3.3 Spark 程序的生命周期
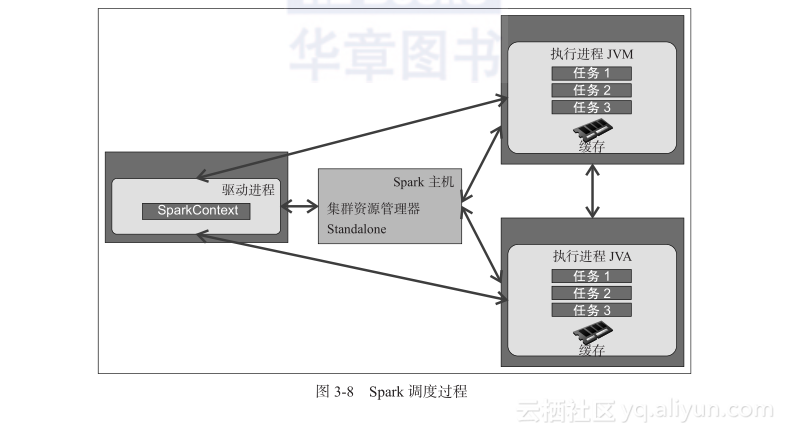
以下步骤讲解了配备 Standalone 资源管理器的 Spark 应用程序的生命周期,图3-8 显示了Spark程序的调度过程:
(1)用户使用 spark-submit 命令提交一个 Spark 应用程序。
(2)spark-submit 在同一节点(客户端模式)或集群(集群模式)上启动驱动进程,并调用由用户指定的 main 方法。
(3)驱动进程联系集群管理器,根据提供的配置参数来请求启动执行进程 JVM 所需的资源。
(4)集群管理器在工作机节点上启动执行进程 JVM。
(5)驱动进程扫描用户应用程序。根据程序中的 RDD 动作和变换,Spark 会创建一个运算图。
(6)当调用一个动作(如 collect)时,图会被提交到一个有向无环图(DAG)调度程序。DAG 调度程序将运算图划分成一些阶段。
(7)一个阶段由基于输入数据分区的任务组成。DAG 调度程序会通过流水线把运算符连一起,从而优化运算图。例如,很多映射(map)运算符可以调度到一个阶段中。这种优化对 Spark 的性能是很关键的。DAG 调度程序的最终结果是一组阶段。
(8)这些阶段会被传递到任务调度程序。任务调度程序通过集群管理器(Spark Standalone / Yarn / Mesos)启动任务。任务调度器并不知道阶段之间的依赖性。
(9)任务在执行进程上运行,从而计算和保存结果。
(10)如果驱动进程的 main 方法退出,或者它调用了 SparkContext.stop(),它就会终止执行进程并从集群管理器释放资源。
图3-8描述了 Spark 程序的调度过程:
从内部来看,每个任务会执行相同的步骤:

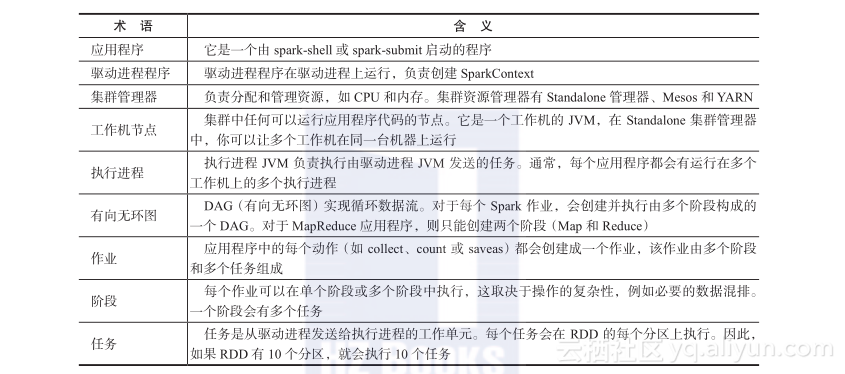
让我们来了解在 Spark 中使用的术语,然后再进一步深入探讨 Spark 程序的生命周期:
3.3.1 流水线
在某些情况下,各阶段的物理集合不一定会完全和逻辑 RDD 图做到 1:1 对应。当无需移动数据就能根据其父节点计算出 RDD 时,就可以产生流水线。例如,当用户顺序地调用 map 和 filter 时,那些调用就可以被折叠成单个变换,它先映射再过滤每个元素。但是,复杂的 RDD 图会由 DAG 调度器划分为多个阶段。
利用 1.4 及更高版本的 Spark 管理界面,Spark 的事件时间轴和 DAG 可视化变得容易了。让我们执行以下代码来查看一个作业及其各阶段的 DAG 可视化:

图3-9 显示了上面的单词计数代码作业及其各阶段的可视化 DAG。它显示作业被分为两个阶段,因为在这种情况下发生了数据的混排。
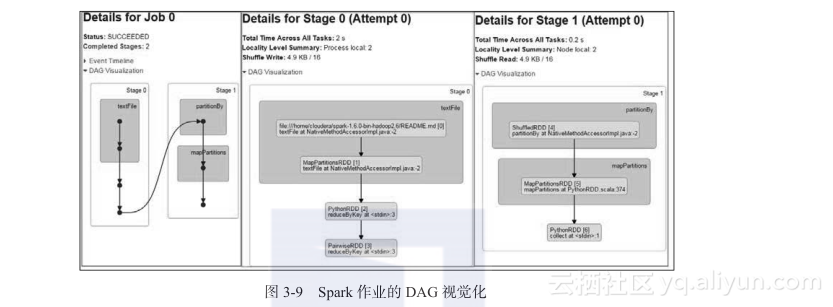
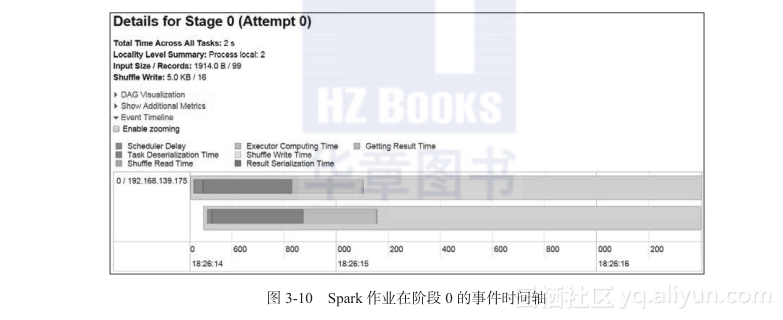
图3-10 显示了阶段 0 的事件时间轴,它指明了每个任务所用的时间。
3.3.2 Spark 执行的摘要
在此简要说明 Spark 执行摘要:
