3.5 MEMOIZE模块
本书不是关于Perl模块的内部细节的,而是关于一些Memoize模块内部使用的并和稍后要做的事情有直接联系的技术,所以现在简短地介绍一下。
Memoize得到一个函数名(或引用)作为它的参数。它制造一个新的函数,后者维护一个缓存并在其中查找它的参数。如果新的函数在缓存里找到了参数,就返回缓存的值;如果没找到,就调用原始函数,把返回的值保存入缓存,并把它返回给原始的主调者。
制造完这个新的函数,Memoize就把它装入Perl的符号表以代替原始的函数,那样当你认为你在调用原始函数的时候,其实你得到了新的带缓存管理的函数。
如果不去探究真实的Memoize模块的内部,即一个350行的怪物,那么将看一个小的、削减过的记忆器。要去除的最重要的东西是处理Perl符号表的代码部分(手动处理)。取而代之的是,我们将有一个memoize函数,它的参数是我们想要使之带记忆的子例程的引用,且它返回一个指向带记忆的版本(即缓存管理函数)的引用:
### Code Library: memoize
sub memoize {
my ($func) = @_;
my %cache;
my $stub = sub {
my $key = join ',', @_;
$cache{$key} = $func->(@_) unless exists $cache{$key};
return $cache{$key};
};
return $stub;
}
要调用它,首先用:
$fastfib = memoize(\&fib);
现在$fastfib就是带记忆版的fib()。为在符号表中装入带记忆版的fib()以代替原始的,要写fib = memoize(&fib)。在这个例子里,如果想快速计算Fibonacci数,那么安装是必要的。仅产生一个带记忆版的fib()是不够的,因为在fib()里面的递归调用是调用称为fib()的函数,直到对fib赋值之前,这仍然是旧的、慢的、不带记忆的版本。
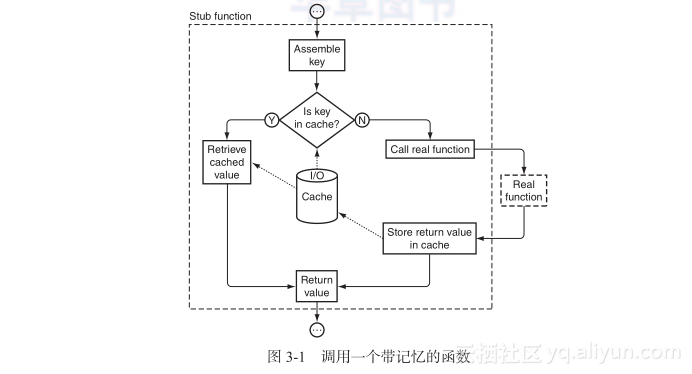
memoize如何工作?把一个指向fib的引用传递给memoize,然后它制造一个私有的%cache变量保存缓存的数据。然后产生一个存根函数(stub function),暂时保存在$stub,后者返回给主调者。这个存根函数就是实际上的带记忆版的fib,memoize的主调者回到一个指向它的引用,即在先前的例子里保存于$fastfib的。
当执行$fastfib时,实际上得到的是之前memoize制造的存根函数。这个存根函数把函数的参数用逗号连接在一起组成一个散列键,然后在缓存里看看这个键是否是熟悉的。如果是,存根立即返回缓存的值。
如果在散列中没找到这个散列键,存根函数就通过$func->(@_)执行原始的函数,得到结果,存入缓存,然后返回(图3-1)。
3.5.1 作用域和有效期
这里有一些细微的东西。首先,假设调用memoize(&fib)并得到$fastfib。然后调用使用$func的$fastfib。一个平常的问题是,为什么当memoize返回时,$func不会离开自己的作用域。
这个问题暴露了对作用域的一个普遍的误解。一个变量有两个组成部分:一个名字和一个值。当把一个值和一个名字关联在一起时,就得到一个变量。这样一个关联就称为一个绑定(binding),也称名字被绑定(bound)在它的值上。
在memoize返回后尝试使用$func,可能面临两个错误:值已经被销毁了,或者绑定已经改变了,以致名字指向了错误的值,或根本就没指向什么。
作用域
作用域(scope)是程序源代码的某部分,对其中某个绑定是有效的。在一个绑定的作用域内,名字和值是关联的;在此作用域外,绑定是在作用域外的(out of scope)并使得名字和值不再关联了。名字可能代表别的东西,或者根本什么也不代表。
当memoize启动时,my $func声明产生了一个新的标量变量值,并把名字$func绑定上了。my声明的名字的作用域,如$func,从my声明以后的句子开始,一直到最小的闭合块结束。在这个例子里,最小的闭合块就是标记着sub memoize。在这个块里面,$func指向刚产生的词法变量;在块外面,它指向别的东西,可能是不相关的全局变量$func。由于使用$func的存根在这个块里面,那里没有作用域问题,$func的作用域就在存根里面,名字$func也保持它的绑定。
在sub memoize块以外,$func意味着别的东西,但是存根是在块里面的,而不是在外面的。作用域是词法域的(lexical),也就是说这是个静态程序文本的属性,而不是某样东西执行次序的属性。事实上,存根在sub memoize块外调用(called)是不恰当的,它的代码“物理上存在于”$func绑定的作用域。
%cache的情况是一样的。
有效期
许多询问$func是否在作用域之外的人担心另一件事,不是作用域,而是很不一样的,称为有效期(duration)。一个值的有效期是在程序的运行期间是有效可用的。在Perl里,当一个值的有效期到了,它就被销毁,垃圾回收器使它的内存可供再次使用。
重要的是知道有效期几乎完全与名字无关,在Perl里,一个值的有效期持续到没有未完成的引用指向它。如果值是存放在一个具名变量里,那就算一个引用,然而还有其他种类的引用。例如:
my $x;
{
$x = 3;
my $r = \$x;
}
这里有一个标量其值是3。在块结束以后这里有两个引用指向它:

格子图(pad)是Perl在内部表示my变量绑定的数据结构。(对全局变量采用另一种数据结构。)一个指向3的引用来自格子图自身,因为名称$x被绑定到值3。另一个指向3的引用是来自绑定到$r的引用值。
当控制离开块时,$r就离开了作用域,因此$r到它的值的绑定就撤销了。在内部,Perl从格子图里删除了$r绑定:

现在没有引用指向曾经存放在$r的引用值。由于没有任何东西再指向它,它的有效期结束了,Perl立即销毁它:

这是典型的:一个变量的名字离开了作用域,随后它的值也立即被销毁了。多数在作用域和有效期之间的混淆可能是由这个简单实例的普遍性引起的。然而作用域和有效期并不总是结合紧密的,正如下面这个例子将显示的:
my $r;
{
my $x = 3;
$r = \$x;
}

当控制离开块时,$x的绑定就撤销了,$x也从格子里被删除:

与之前的例子不同,没有绑定的值依然无限期地存在,因为它仍然被绑定到所指向的$r的引用。它的有效期直到这个引用消失了才结束。
作用域和有效期的分离是Perl变量的一个本质属性。例如,Perl面向对象构造器函数的一段普通的模式:
sub new {
...
my %self;
...
return \%self;
}
这个构造器制造了一个散列,就是对象自身,然后返回一个指向散列的引用。即使名字%self离开了作用域,这个对象仍然会存留,只要主调者拥有一个指向它的引用。C语言中类似的代码就是错误的,因为在C语言里,一个自动变量的有效期结束于它的作用域:
/ This is C /
struct st_object *new(...) {
struct st_object self;
...
return &self; / expect a core dump /
}
现在回到memoize。当memoize返回时,$func的确已经离开作用域了。但是值没有被销毁,因为仍然有一个来自存根的未完成的引用。为真正理解将要发生什么,需要偷瞄一下Perl的内部(图3-2)。
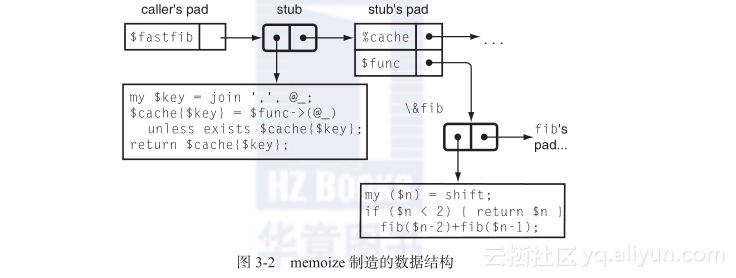
存根由图表顶部中间的双格子表示。在Perl中,这个格子称为一个CV,即“Code Value”,它是一个代码引用的内部表现形式。(绑定到$func的代码引用展示在图表的右边。)一个CV实质上是一对指针:一个指向子例程的代码,另一个指向子例程定义时被激活的格子。$func的绑定不会被销毁,直到所在的格子被销毁。格子不会被销毁,因为从CV有一个引用指向它。CV不会被销毁,因为主调者通过把它赋值给$fastfib而存放在自己的格子里了。
Perl知道存根可能在某天被调用,一旦如此,它会检查$func的值。只要存根存在,$func的值就必须被保持原样。一个指向存根的引用存放在$fastfib,只要引用在那里,存根就必须受到保护。类似地,缓存%cache坚持得和存根一样久。
3.5.2 词法闭包
现在另一点可能会混淆你。由于$func的值和存根坚持得一样久,如果第一次的存根尚存,那么第二次调用memoize,那会发生什么?第二次调用时对$func的赋值会不会破坏第一个存根使用的值呢?
答案是不会,一切都运作完美。这是因为Perl的匿名函数有个属性称为词法闭包(lexical closure)。当一个匿名函数产生后,Perl把它的格子打包,包括所有在作用域里的绑定,把它们附在CV上。一个以这种方式打包了环境的函数就称为一个闭包(closure)。
当存根被调用的,原先的环境暂时被恢复,而存根函数代码运行在存根定义时就生效的环境中。词法闭包意味着一个匿名函数不管到哪里都会携带它的天生的环境,就像我遇到过的一些游客一样。
