
第二部分:职位信息清洗及数据提取
数据分析师的收入怎么样?哪些因素对于数据分析的薪资影响最大?哪些行业对数据分析人才的需求量最高?我想跳槽,应该选择大公司大平台还是初创的小公司?按我目前的教育程度,工作经验,和掌握的工具和技能,能获得什么样水平的薪资呢?
我们使用python抓取了2017年6月26日拉钩网站内搜索“数据分析”关键词下的450条职位信息。通过对这些职位信息的分析和建模来给你答案。
本系列文章共分为五个部分,分别是数据分析职位信息抓取,数据清洗及预处理,数据分析职位分布分析,数据分析薪资影响因素分析,以及数据建模和薪资预测。这是第二篇:职位信息清洗及数据提取。
第二篇文章是对获取的数据进行清洗,预处理和特征提取。在第一篇文章中我们抓取了拉勾网的450条职位信息及职位描述。但这些信息无法直接用于数据分析,我们需要对抓取到的信息进行清洗,规范现有数据的格式,提取信息中的数据及特征,为后续的数据分析和建模做准备。下面开始介绍苦逼的
数据清洗流程介绍。
数据清洗前的准备工作
首先是开始前的准备工作,导入所需要的库文件,包括常用的numpy和pandas库用于计算平均薪资以及对字符进行分列等操作,正则表达式re库用于字符的查找和替换操作,结巴分词库jieba用于对职位描述进行分词操作,自然语言处理nltk库用于计算职位描述的文字丰富度指标,还有KMeans用于对平均
薪资进行聚类操作。
- #导入所需库文件
- import re
- import numpy as np
- import pandas as pd
- import jieba as jb
- import jieba.analyse
- import jieba.posseg as pseg
- import nltk
- from sklearn import preprocessing
- from sklearn.cluster import KMeans
导入我们之前抓取并保存的数据表,并查看数据表的维度以及各字段名称。后面我们会经常使用这些字段名称。
- #导入之前抓取并保存的数据表
- lagou=pd.DataFrame(pd.read_csv('lagou_data_analysis_2017-06-26.csv',header=0,encoding='GBK'))
- #查看数据表维度及字段名称
- lagou.columns,lagou.shape

职位信息清洗及预处理
开始对职位信息的各个字段进行清洗和预处理,主要清洗的内容包括文本信息提取和处理,内容搜索和替换,字段内的空格处理,数值信息提取和计算,英文字母统一大小写等等。我们将先展示清洗前的原始字段,然后在展示清洗后的新字段内容。
行业字段清洗及处理
第一个清洗的字段是行业字段,抓取到的行业字段比较混乱,有些只有一个行业名称,有些则有两级的行业名称。我们保留行业字段第一部分的信息,对有两部分行业名称的字段取前一个。
- #查看原始industryField字段信息
- lagou[['industryField']].head()

由于行业名称之间有的以顿号分割,有的以逗号分割,我们先将所有的分隔符统一为逗号,然后对这个字段进行分列。并将分列后的字段重新拼接回原数据表中。
- #对industryField字段进行清洗及分列
- #创建list存储清洗后的行业字段
- industry=[]
- #将顿号分隔符替换为逗号
- for x in lagou['industryField']:
- c=x.replace("、", ",")
- industry.append(c)
- #替换后的行业数据改为Dataframe格式
- industry=pd.DataFrame(industry,columns=["industry"])
- #对行业数据进行分列
- industry_s=pd.DataFrame((x.split(',') for x in industry["industry"]),index=industry["industry"].index,columns=['industry_1','industry_2'])
- #将分列后的行业信息匹配回原数据表
- lagou=pd.merge(lagou,industry_s,right_index=True, left_index=True)
- #清除字段两侧空格
- lagou["industry_1"]=lagou["industry_1"].map(str.strip)
以下是清洗后的行业字段。
- #查看清洗后的行业字段
- lagou[["industry_1","industry_2"]].head()
融资阶段字段清洗及处理
第二个清洗的字段是融资阶段字段,抓取下来的原始信息中对融资阶段进行了双重标识,例如成长型(A轮)。由于第一个标识”成长型”定义比较宽泛,我们提取第二个括号中的标识。
- #查看清洗前的financeStage字段
- lagou[['financeStage']].head()

