HBase测试报告
本文将介绍我们对阿里云HBase以及HBase1.1.12进行的测试的细节,大概会介绍测试的环境,测试工具分析以及我们对工具的选择,测试的case,以及测试的结果分析。
1.测试环境
1.1.物理环境:
服务端:单台regionserver:8core,32G,4X250G ssd
Client:16core 64G,双client压;
1.2.软件环境:
client:hbase-1.1.2
server:ApsaraDB for HBase, HBase1.1.12
JDK: Ali-JDK-1.8
1.3.测试条件:
2个client压server端,打满server的性能,server端是单Regionserver。写操作500w数据,共1000万数据,scan,读分别单线程操作5k,5w数据。操作的单条value大小1000B(1KB)
2.测试步骤
2.1.测试工具分析:
测试工具之前一直在YCSB和HBase 自带工具PerformanceEvaluation二者之间进行选择,这里大概介绍下二者之间的区别;
2.2.1.YCSB工具原理和使用方法介绍
YCSB是雅虎开发的测试平台,主要的优点是可以做对比各个平台的性能,他拥有主流数据库的测试接口,包括Mongodb,HBase,Cassandra等;使用YCSB测试HBase的话,在测试的基本环境准备好以后,我们YCSB的client里面的文件夹下面大概有下面几个文件:
[ycsb-hbase10-binding-0.12.0-SNAPSHOT]# ll -l
总用量 52
drwxr-xr-x 2 root root 4096 9月 5 11:38 bin
drwxr-xr-x 2 root root 4096 9月 5 09:54 conf
drwxr-xr-x 2 root root 4096 9月 4 22:26 lib
-rw-r--r-- 1 501 games 8082 11月 9 2016 LICENSE.txt
-rw-r--r-- 1 root root 15489 9月 5 09:56 longtimetest
-rw-r--r-- 1 501 games 615 11月 9 2016 NOTICE.txt
-rw-r--r-- 1 501 games 5484 11月 9 2016 README.md
drwxr-xr-x 2 501 games 4096 9月 5 11:40 workloads
上面的conf文件夹本来是没有的,但是这里是需要人为的加入相应的conf文件夹,这里的话,在conf文件夹下面是需要放入hbase-site.xml的配置文件,或者这个配置文件最好和服务端的配置文件一样,如果不一样至少也要保证zk的地址是一样的。
在workloads里面有需要的各个相关的测试参数,下面以2个实际的case 解释下测试的各个参数的意思:
1.bin/ycsb load hbase10 -P workloads/workloads -p table=usertable -p columnfamily=cf -p fieldlength=50 -p fieldcount=1 -s threads 50
2.bin/ycsb run hbase10 -P workloads/workloada -p table=usertable -p columnfamily=cf -p fieldlength=1000 -p fieldcount=1 -s -threads 50
