本文讲的是后摩尔时代,如何给你的CPU减负,通用处理器(CPU)的摩尔定律已入暮年,而机器学习和Web服务的规模却在指数级增长。如何用硬件加速来提升性能、降低成本?下面我们一起来看看。

一、背景介绍
通用处理器(CPU)的摩尔定律已入暮年,而机器学习和Web服务的规模却在指数级增长。伴随着当今硬件技术的成熟发展,普通CPU无论是在计算能力,还是资源成本上相对于一些专用硬件已经没有绝对优势,这也促使硬件加速技术得到各大公司的青睐,譬如三大互联网巨头百度、阿里、腾讯内部的接入层采用类似KeyLess方案来加速HTTPS的卸载,不仅提高了用户体验,还节省了机器成本。根据当前调研结果发现:目前业内各大公司接入层针对于Gzip采用硬件加速还是一片空白,阿里接入层首次结合硬件加速技术卸载Gzip不仅带来了性能提升,而且对业界在此领域的发展也有重大影响意义。
接入层Tengine当前性能瓶颈是CPU,譬如Gzip模块在Tengine中CPU占比高达15%-20%左右,相比于其它模块CPU消耗高、占比呈增长趋势(后端应用压缩逻辑后续统一前置接入层)、且集中,所以Gzip模块使用硬件卸载对于性能提升、成本优化是不可或缺。
二、分析与调研
分析前先简单介绍下什么是硬件加速: 硬件加速(HardwareAcceleration)就是利用硬件模块来替代软件算法以充分利用硬件所固有的快速特性(硬件加速通常比软件算法的效率要高),从而达到性能提升、成本优化目的,当前主要是如下两大加速方式:
- FPGA 现场可编程门阵列,可针对某个具体的软件算法进行定制化编程,譬如业内的智能网卡;
- ASIC 专用集成电路,它是面向专门用途的电路、专门为一个用户设计和制造的,譬如Intel的QAT卡仅支持特定加减密、压缩算法;
FPGA与ASIC的对比如下表格所示:

2.1、接入层Tengine CPU消耗分析
主站接入层承载集团90%以上的入口流量,看似只是作为一个七层流量转发网关,但是却做了非常之多的事情,譬如https卸载及加速、单元化、智能流量转发策略、灰度分流、限流、安全防攻击、流量镜像、链路追踪、页面打点等等,这一系列功能的背后是Tengine众多模块的支持。由于功能点比较多,所以这就导致Tengine的CPU消耗比较分散,其主流程处理如下图所示:
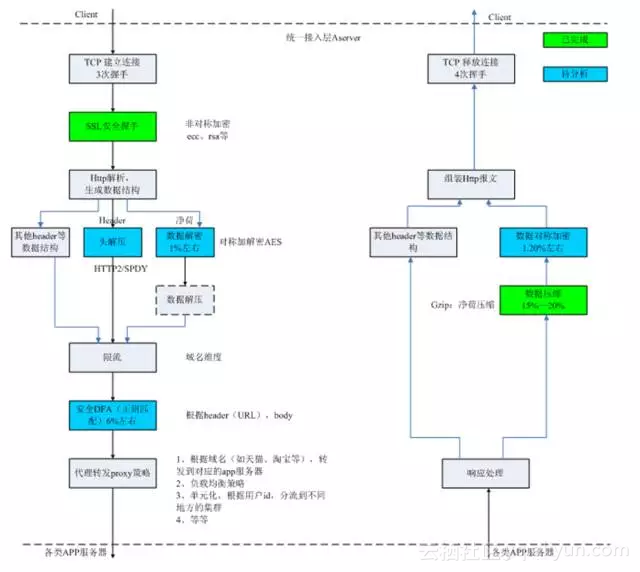
各模块CPU消耗占比Top 5如下表格所示:
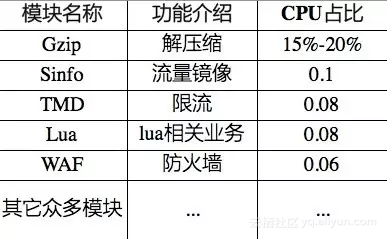
就当前接入层流量模型分析来看,Gzip单个模块CPU消耗占比达到15%-20%左右(注:主要是压缩消耗)且占比呈上升趋势,所以对Gzip使用硬件卸载迫在眉睫。
2.2、加速方案调研
2.2.1、Intel QAT卡
QAT(Quick Assist Technology)是Intel公司推出的一种专用硬件加速卡,不仅对SSL非对称加解密算法(RSA、ECDH、ECDSA、DH、DSA等)具有加速,而且对数据的压缩与解压也具有加速效果;
QAT加速卡提供zlib压缩算法、且zlib shim对其原生zlib与QAT之间做了适配,调用方式和zlib库方式基本一致,需在上层业务中开启zlib QAT模式、相对来说对上层业务改造较少。