首先建立一个字典,将数据表中融资阶段的每一条信息与字典中的Key进行查找。如果融资阶段信息中包含字典中的任何一个key,我们就把这个key对应的value记录下来。
- #提取并处理financeStage中的融资信息
- #创建一个字典
- f_dict = {'未融资':'未融资',
- '天使轮':'天使轮',
- 'A轮':'A轮',
- 'B轮':'B轮',
- 'C轮':'C轮',
- 'D轮':'D轮',
- '不需要':'不需要融资',
- '上市公司':'上市公司'
- }
- #创建list存储清洗后的信息
- financeStage2=[]
- #逐一提取financeStage字段中的每一条信息
- for i in range(len(lagou['financeStage'])):
- #逐一提取字典中的每一条信息
- for (key, value) in f_dict.items():
- #判断financeStage字段中是否包含字典中的任意一个key
- if key in lagou['financeStage'][i]:
- #如何包含某个key,则把对应的value保存在list中
- financeStage2.append(value)
- #把新保存的list添加到原数据表中
- lagou["financeStage1"]=financeStage2
- #查看清洗后的financeStage字段
- lagou[["financeStage1"]].head()

职位名称字段清洗及处理
第三个清洗的字段是职位名称,这里我们要提取职位里的title信息。没有title信息的都统一归为其他。具体方法是将每个职位名称与现有的title列表逐一判断,如果职位名称中含有title关键字就被划分到这个类别下。否则被归为其他类。
- #查看清洗前的positionName字段
- lagou[['positionName']].head()

- #提取并处理positionName中的职位信息
- #创建list存储清洗后的信息
- positionName3=[]
- #对职位名称进行判断归类
- for i in range(len(lagou['positionName'])):
- if '实习' in lagou['positionName'][i]:
- positionName3.append("实习")
- elif '助理' in lagou['positionName'][i]:
- positionName3.append("助理")
- elif '专员' in lagou['positionName'][i]:
- positionName3.append("专员")
- elif '主管' in lagou['positionName'][i]:
- positionName3.append("主管")
- elif '经理' in lagou['positionName'][i]:
- positionName3.append("经理")
- elif '专家' in lagou['positionName'][i]:
- positionName3.append("专家")
- elif '总监' in lagou['positionName'][i]:
- positionName3.append("总监")
- elif '工程师' in lagou['positionName'][i]:
- positionName3.append("工程师")
- else:
- #以上关键词都不包含的职位归为其他
- positionName3.append("其他")
- #把新保存的list添加到原数据表中
- lagou["positionName1"]=positionName3
- #查看清洗后的positionName字段
- lagou[["positionName1"]].head()

薪资范围字段清洗及处理
第四个清洗的字段是薪资范围。抓取到的数据中薪资范围是一个区间值,比较分散,无法直接使用。我们对薪资范围进行清洗,去掉无关的信息并只保留薪资上限和下限两个数字,然后使用这两个数字计算出平均薪资值。
- #查看清洗前的salary字段
- lagou[['salary']].head()
- #提取并计算平均薪资
- #创建list用于存储信息
- salary1=[]
- #对salary字段进行清洗
- for i in lagou['salary']:
- #设置要替换的正则表达式k|K
- p = re.compile("k|K")
- #按正则表达式对salary字段逐条进行替换(替换为空)
- salary_date = p.sub("", i)
- #完成替换的信息添加到前面创建的新list中
- salary1.append(salary_date)
- #将清洗后的字段合并到原数据表中
- lagou['salary1']=salary1
- #对薪资范围字段进行分列
- salary_s=pd.DataFrame((x.split('-') for x in lagou['salary1']),index=lagou['salary1'].index,columns=['s_salary1','e_salary1'])
- #更改字段格式
- salary_s['s_salary1']=salary_s['s_salary1'].astype(int)
- #更改字段格式
- salary_s['e_salary1']=salary_s['e_salary1'].astype(int)
- #计算平均薪资
- #创建list用于存储平均薪资
- salary_avg=[]
- #逐一提取薪资范围字段
- for i in range(len(salary_s)):
- #对每一条信息字段计算平均薪资,并添加到平均薪资list中。
- salary_avg.append((salary_s['s_salary1'][i] + salary_s['e_salary1'][i])/2)
- #将平均薪资拼接到薪资表中
- salary_s['salary_avg']=salary_avg
- #将薪资表与原数据表进行拼接
- lagou=pd.merge(lagou,salary_s,right_index=True, left_index=True)
- #查看清洗以后的salary_avg字段
- lagou[["salary_avg"]].head()

