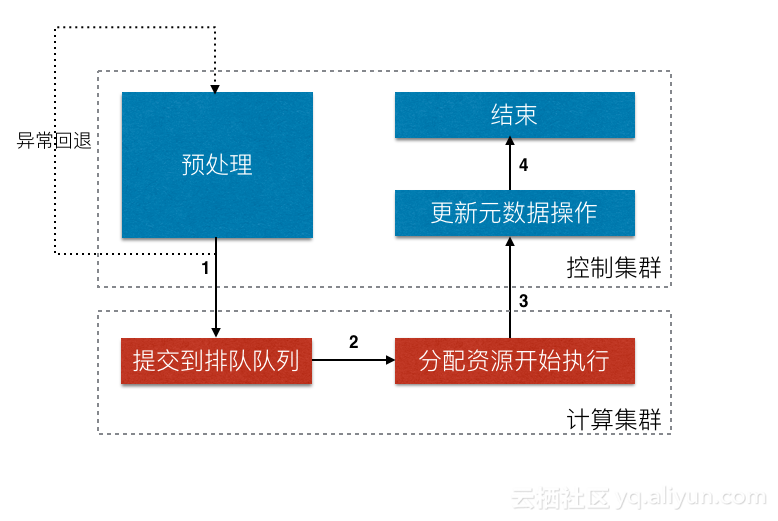
MaxCompute 作业的生命周期如图所示,作业提交后,首先会在控制集群上进行预处理和优化,生成执行计划;然后会提交到计算集群对应的优先级队列等待分配计算资源;
分配到第一片计算资源后,作业开始正式执行。对于一些异常情况,还可能会出现回退、重新执行等状态。
在排队功能上线之前,所有上述阶段的作业状态都会展示为RUNNING,用户无法知道自己提交的作业进行到哪一个阶段。现在,可以通过作业的substatus属性查看运行中作业的详细状态。substatus具体的状态码说明如下:
| ID | Description | 备注 |
|---|---|---|
| 1010 | Waiting for scheduling | 作业已提交,准备调度 |
| 1011 | Waiting for cluster resource | 等待作业资源 |
| 1012 | Waiting for concurrent task slot | 等待并发执行资源 |
| 1013 | Waiting for data replication | 等待数据复制 |
| 1020 | Waiting for execution | 等待作业处理 |
| 1030 | Preparing for execution | 准备进行作业处理 |
| 1050 | Task rerun | 重新执行 |
| 1090 | Execution failed | 执行失败 |
| 1210 | SQLTask is initializing | SQL作业初始化中 |
| 1220 | SQLTask is compiling query | SQL作业编译中 |
| 1230 | SQLTask is optimizing query | SQL作业优化中 |
| 1240 | SQLTask is generating execution plan | SQL作业生成执行计划中 |
| 1250 | SQLTask is running the plan on fuxi | SQL作业调度执行中 |
| 1260 | SQLTask is update meta information | SQL作业更新元数据信息 |
| 1270 | SQLTask is finishing | SQL作业成功结束 |
如何查看作业队列和优先级
MaxCompute Studio从2.7.0版本开始提供作业队列查看的功能。通过Job Explorer查看用户提交的正在运行中的所有作业:
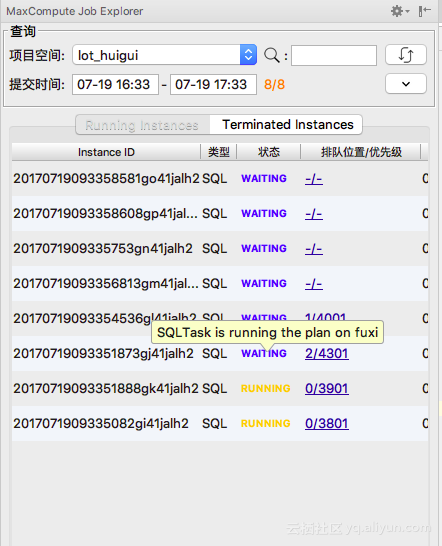
作业在计算集群正式开始执行之前状态为 WAITING,通过hover tooltips可以查看状态详情。
对于处在排队队列中的作业,可以在 排队位置/优先级 列里面看到作业的排队位置和全局优先级。排队位置(Position)值为0表示作业已经分配到计算资源,开始执行。排队位置为正整数n时,表示前面还有n-1个作业在同一队列中等待资源
全局优先级是基于项目空间的优先级以及用户提交作业的priority属性计算出来的,值越大表示优先级越低。
作业分配到计算资源后的状态为 RUNNING。
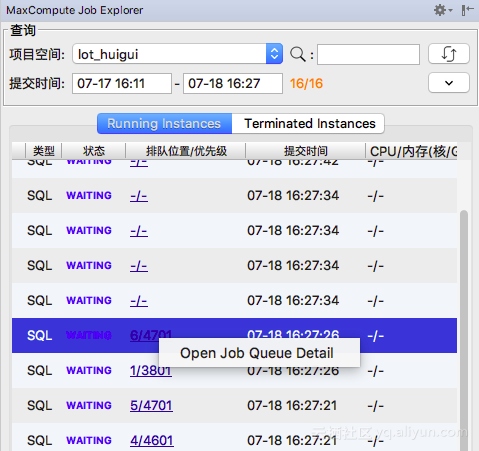
打开作业所在的等待队列
对于排队中的作业,可以点击 排队位置/优先级 列 打开作业所在的等待队列:
排队队列中展示了同一个项目空间内所有未执行结束的作业。其中,未进入排队队列的作业展示在最前方,表示为 -/- ;进入队列等待计算资源的作业按照排队位置有序;已经进入计算集群运行以及计算结束正在执行后处理操作的作业展示在最后。如下图:
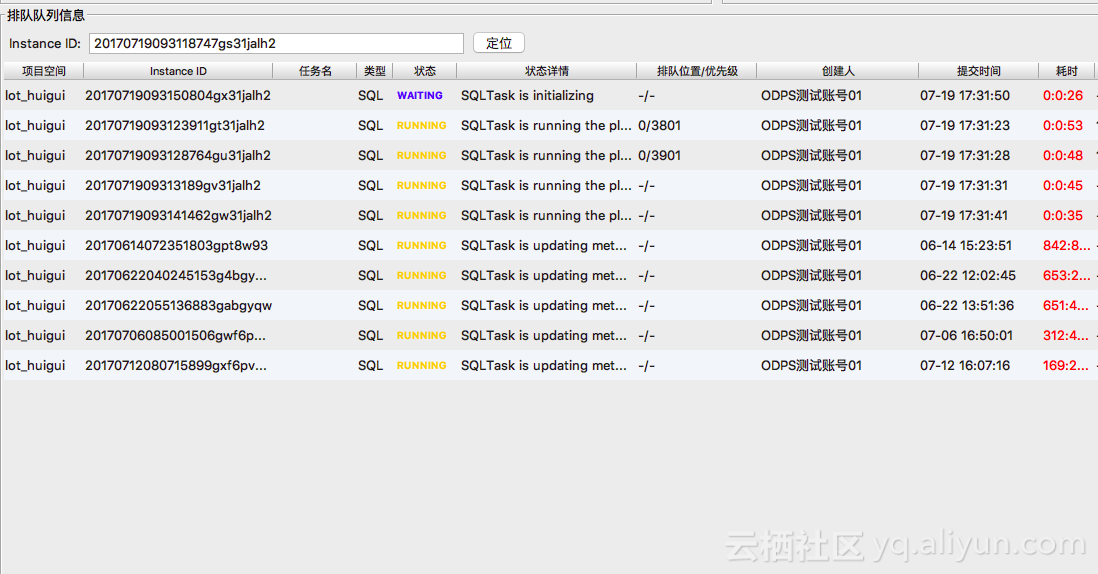
用户可以通过排队队列可以轻松看出项目空间内排列在自己作业之前的作业以及长时间占用计算资源的作业。可以据此优化作业优先级及调度策略。
排队队列的详细说明可以在阿里云官网查看 MaxCompute Studio 的使用文档获取。
作业队列中双击 状态详情 列可以查看该作业的状态转换信息。可以看到作业执行各个阶段及执行时间信息。
对于运行中的作业,也可用从作业详情中直接打开所在的排队队列,如图中所示,点击 排队队列 对应的链接:
未来规划
为了帮助用户更好的了解作业运行状态,MaxCompute之后会提供用户作业进度信息,预估作业的执行进度和结束时间。并且会将作业状态转换详情持久化到meta里以便用户在作业结束后进行性能分析和作业比较。同时,也非常欢迎广大用户朋友提出自己的需求和建议,我们一起努力,让MaxCompute成为更好的大数据分析平台。