前几天领导安排一个小项目,大意是解决这样一个问题:
在Linux系统下,进程可能由于各种原因崩溃,此时我们要找到出问题的源代码在某一个文 件的具体行号,这样调试起来就会方便,高效很多,可能是公司项目要用到,想想挺有意思的,加上自己本身是个Linux狂热者,最终花了两三天解决了这个问 题,当然我的领导我们称之为专家指点了我很多,废话少说,下面是解决问题的思路和步骤以及自己的一些想法
解 决该问题的大体思路是这样的:在Linux下,进程崩溃时内核(也就是我们所谓的操作系统)会向进程发送信号,比如我们程序运行崩溃时经常会看到 segmentation falt这样的信息,这是进程非法操作内存,内核会向进程发送SIGENV信号,那么我们凭什么可以找到进程崩溃的原因对应的源代码的位置呢,我们知道, 每个进程都有自己的堆栈,当某个进程崩溃时,堆栈里保存了一些关键信息,通过这些信息我们可以定位到出错的源代码位置,那么我们怎么来获得进程崩溃时堆栈 的信息呢,请记住,Linux是当今世界上最为强大的操作系统(不管你信不信,反正我是信了,^_^),在Linux系统里有个backtrace这些个 函数可以获得当前堆栈信息,好了,到这里问题已经解决了一半,backtrace信息中的有一个地址包含了出错代码在文件中的偏移量
需要注意的是编译时一定要加上 -g和-rdynamic参数
如果我们使用的是静态库或者出错的代码不在动态库中,那么我们可以直接用命令"addr2line -e 可执行文件名 偏移地址"打印出出错的代码行,下面是具体步骤
在测试程序的29行非法操作了内存
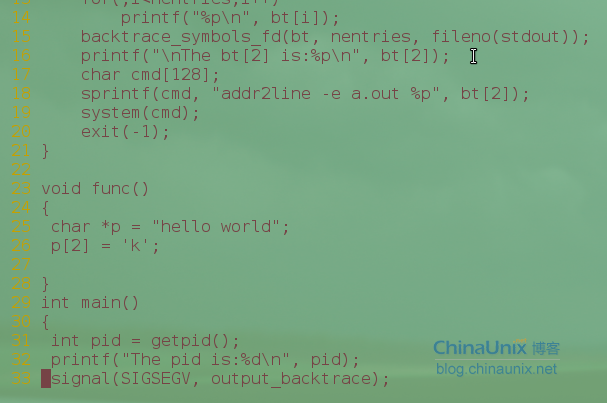
我们把addr2line命令放在程序里面做了,在代码中也可以看得到,下面这幅图片是程序的输出,可以看到
打印出源代码出错的行数为29
如果crash在一个动态库so里面,比较麻烦一点,此时addr2line不能直接给出代码行。因为我们都知道,so里面的地址在可执行文件装载的时候, 是可以被 reallocate的。所以,如果只有一个so的地址,要找出对应代码行的话,送给 addr2line的参数地址就是一个偏移地址,这里的偏移地址就是backtrace中的地址减去动态库加载的时候的基地址,这个基地址我们可以通过 /proc/pid/maps这个文件找到,pid是当前进程号,下面是具体步骤,跟之前的步骤类似,只不过我们为了测试,将func函数编译进了一个动 态库里面
这里我们只给出测试文件,具体怎么实现动态库,这个很容易,不在此多提,下面是测试程序的一部分
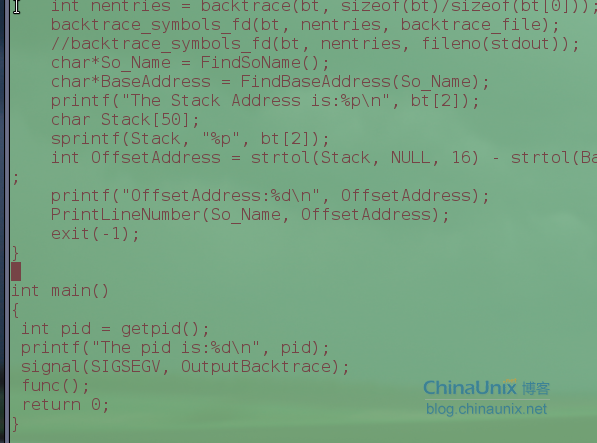
我们在/proc/pid/maps文件中找出出错动态库加载的基地址,用backtrace中的地址与基地址相减得到偏移地址就可以了,下面是程序输出
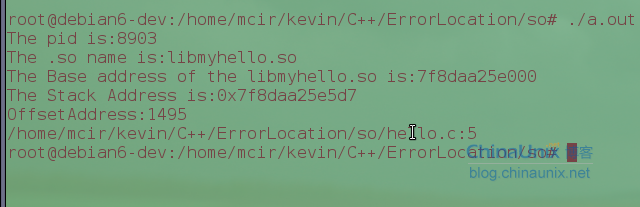
可以看到,我们用hello.c做的动态库,定位到代码出错在hello.c的第五行
下面是定位动态库错误的源代码:
 test.zip
test.zip