职位信息中的数据提取
在职位描述字段中,包含了非常详细和丰富的信息。比如数据分析人才的能力要求和对各种数据分析工具的掌握程度等。我们对这个字段的一些特征进行指标化,对有价值的信息进行提取和统计。
职位描述字段中的数据提取
第五个清洗的字段是职位描述,准确的说从职位描述字段中提取信息。职位描述中包含了大量关于职位信息,工作内容,和个人能力方面的信息,非常有价值。但无法直接拿来使用。需要进行信息提取。我们将对职位描述字段进行三方面的信息提取。
第一是提取职位描述中对于个人能力的要求,换句话说就是数据分析人员使用工具的能力。我们整理了10个最常见的数据分析工具。来看下每个职位描述中都出行了哪些工具名称。由于一些工具间存在可替代性,所以每个职位描述中可能会出现多个工具的名称。没出现一个工具名称,我们就会在相应的工具下表示1,如果没有出现则标识为0。
- #查看清洗以前的job_detail字段
- lagou[['job_detail']].head()
- #提取职位描述字段,并对英文统一转化为小写
- lagou['job_detail']=lagou['job_detail'].map(str.lower)
- #提取职位描述中的工具名称
- tools=['sql','python','excel','spss','matlab','sas','r','hadoop','spark','tableau']
- #创建list用于存储数据
- tool=np.array([[0 for i in range(len(tools))] for j in range(len((lagou['job_detail'])))])
- #逐一提取职位描述信息
- for i in range(len(lagou['job_detail'])):
- #逐一提取工具名称
- for t in tools:
- #获得工具名称的索引位置(第几个工具)
- index=tools.index(t)
- #判断工具名称是否出现在职位描述中
- if t in lagou['job_detail'][i]:
- #如果出现,在该工具索引位置(列)填1
- tool[i][index]=1
- else:
- #否则在该工具索引位置(列)填0
- tool[i][index]=0
- #将获得的数据转换为Dataframe格式
- analytics_tools=pd.DataFrame(tool,columns=tools)
- #按行(axis=1)对每个职位描述中出现的工具数量进行求和
- tool_num=analytics_tools.sum(axis=1)
- #将工具数量求和拼接到原数据表中
- analytics_tools["tool_num"]=tool_num
- #将表与原数据表进行拼接
- lagou=pd.merge(lagou,analytics_tools,right_index=True, left_index=True)
- #查看从job_detail中提取的分析工具信息
- lagou[['sql','python','excel','spss','matlab','sas','r','hadoop','spark','tableau','tool_num']].head()
职位描述所使用的字数统计
第二是计算职位描述所使用的字数,我们猜测初级简单的工作描述会比较简单,而高级复杂的工作描述则会更复杂一些。因此职位描述中不同的字数里也可能隐藏着某种信息或关联。
- #计算职位描述的字数
- #创建list用于存储新数据
- jd_num=[]
- #逐一提取职位描述信息
- for i in range(len(lagou['job_detail'])):
- #转换数据格式(list转换为str)
- word_str = ''.join(lagou['job_detail'][i])
- #对文本进行分词
- word_split = jb.cut(word_str)
- #使用|分割结果并转换格式
- word_split1 = "| ".join(word_split)
- #设置字符匹配正则表达式
- pattern=re.compile('\w')
- #查找分词后文本中的所有字符并赋值给word_w
- word_w=pattern.findall(word_split1)
- #计算word_w中字符数量并添加到list中
- jd_num.append(len(word_w))
- #对字符数量进行归一化
- min_max_scaler = preprocessing.MinMaxScaler()
- min_max_jd_num = min_max_scaler.fit_transform(jd_num)
- #将归一化的数据添加到原数据表中
- lagou['jd_num']=min_max_jd_num
- #查看职位描述字数
- jd_num[:10]

