2017年架构师最重要的48个小时 | 8折倒计时

这是本坑的第三篇,之前已经说了关于 HashSet 和 BitMap 了,这次说说 Bloom Filter 布隆过滤器,要是还不知道前面讲了啥的,可以点一下下面的连接看看。
我们都知道BitMap已经非常节省空间了,一个值只需要一个 bit 就可以进行统计了,但是,对于上百亿的数据来说,碰撞率即使非常低,但也不是一个可以忽视的问题了。
当时提出这个问题,一个是因为垃圾电子邮箱,每天少说都有几十亿的垃圾邮箱在发垃圾邮件,把这些邮件直接全部都存储起来,不是一个经济的做法。使用 BitMap 来进行存储吧,碰撞的次数太多,很多正常的邮件都被标记为黑名单邮件,很是难受。
另外一个是因为 Google 的爬虫,在进行链接抓取的时候,为了效率,都要知道哪些链接抓过哪些没抓过,一开始也是用的 BitMap ,但是碰撞的链接太多,导致很多链接都无法抓到,导致很多网页都没法被搜录,也很是难受。
怎么办呢?空间时间已经使用到极致了,hash算法也选择了能尽量平均分配到整个数组的 bit 里面了。大神Burtom Bloom 发明了一个布隆算法。
这个算法的存储结构跟 BitMap 是相同的,区别在于它使用了多个 Hash 算法,一个字符串经过N个 Hash 算法会生成多个 Hash 值,如果N个值的 bit位 都为1 ,才判定该字符串已经存在。
比如字符串 “小蕉写得这么给力你不点个赞吗”,经过 Hash 算法1、Hash 算法2、Hash 算法3,生成了数字,1、11、21。
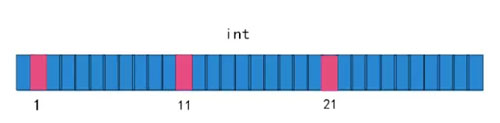
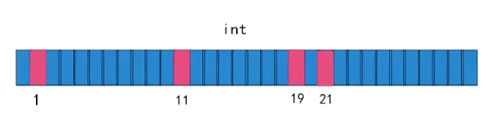
这时候又来了一个字符串 “小蕉写得这么给力你不点个赞”,经过 Hash 算法1、Hash 算法2、Hash 算法3、生成了数字,1,11,19。
发现,咦,没有全部出现,所以该字符串没有出现过。
就这样,一个 Bloom Filter 就构造完了,每次只需要生成N个值就可以判定该字符串有没有存在过了,经过严格的数学推导,只需要 8 个 Hash 函数,就可以把Bloom Filter 的错误率降低到一个非常低的值,非常可靠。
我们这样想,即使真的真的真的那么巧,k-1个Hash函数的值都一样,只要第k个不一样,那这个算法依然会把它当成新的元素。这样就解决了 BitMap 误判率高的问题了,时间复杂度也只是根据所选Hash函数的个数线性增长。
本文作者:大蕉
来源:51CTO