第一次调用memoize,为使fib()带记忆,为了%cache和$func的绑定,建立了一个新的格子,新的存储空间分配给这些新的变量,$func也初始化了。然后创造了存根,格子贴上了存根的CV,然后CV(称为fastfib())返回给主调者。
现在第二次调用memoize,这次使quib()而不是使fib()带记忆(图3-3)。同样的,一个新的格子产生了,新的%cache和$func变量绑定在其中。一个CV(fastquib())产生了,包含一个指向新格子的指针。新的格子与附着在fastfib()上的格子完全无关。
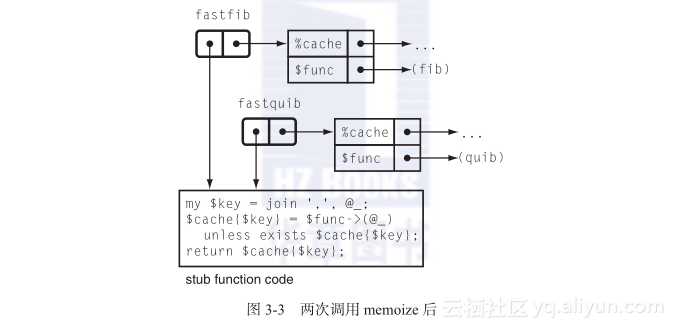
当执行fastfib时,fastfib的格子暂时保持,fastfib的代码被执行。代码使用了变量%cache和$func,这些是在fastfib的格子里查找的。也许此时有些数据存储在%cache。最后,fastfib返回,旧的格子重新生效。
然后执行fastquib,会发生几乎同样的事情。fastquib的格子恢复,带有它自己的%cache和$func。fastquib的代码运行,它也使用名为%cache和$func的变量。它们是在fastquib的格子里查找的,后者与fastfib的格子没有联系。存储在fastfib的%cache的数据也完全不会被fastquib获取。
因为CV的代码部分是只读的,它在几个CV之间分享。这节约了内存。当一个CV的有效期到了,它的格子就被垃圾回收。
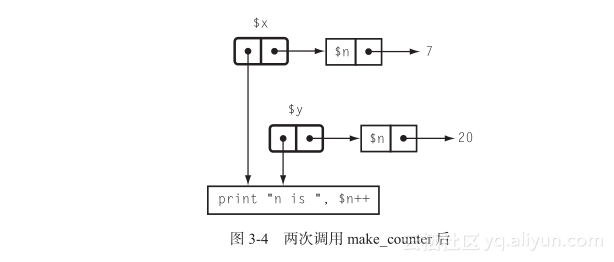
图3-4展示了一个简单的例子。
### Code Library: closure-example
sub make_counter {
my $n = shift;
return sub { print "n is ", $n++ };
}
my $x = make_counter(7);
my $y = make_counter(20);
$x->(); $x->(); $x->();
$y->(); $y->(); $y->();
$x->();
$x现在包含一个闭包,其代码是print "n is ",$n++而且该闭包的环境包含一个变量$n,设置成7。如果多次调用$x:
$x->(); $x->(); $x->();
结果如下:
n is 7
n is 8
n is 9
图3-5展示了新的图片。
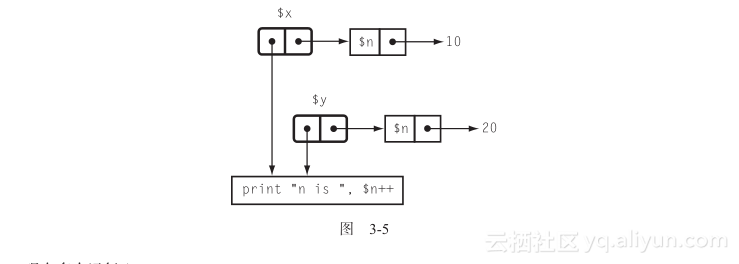
现在多次运行$y:
$y->(); $y->(); $y->();
运行的是同样的代码,但是这次是在$y的格子里查找名字$n而不是在$x的格子里:
n is 20
n is 21
n is 22
图3-6展示了新的图片。
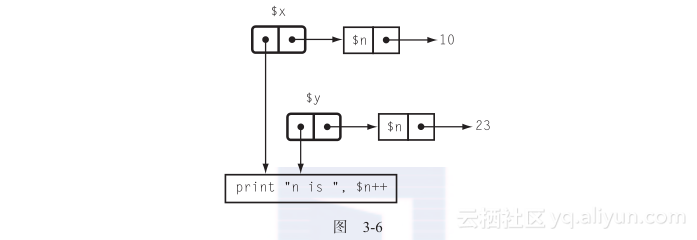
现在再次运行$x:
n is 10
这里的$n和前三次调用$x时的是一样的,它恢复了自己的值。
3.5.3 再谈记忆术
之前所有的讨论都是为了解释memoize函数能工作的原因。潇洒地把它当成小事抛之脑后,“它当然能工作啦!”,值得注意的是,在许多语言中,这是不会工作的而且也是无法做到的。几个重要的复杂的特征不得不共同起作用:延迟的垃圾回收、绑定,匿名子例程的生成,以及词法闭包。例如,如果尝试在C语言里实现一个像memoize的函数,你会受骗,因为C语言没有任何那些特征。(3.11节。)