[root@ ycsb-hbase10-binding-0.12.0-SNAPSHOT]# cat workloads/workloada
recordcount=1000
operationcount=1000
workload=com.yahoo.ycsb.workloads.CoreWorkload
readallfields=true
readproportion=0.5
updateproportion=0.5
scanproportion=0
insertproportion=0
requestdistribution=zipfian
上面case中,(1)表示的是使用ycsb load相关信息数据到hbase的数据库里面,实际上也就是写入部分数据到hbase中,-p 后面一般跟的是属性信息,包括table是usertable,columnfamily是cf ,写入的文件的长度是50B,写入1个文件,也就是一列。启动线程是50个线程做这么些事情;一共要写多少数据呢?在workloads/workloads这个文件里面会有一个recordcount ,这个表示的是写入的总共条数,当然这个参数也可以在命令行传输;
(2)表示的是开始执行run操作,run操作的类型主要是看workload/workloada里面的“readproportion”,“updateproportion”,“scanproportion”,“insertproportion”占用的比例,比如insertproportion=1,那就是写,如果insertproportion=0.5,readproportion=0.5 那么就是读写各50%,同理这个时候配置文件里面会有一个operationcount,表示需要操作的次数,这些操作次数里面读写各占50%。
requestdistribution 表示的是请求的分布类型,可以是类似正太分布,还是2/8请求分布,或者是别的分布。上面的zipfian表示2/8分布。
此外,YCSB还有很多和HBase相关的参数配置,比如:写的时候的writeBufferSize,读的时候是否有setBlockCache等。
2.2.2.HBase PerformanceEvaluation工具原理以及使用方法介绍
HBase PerformanceEvaluation 这个工具是HBase 自带的,测试的case 以及提供给外界的接口比YCSB 更丰富,比如提供了:RandomWrite,SequenceWrite,scan,randomSeekScan,scanRange10 ,scanRange100 等等。最直观的case,YCSB的直观的scan的case 就没有上述PE的丰富。我们本文中的测试的工具主要使用的是HBase Performance工具。我们以几个测试的实际case 来说明用法和相应的原理:
1.sh hbase org.apache.hadoop.hbase.PerformanceEvaluation --nomapred --writeToWAL=false --table=xxx --rows=50000 randomWrite 100
2.sh hbase org.apache.hadoop.hbase.PerformanceEvaluation --nomapred --writeToWAL=false --table=xxx --rows=50000 sequentialWrite 100