2.2.2、智能网卡
INIC(Intelligent Network Interface Card)是网络研发事业部自研产品,以网络处理器为核心的高性能网络接入卡,对于网络报文数据的处理非常合适,针对Tengine的gzip卸载有如下两种方案:
a. 提供压缩API给host,把压缩数据返回host,由host封包发送;
b. host和网卡约定压缩flag,host发送未压缩报文,智能网卡收到后进行压缩,并且重新封包发送;
2.2.3、FPGA卡
FPGA(Field-Programmable Gate Array)现场可编程门阵列,需要对接入层使用的zlib算法使用硬件语言重新开发、进行电路烧写,且上层交互驱动也需要从零开发;
方案对比
智能网卡的方案1相比于QAT对zlib处理没有性能上的优势,智能网卡只是对zlib进行软件卸载、相对于QAT并不具有加速作用;其方案2需要把Tengine一部分业务逻辑抽取到网卡中做:如spdy、http2、chunked、ssl对称加密、响应body限速等逻辑,其成本及风险高,方案3的FPGA方式相对来说开发成本较高、且相关资源匮乏。
综上所述最终采用QAT加速卡对接入层Tengine的Gzip进行卸载、加速。
三、方案实施
QAT驱动采用UIO(UserspaceI/O)技术,其大部分处于用户态、只有少部分处理硬件中断应答等逻辑处于内核态,这样不仅方便用户调试,而且还解决了内核不支持浮点数运算的问题。当然QAT加速卡也顺应了Docker虚拟化的潮流,其采用SRIOV技术,可以在虚拟机之间高效共享PCIe(Peripheral Component Interconnect Express)设备,当前DH895XCC系列芯片最高可支持32个虚拟机共享QAT,从而达到充分利用硬件资源。其次QAT属于ASIC模式相比于FPGA具有更好的加速效果,主要原因是由于FPGA为了可重构,导致其逻辑查找表、触发器众多以及相同逻辑电路在布线上延时变大。
接入层Tengine目前采用的是下图左边的实线加速链路,其中Zlib Shim、QAT User Space Api、QAT Driver作为Tengine Gzip与底层硬件QAT的通信适配层,此方式对上层业务入侵较小、其软件架构如下图所示:
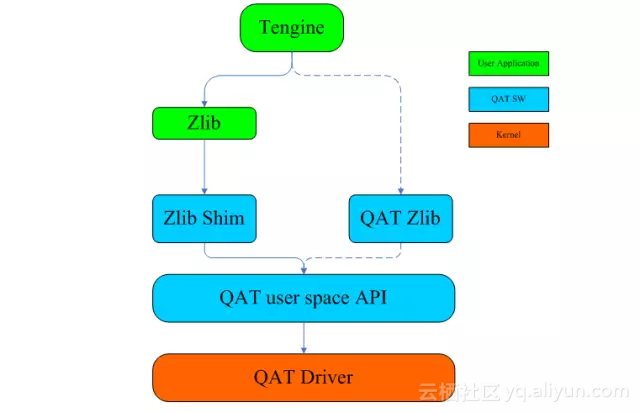
虽然该方案看起来比较简单,但是真正线上实施的时候还是遇到了非常多的问题(功能、性能方面),譬如:
3.1、架构不合理
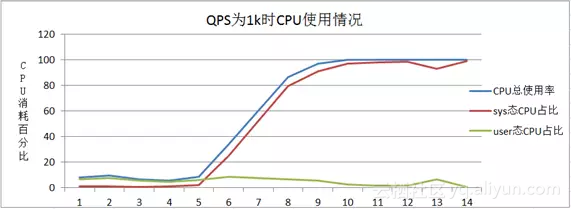
a. 使用的第一版驱动Intel-Qat2.6.0-60,当QPS为1k左右时CPU很快打满(注:正常情况下QPS为1k时,CPU消耗6%左右),且CPU消耗中90%以上都是消耗在内核态,如下图所示:
使用strace进行相关系统热点函数统计发现,其CPU主要消耗在ioctl系统函数上,如下所示:
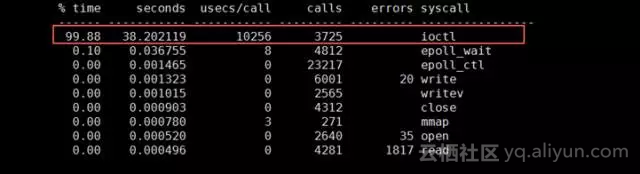
通过perf查看ioctl主要是执行内存分配命令,由于Zlib Shim需要开辟连续的物理内存、所以出现频繁调用 compact_zone进行内碎片整理,其调用热的高达88.096%,如下图所示(注:热度表示该函数该函数自身的热度、调出: 表示被调用函数的热度总和、总体: 热度 + 调出):
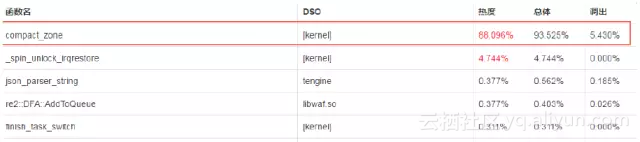
同Intel研发联调讨论后发现是由于当前Intel QAT的Zlib Shim的模型不合理所导致,通过推动其改造采用OOT的内存管理模块USDM(内部维护一个HugePage内存池)方案解决。
b. 使用上述问题解决后的驱动intel-qatOOT31092,测试后发现CPU节省效果不佳(用户态CPU减少、但是增加了内核态的CPU),经分析、发现使用QAT加速后,部分系统函数CPU占比变高,如 open、ioctl、futex,如下图所示(注:左边的是使用QAT后各系统热点函数),使用QAT后open、ioctl、futex执行时间占比高达8.95(注:3.91 + 2.68 + 2.36),而未使用版本对应占比时间才0.44(注:0.24 + 0.14 + 0.06);
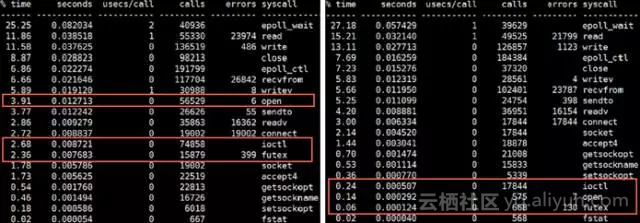
分析其Tengine的worker进程堆栈信息发现open、ioctl都是成对出现(即一次http请求出现4次该系统调用),该现象反馈给Intel的研发同学后得知是由于新驱动的Zlib Shim导致,通过优化改造后open、ioctl调用频率明显减少。但是其futex系统调用频度却没有减少,还是导致内核态的CPU占比较高,通过strace跟踪发现一个http压缩请求后会多次调用futex、如下图所示,同Intel研发同学了解到Zlib Shim采用多线程方式,其futex操作来自zlib shim等待QAT压缩或解压缩数据返回的逻辑。
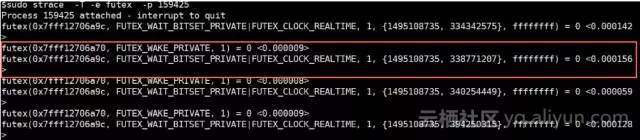
由于Tengine是多进程单线程、采用epoll异步IO事件模式,联调Intel的研发同学对Zlib Shim进行改造(去线程),最终futex系统调用也明显减少。
通过分析并推动Intel对QAT进行多次架构上的改造,才使得QAT的加速特性更好的发挥。
3.2、功能不完善
a. 使用QAT后执行reload,可能导致请求响应异常,如下所示:

由于每个worker进程都需要分配一个QAT Instance用于数据解压缩,Tengine在reload的瞬间worker进程数可能会翻倍、而QAT Instance初始版本只有64个、所以新启动的worker进程可能分配不到Instance、导致请求失败。
针对此问题Intel提供的新版本QAT,其Instance数量从64提高到256个避免此问题的发生,同时我们提出容灾保护方案:当Instance无法分配了需要自动降级为软件压缩,提高其可用性。
b. Zlib Shim huge page内存泄漏,导致QAT驱动core dump:
Tengine使用内存池模式进行内存的管理,即调用(In)DeflateInit分配的空间无需调用(In)DeflateEnd处理、在请求结束的时候会调用请求r相关的释放操作,进行内存的归还,但是由于Zlib Shim使用的huge page必须调用(In)DeflateEnd才释放给USDM,通过改造Tengine Gzip相关代码后,该问题得以解决,而QAT驱动的core dump也是由于hugepage的泄漏导致无法成功分配导致。
c. Zlib Shim状态机不完善导致特定场景下的压缩、解压缩请求异常,等众多问题就不一一介绍。
一路走来,通过无数次的性能优化、功能测试,多次同Intel研发同学一起探讨之后,才使得QAT在功能、性能、架构方面等众多问题得以快速解决,下面就准备上线前期准备工作。
3.3、运维梳理
部署发布
采用单rpm软件包、双二进制模式,从而降低软件版与硬件加速版之间的耦合度,自动识别部署机器是否开启QAT,并选择正确的二进制执行;
容灾保护
运行过程中由于某种资源的缺乏导致硬件加速版本Gzip执行失败,将会自动切换为软件版本、待资源可用时自动切换到硬件加速版本;
可维护与监控
虽然上线前做过一系列压测、稳定性并未出现异常,但对硬件加速的相关资源指标进行实时监控还是必不可少;
四、加速效果
测试机器
cpu型号:Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz 32核 内核:2.6.32 Zlib版本:zlib-1.2.8 QAT驱动版本:intel-qatOOT40052
数据对比
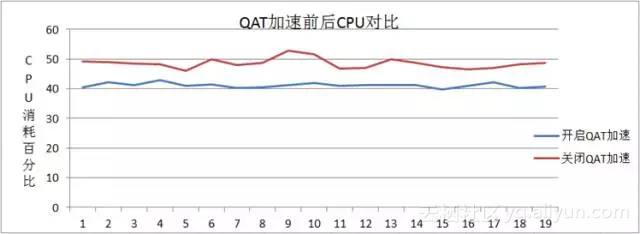
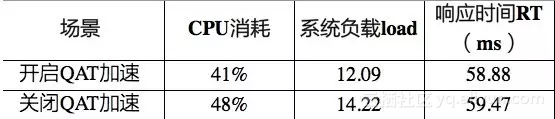
同等条件下,开启QAT加速后CPU平均值为41%左右,未开启QAT加速的CPU平均值为48%左右,如下图所示:
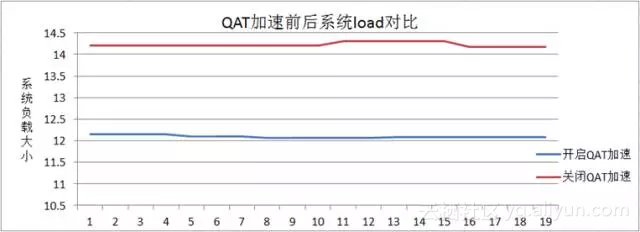
相同条件下,开启QAT加速后系统load平均值为12.09,关闭QAT加速时系统load平均值为14.22,如下图所示:
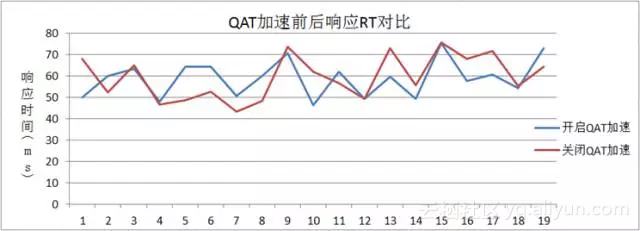
相同条件下,开启与关闭QAT加速后,响应RT波动不相上下,如下所示:
同等条件下,各模块热点函数图对比如下所示,其中红色圈中的是Gzip相关函数
(注:左侧是开启QAT加速):
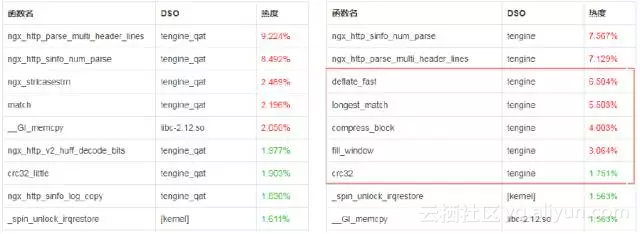
同比条件下Tengine Gzip使用QAT加速卡后,CPU消耗从48%下降到41%,系统负载load下降2个,且根据模块热点函数图对比发现Gzip基本上已经完全卸载。
结论
综上数据对比,当qps为10k左右时Tengine Gzip使用QAT加速后CPU节省15%左右,且Gzip基本上完全卸载、随着其占比变高,优化效果将越好。
五、总结
接入层Tengine Gzip硬件加速项目是阿里存储技术Tair&Tengine团队及服务器研发计算团队与英特尔数据中心网络平台团队齐心协力下的产物,不仅带来了性能提升,而且使得接入层在硬件加速领域再次打下了坚实的基础、为明年SSL+Gzip架构上整合做好了沉淀,同时也填充了业内接入层对Gzip采用硬件加速的空白,对此领域的发展具有一定的影响意义。
来源:阿里技术
原文链接