发布和订阅
(使用java 客户端)
在先前的指南中,我们创建了一个工作队列。这工作队列后面的假想是每一个任务都被准确的传递给工作者。在这部分我们将会做一些完全不同的事情–我们将一个消息传递给多个消费者。这部分被认知为“发布和订阅”。
为了说明这个部分,我们会建立一个简单德日志系统,它是由两个程序组成–第一个发出日志消息,第二个接收和打印它们。
在我们的日志系统中,每一个运行的接收者拷贝程序将会获得信息。通过这个方式我们可以运行一个接收者,直接的把日志记录到硬盘中;在同一时间我们可以运行另一个接收者,在屏幕上看这些日志。
本质上,发布日志消息等同于广播到所有接收者。
交换
在先前指南部分,我们将消息发送到队列里,并从队列中接收消息。现在是时候介绍RabbitMQ中全消息模型。
让我们快速温习下在先前指南中我们掌握的:
一个发送消息的生产者是一个用户程序。
一个存储消息的队列是一个缓冲。
一个接收消息的消费者是一个用户程序。
在RabbitMQ消息模型中核心的思想是生产者从不直接将消息发送给队列。实际上,生产者常常甚至不知道是否一个消息会被传递到队列中。
相反,生产者仅能将消息发送到一个交换机。一个交换机是一个非常简单的事物。在它的一遍,它从生产者那里接收消息,另一边将消息推送到队列中。这个
交换所必须清楚的知道它所接收到的消息要如何处理。是否将它附加到一个特别的队列中?是否将它附加到多个队列中?或者是否它应该被丢弃。规则的定义是由交
换类型决定的。 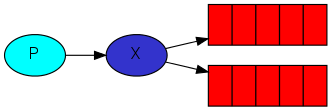
有几个交换类型:direct,topic,deaders,fanout。我们来关注最后一个–fanout。让我们创建一个这种类型的交换机并且称呼它为logs:
channel.exchangeDeclare("logs", "fanout");
这fanout交换机是非常简单的。通过这个名字你可能已经猜出它的用处了,它会将接收的所有消息都广播到所有它所知道的所有队列。这个真正是我们的记录器所需要的。
交换机列表
为了列出服务器中所有交换机,你可以运行着有用的rabbitmqctl:$ sudo rabbitmqctl list_exchanges Listing exchanges ... direct amq.direct direct amq.fanout fanout amq.headers headers amq.match headers amq.rabbitmq.log topic amq.rabbitmq.trace topic amq.topic topic logs fanout ...done.在这个列表里有一些以
amq.打头的交换机和默认(未命名)的交换机。这些是默认创建的,但是不太可能你会在某个时刻使用它们。
匿名交换机
在先前的指南中我们对交换机毫无了解,但是我们依旧能将消息发送到队列中。那是可能实现的,因为我们使用的是默认交换机,通过我们使用空字符串(““)标识它。
回想一下我们以前是如何发送消息的:channel.basicPublish("", "hello", null, message.getBytes());这第一个参数是交换机的名字。空字符串说明它是默认的或者匿名的交换机:路由关键字存在的话,消息通过路由关键字的名字路由到特定的队列上。
现在,我们可以发布我们自己命名的交换机:
channel.basicPublish( "logs", "", null, message.getBytes());
临时队列
你可能会想起先前我们使用的队列是有特定的名字的(是否记得hello和task_queue)。命名一个队列对我们来说是至关重要的–我们需要指定工作者到这相同的队列上。当你想把队列分享给生产者和消费者,给队列名是重要的。
但是那不是我们记录器的实例。我们想监听所有日志消息,不仅仅是它们中的子集。我们同样是对当前的消息流感兴趣,而不是旧的。为了解决这个我们需要两件事。
首先,无论我们什么时候连接RabbitMQ,我们需要一个新的,空的队列。为了做到这些,我们可以创建一个随机名字的队列或者更胜一筹-让服务器为我们选择一个随机的名字。
第二部,一旦我们将消费者的连接断开,队列应该自动删除。
在Java客户端里,当我们使用无参数调用queueDeclare()方法,我们创建一个自动产生的名字,不持久化,独占的,自动删除的队列。
String queueName = channel.queueDeclare().getQueue();
在这点,队列名中包含一个随机队列名。例如名字像amq.gen-JzTY20BRgKO-HjmUJj0wLg。
绑定

我们已经创建了一个fanout交换机和队列。现在我们需要告诉交换机发送消息给我们的队列上。这交换机和队列之间的关系称之为一个绑定。
channel.queueBind(queueName, "logs", "");
从现在开始,日志交换所将要附加消息到我们的队列中。
绑定列表
你可以列出存在的绑定使用,使用rabbitmqctl list_bindings。
把所有放在一起
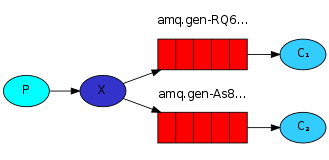