3.sh hbase org.apache.hadoop.hbase.PerformanceEvaluation --nomapred --writeToWAL=true --table=xxx --rows=50000 randomWrite 100
4.sh hbase org.apache.hadoop.hbase.PerformanceEvaluation --nomapred --writeToWAL=true --table=xxx --rows=50000 sequentialWrite
5.sh hbase org.apache.hadoop.hbase.PerformanceEvaluation --nomapred --table=xxx --rows=50000 randomRead 100
6.sh hbase org.apache.hadoop.hbase.PerformanceEvaluation --nomapred --table=xxx --rows=5000 --caching=100 scanRange100 100
先来介绍用法,上述1-6个case 我们看到相关的参数,nomapred,writeToWAL, table, rows 以及各个randomWrite,sequentialWrite,scanRange100,等;下面列一个表大概介绍用法:
| 参数 | 意义 |
|---|---|
| nommapred | 默认使用本地启动mapreduce方式测试,如果有此参数,表示使用本地启动线程方式,非mr方式测试 |
| table | 测试的表名 |
| rows | 因为pe本地启动多线程的模式是,每一个线程需要操作一定的数量的key,这里后面跟操作的key的数量,默认是1024*1024 |
| startRow | 每个线程操作key的起始key,默认是0;当然,这里的key,实际到最终操作的row key 有点小区别,下面会说 |
| compression | 表对数据的压缩策略(lzo,gz,snappy,lz4,zstd,none几种策略),是在服务端的表没有的时候,这个参数是有意义的,默认是没有压缩 |
| blockEncoding | 表的data block的encoding策略: NONE; PREFIX; DIFF; FAST_DIFF; PREFIX_TREE,默认none |
| writeToWAL | 写的时候Hlog的策略,有: SYNC_WAL 和 SKIP_WAL 2种,但是这里我们在测试的时候添加了一种新的ASYNC_WAL的方式,标志异步的flush wal ;这里原来的true标志sync_wal,false标志skip,我们改为false 标志位async_wal方式; |
| multiGet | 标志get多条,在server端get多条需要的数据,然后返回;默认是0;单条get不受影响 |
| columns | 表示有多少个列,默认是1,我们这里使用默认的case |
| caching | 表示在在服务端cache多少数据,然后一次拉回来;主要是scan的时候用到 |
| randomWrite | 上面说了每个线程发送对应的数据量的数据,从startRow开始到最终条数终止,每次的row key 以总共操作的rows随机出一个数字,row的总数是线程数*rows;row key 26byte |
| sequentialWrite | 这里的row key 是以star row 开始,和这个数据是有相关性的,顺序key |
| randomRead | 读的key是randowrite 一样,具有随机性 |
