集算器JDBC 类似一个不完整的数据库JDBC驱动,它不带物理表,可将集算器视为只有存储过程的数据库(较强的计算能力,较弱的存储机制)。与使用数据库JDBC非常类似,可以像调用存储过程一样调用集算器程序。不同的是,集算器JDBC是个完全嵌入式计算引擎,所有运算都在这个嵌入包中完成,而不象数据库那样还有一个独立的服务器来实施计算。
1、加载驱动jar
集算器JDBC所需jar包括:dm.jar、poi-3.7-20101029.jar、log4j_128.jar、icu4j_3_4_5.jar、dom4j-1.6.1.jar,这5个jar包可以在集算器IDE安装目录的\esProc\
lib下获得。在启动 java 应用程序时加载上述jar包,如果在web应用下,可以把这些 jar包放在 WEB-INF/lib 目录下。
值得注意的是,集算器JDBC需要JDK1.6 或以上版本。
2、修改配置文件config.xml和dfxConfig.xml
准备config.xml文件,这个文件中包含了集算器的基本配置信息,如注册码、寻址路径、
主目录、数据源配置等,它可以在集算器安装目录的esProc\config路径下找到,在部署时可以先调整其中的配置(详细配置信息解释见附录)。
配置授权信息
在config.xml文件里做如下配置:
< regCode>license</regCode>
其中license为授权码,目前集算器提供了免费的分发版供用户集成,免费授权码可在官网上直接获得。
将 config.xml及 dfxConfig.xml保存到应用项目的类路径下。
这里要注意的是,配置文件的名称必须为config.xml和dfxConfig.xml,不能改变。在配置数据库连接信息时,不能循环调用,不能将集算器JDBC本身作为数据源在配置中使用。
3、部署集算器程序
将事先编辑好的集算器脚本(dfx文件),放到应用项目的类路径下,也可以放到dfxConfig.xml文件的<paths/>节点指定的路径中。
4、Java调用集算器程序
由于集算器程序可以返回单一结果集,也可以返回多个结果集,这里分别来看一下。
4.1、单结果集
集算器脚本
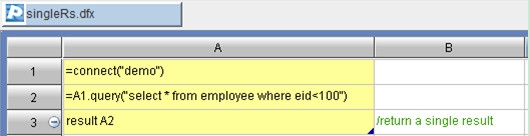
Java调用
public class CallSingleRS
{
public
voidtestDataServer(){
Connection con = null;
com.esproc.jdbc.InternalCStatement st;
try{
//建立连接
Class.forName("com.esproc.jdbc.InternalDriver");
con= (Connection) DriverManager.getConnection("jdbc:esproc:local://");
//调用存储过程,其中singleRs是dfx的文件名
st =(com.esproc.jdbc.InternalCStatement)con.prepareCall("call
singleRs(?)");
//设置参数
st.setObject(1,"5");
//执行存储过程
st.execute();
//获取结果集
ResultSet rs = (ResultSet)st.getResultSet();
}
catch(Exception
e){
System.out.println(e);
}
finally{
//关闭连接
if (con!=null)
{
try {
con.close();
}
catch(Exception
e) {
System.out.println(e);
}
}
}
}
}
4.2、多结果集
集算器脚本
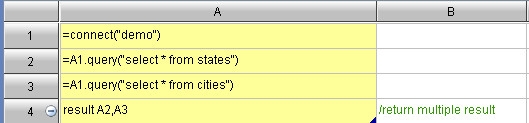
Java调用
这里给出主要代码,其他部分与上例相同。
//调用存储过程
st =( com.esproc.jdbc.InternalCStatement)con.prepareCall("call MutipleRs()");
//执行存储过程
boolean hasResult = st.execute();
//当存在返回的结果集时
if (hasResult) {
//获取多个结果集
ResultSet set = st.getResultSet();
int csize = set.getMetaData().getColumnCount();
//返回多个结果集时,返回 1 列多行的数据,csize为 1
while (set.next()) {
Object o = set.getObject(1);
//本例中,每次可读出1个序表,分别取出A2和A3中的序表
}
}