这发送日志消息的生产者程序,跟以前指南中的程序没有多少不同。这最重要的改变是我们将匿名的交换机替换为我们想要消息发布到的日志交换机。当发送是我们需要申请一个路由关键字,但是在广播消息是它的值会被忽略。这是EmitLog.java程序的代码:
import java.io.IOException;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.Channel;
public class EmitLog {
private static final String EXCHANGE_NAME = "logs";
public static void main(String[] argv)
throws java.io.IOException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, "fanout");
String message = getMessage(argv);
channel.basicPublish(EXCHANGE_NAME, "", null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
channel.close();
connection.close();
}
//...
}
(EmitLog.java source)
如你所知,建立连接后我们声明一个交换机。这个步骤是必须的,因为发布到一个不存在的交换机是禁止的。
如果队列还没有绑定到交换机上,消息将会丢失,但是这个对我们来说是ok的;如果没有消费者正在监听,我们可以安全的丢弃消息。 ReceiveLogs.java代码:
java.lang.InterruptedException {
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.QueueingConsumer;
public class ReceiveLogs {
private static final String EXCHANGE_NAME = "logs";
public static void main(String[] argv)
throws java.io.IOException,
java.lang.InterruptedException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, "fanout");
String queueName = channel.queueDeclare().getQueue();
channel.queueBind(queueName, EXCHANGE_NAME, "");
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
QueueingConsumer consumer = new QueueingConsumer(channel);
channel.basicConsume(queueName, true, consumer);
while (true) {
QueueingConsumer.Delivery delivery = consumer.nextDelivery();
String message = new String(delivery.getBody());
System.out.println(" [x] Received '" + message + "'");
}
}
}
(ReceiveLogs.java source)
如以前那样编译,我们已经做了。
$ javac -cp rabbitmq-client.jar EmitLog.java ReceiveLogs.java
如果你想把日志保存到文件中,仅仅打开一个控制平台,键入:
$ java -cp .:commons-io-1.2.jar:commons-cli-1.1.jar:rabbitmq-client.jar ReceiveLogs > logs_from_rabbit.log
如果你想在你的屏幕上看这些日志, 新建一个终端并且运行:
$ java -cp .:commons-io-1.2.jar:commons-cli-1.1.jar:rabbitmq-client.jar ReceiveLogs
当然,为了发出日志键入:
$ java -cp .:commons-io-1.2.jar:commons-cli-1.1.jar:rabbitmq-client.jar EmitLog
使用rabbitmactl list_bindings你可以验证这代码确实创建绑定和我们想要的队列。随着两个ReceiveLogs.java程序的运行你可以看到一些如:
$ sudo rabbitmqctl list_bindings
Listing bindings ...
logs exchange amq.gen-JzTY20BRgKO-HjmUJj0wLg queue []
logs exchange amq.gen-vso0PVvyiRIL2WoV3i48Yg queue []
...done.
这结果的解释是直白简单的:来自交换机的日志流向服务器安排的两个队列中。并且那确实我们所期望的。
为了弄明白如何监听一个消息的子集,让我们移到指南的第四部分。