| scan | 给定指定的start row,开始scan,但是这里好像代码是只读到第一条key就返回,应该是个bug,我们已经改了 ,而且start row 每次应该读完需要变化 |
| randomSeekScan | 和上述的scan做对比,每一次读的star row是随机的,这里是读到最终的数据为止; |
| scanRange10 | 随机的指定范围的scan,scan的key的起止之间是10个;scanrang100是100个,依次类推 |
pe的大概的原理是:client启动线程池,线程池的上限线程是我们传递多少线程的参数,也就是各个case最后的100。然后会启动多个线程,每个线程并发的去执行rows次的读/写/scan操作;当然各个操作的类型是不一样的。
pe只是统计了整个流程下来消耗的平均时间以及各个线程的延时等信息,没有统计单位时间内这个server所处理的rps(request per second),我们这边修改了代码,统计该数据,大概的思路很简单,就是以所有线程并行操作的所有操作记录数count除以平均时间ts,得到的就是每秒这个sever处理的请求;
2.2.测试case:
| 写操作标志 | 写操作类型 |
|---|---|
| sw1 | 顺序Batch100,ASYNC_WAL |
| sw2 | 顺序Batch100,SYNC_WAL |
| sw3 | 顺序Batch2 ,ASYNC_WAL |
| sw4 | 顺序Batch 2,SYNC_WAL |
| sw5 | 顺序写一条,ASYNC_WAL |
| sw6 | 顺序写一条,SYNC_WAL |
| rw1 | 随机Batch100,ASYNC_WAL |
| rw2 | 随机Batch 100,SYNC_WAL |
| rw3 | 随机Batch 2,ASYNC_WAL |
| rw4 | 随机Batch2,SYNC_WAL |
| rw5 | 随机写一条,ASYNC_WAL |
| rw6 | 随机写一条,SYNC_WAL |
| 读操作标志 | 读操作 |
|---|---|
| nr1 | 无cache命中,随机读一条 |
| nr2 | 无cache命中,scan100条 |
| yr1 | cache命中近100%,随机读一条 |
| yr2 | cache命中近100%,scan100条 |
这里解释下上述测试case的意思:顺序/随机的意思是指:写入的row key的规律是随机性产生还是具有顺序特性;batch 100、2条等是指每次提交给服务端的key的条数。ASYNC_WAL/SYNC_WAL是指每次写操作下,服务端对于WAL 日志的处理是异步flush到文件系统,或者是同步flush到文件系统。无命中cache和命中cache主要是指这次读/scan的请求是否有命中cahce。
为了更好的对比数据,我们的两个版本的大部分参数都是用默认参数,比如这里的blockcache使用lrucache,size是默认大小。我们的表没有开启压缩,我们的minor compaction阈值没有做变化,等等。当然,这些详细的参数设置我们后面会有一篇单独的文章进行介绍,调优相关。
2.3.测试方法
对于写操作:通过设置writeWAL可以设置写时候是如何操作write-ahead-logging的。对于随机还是顺序的设置key,主要是pe自己有这个接口。