- #查看归一化的职位描述字段
- lagou[['jd_num']].head()

职位描述的词汇丰富度统计
第三是计算职位描述中的文字丰富度指标。和前面的字数统计一样。初级职位所对应的工作会相对简单,在描述上也会比较简单。高级职位则可能需要更详细的和负责的描述。因此文字丰富度指标上也会更高一些。
- #计算职位描述文字丰富度
- #创建新list用于存储数据
- diversity=[]
- #逐一提取职位描述信息
- for i in range(len(lagou['job_detail'])):
- #转换数据格式(list转换为str)
- word_str = ''.join(lagou['job_detail'][i])
- #将文本中的英文统一转化为小写
- word_str=word_str.lower()
- #查找职位描述中的所有中文字符
- word_list=re.findall(r'[\u4e00-\u9fa5]', word_str)
- #转换数据格式(list转换为str)
- word_str1=''.join(word_list)
- #对文本进行分词
- word_split = jb.cut(word_str1)
- #使用空格分割结果并转换格式
- word_split1 = " ".join(word_split)
- #使用nltk对句子进行分词
- tokens = nltk.word_tokenize(word_split1)
- #转化为text对象
- text = nltk.Text(tokens)
- #计算职位描述的文字丰富度(唯一词/所有词)
- word_diversity=len(set(text)) / len(text)
- #将文本词汇丰富度数据添加到list中
- diversity.append(word_diversity)
- #将文字丰富度匹配到原数据表中
- lagou["diversity"]=diversity
- #查看职位描述丰富度字段
- lagou[["diversity"]].head()

对数据分析的薪资进行聚类
完成清洗和数据提取后,平均薪资已经比薪资范围要具体的多了,但仍然比较离散。我们对这些平均薪资进行聚类来支持后面的建模和预测工作。以下是具体的代码和聚类结果。我们将类别标签添加到原始数据表中。
- #提取平均工作年限,平均薪资和平均公司规模字段
- salary_type = np.array(lagou[['salary_avg']])
- #进行聚类分析
- clf=KMeans(n_clusters=3)
- #训练模型
- clf=clf.fit(salary_type)
- #将距离结果标签合并到原数据表中
- lagou['cluster_label']= clf.labels_
- #输出聚类结果
- clf.cluster_centers_

聚类后平均薪资被分为三个类别,第1类是薪资均值为19.3K的区间,分类标记为0。第二类是薪资均值为8.2K的区间,分类标记为1,。第三类是薪资均值为32.1的区间,分类标记为3。
- #对平均薪资进行聚类预测
- clf.predict(9),clf.predict(25),clf.predict(30)

- #查看数据表中的类别标识字段
- lagou[['salary_avg','cluster_label']].head()

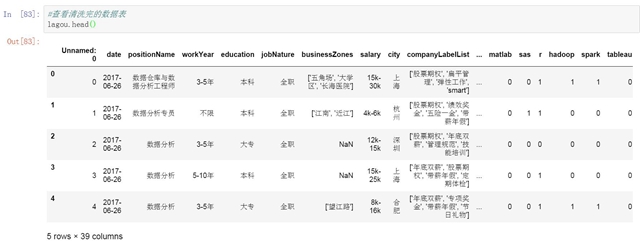
查看清洗及处理后的数据表
到这里我们完成了对450个职位信息的字段清洗和数据提取工作。下面我们再来查看下数据表的维度,名称以及数据表中的数据。在下一篇文章中我们将使用这个数据表对数据分析职位的分布情况以及薪资的影响因素进行分析,并通过建模对薪资收入进行预测。
- #查看数据表维度及字段名称
- lagou.columns,lagou.shape

- #查看清洗完的数据表
- lagou.head()
本文作者:王彦平
来源:51CTO