对于读操作:是否有cache的命中,无cahce的话,通过设置单表的blockcache选项是否是true,false,测试单表需要通过修改表的属性里面cache与否设置是否开启cache; cache的命中率的提高是通过预读多次,在监控中观测cache的命中率来做判断。 当观察到监控中的现象是cahce free size够大,且cache的hint percent是0/近100%的场景下,取到需要的测试结果。
此外我们使用2个client进行测试,2个client是同一个az,为啥使用2client,因为单client的时候发现cpu容易打满,这个时候线程越多对client而言以及压力测试并不是好事,我们使用2个client分别测试,发现各100线程的时候,sever的性能表现比较不错,在某些场景下是可以把server的cpu/磁盘压榨的比较不错;此外个人认为单client 多线程和多client在分布式场景下效果相差不是很大。
3.测试结果
3.1.测试结果柱状图
下面给出了随机写,顺序写以及随机读,scan 100条数据在各个背景下的性能情况,主要的输出数据有3个维度:rps(单秒的request请求),所有请求的平均延时,99延时;其中PE是多线程的请求,输出的数据给出各个线程的99延时,我们大概随机抽样了几条线程的99延时数据,这里主要输出的信息集中在rps和平均延时,这里的平均延时是多条线程并发请求sever以后处理完数据的各个线程的平均延时。此外这里还有一个地方需要注意下,对于scan的话,一次scan100条左右,所有我们最终统计的rps是在统计次数上乘以100作为大概的rps;但是scan下面的延时是每次的请求时延,对于get/write请求这个延时没有什么影响,单纯对scan操作做一个注释;此外cache的命中也不能保证100%,只是通过多次读取,达到cache命中的的可能性,所以上面写的是命中率近100%。
3.1.1随机写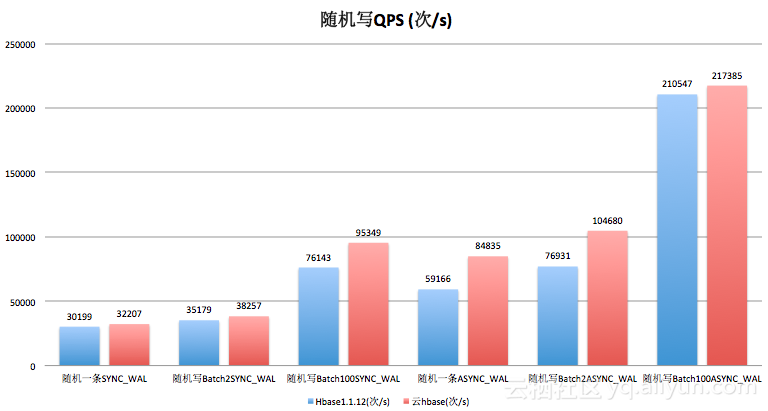
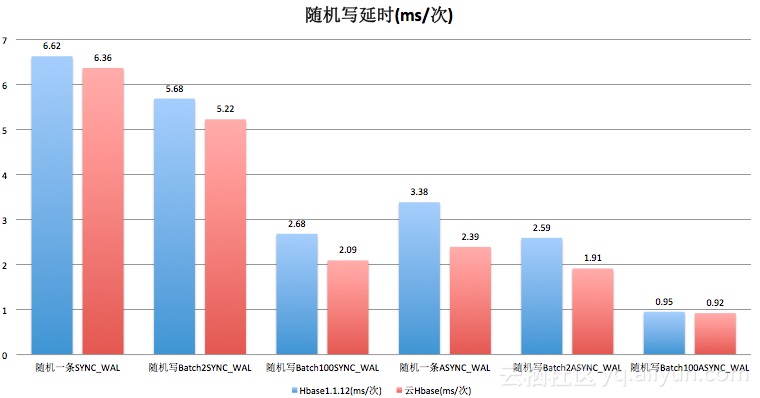
从数据结果来看,随机写情况下,BATCH 2条的性能和社区对比的话是比较不错的,性能有30%多的提升,这种情况下,网络消耗不会占很多,此外也不会像单条写那样消耗磁盘性能。
3.1.2顺序写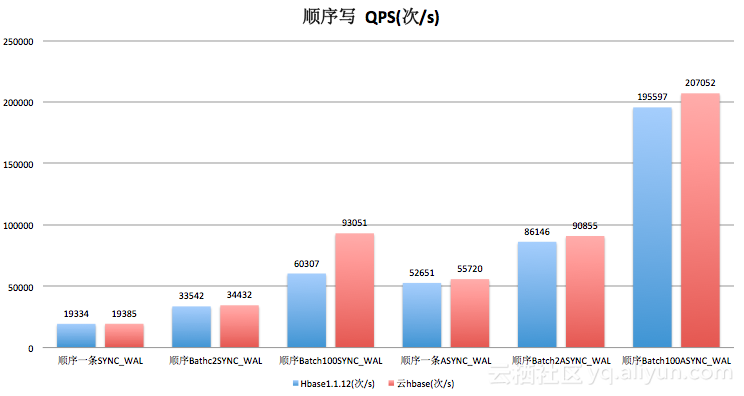
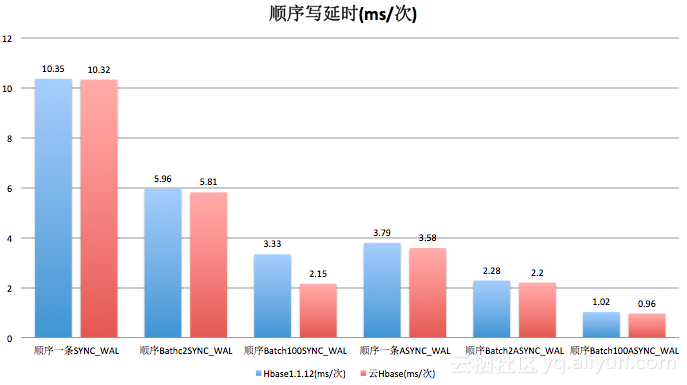
3.1.3.读/scan操作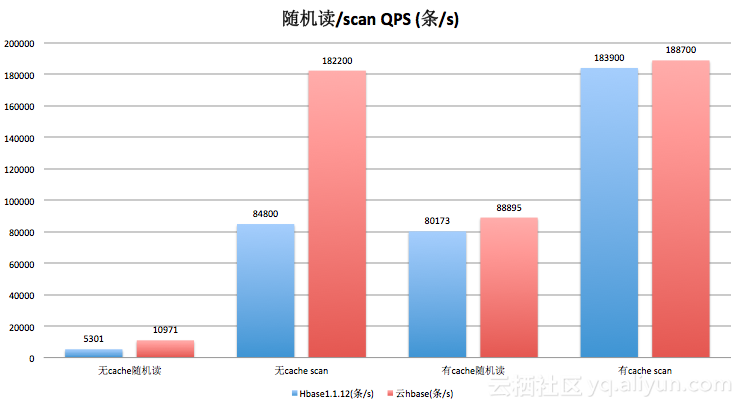
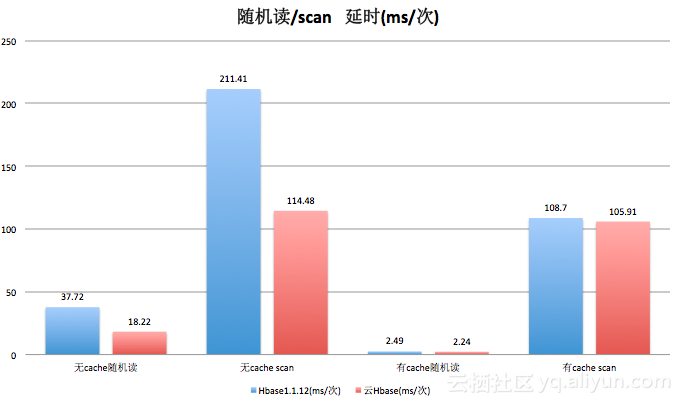
scan的时候的命中率受到cache的大小影响以及scan的条数的影响,这里使用默认的blockcachesize,scan100条数据,这里存在部分数据会请求文件系统的可能性,这里需要说明下。
上面几个图分布展示了我们对阿里云HBase 以及HBase1.1.12的测试数据,通过数据我们可以看出,阿里云HBase在读、写、scan场景下的性能比社区HBase(1.1.12)的性能都要高很多,大部分场景下的性能超过30%的提高,某些场景下甚至超过100%;就读、写、scan的延时数据来看阿里云HBase的读写/scan延时普遍比社区HBase快,某些场景下近1倍的速度。从测试性能上面看,阿里云HBase的性能还是很不错的。此外,上述测试是单rs下的读写scan,整体性能具有线性扩展能力。
此外,我们也在测试ApsaraDB for HBase 和 HBase1.2.6的性能,后续会给出二者的测试报告和详细数据。