1 系列
- 整体架构图
- producer端发送消息
- broker端接收消息
- broker端消息的存储
- consumer消费消息
- 分布式事务的实现
- 定时消息的实现
- 关于顺序消费
- 关于重复消息
- 关于高可用
2 整体架构图
先来看下官方给出的整体架构图
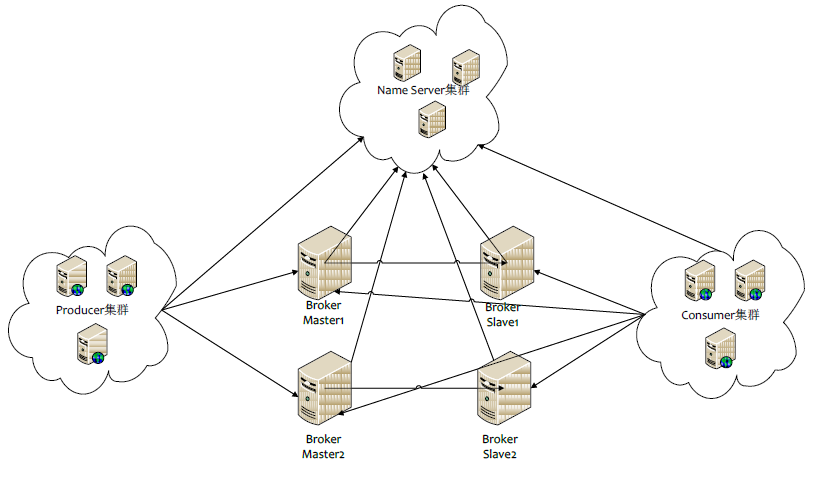
- Producer集群:拥有相同的producerGroup,一般来讲,Producer不必要有集群的概念,这里的集群仅仅在RocketMQ的分布式事务中有用到
- Name Server集群:提供topic的路由信息,路由信息数据存储在内存中,broker会定时的发送路由信息到nameserver中的每一个机器,来进行更新,所以name server集群可以简单理解为无状态(实际情况下可能存在每个nameserver机器上的数据有短暂的不一致现象,但是通过定时更新,大部分情况下都是一致的)
- broker集群:一个集群有一个统一的名字,即brokerClusterName,默认是DefaultCluster。一个集群下有多个master,每个master下有多个slave。master和slave算是一组,拥有相同的brokerName,不同的brokerId,master的brokerId是0,而slave则是大于0的值。master和slave之间可以进行同步复制或者是异步复制。
- consumer集群:拥有相同的consumerGroup。
下面来说说他们之间的通信关系
- Producer和Name Server:每一个Producer会与Name Server集群中的一台机器建立TCP连接,会从这台Name Server上拉取路由信息。
- Producer和broker:Producer会和它要发送的topic相关的master类型的broker建立TCP连接,用于发送消息以及定时的心跳信息。broker中会记录该Producer的信息,供查询使用
- broker与Name Server:broker(不管是master还是slave)会和每一台Name Server机器来建立TCP连接。broker在启动的时候会注册自己配置的topic信息到Name Server集群的每一台机器中。即每一台Name Server都有该broker的topic的配置信息。master与master之间无连接,master与slave之间有连接
- Consumer和Name Server:每一个Consumer会和Name Server集群中的一台机器建立TCP连接,会从这台Name Server上拉取路由信息,进行负载均衡
- Consumer和broker:Consumer可以与master或者slave的broker建立TCP连接来进行消费消息,Consumer也会向它所消费的broker发送心跳信息,供broker记录。
3 kafka的架构图
来看下kafka的整体架构图
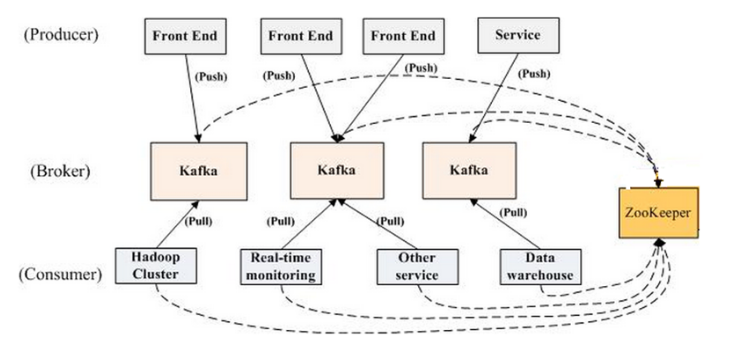
来看看他们之间的连接关系
- Producer和broker:Producer会和它所要发送的topic相关的broker建立TCP连接,并通过broker进行其他broker的发现(这个没有依赖ZooKeeper进行服务发现)
- broker和ZooKeeper:broker会将自己注册在ZooKeeper上,同时依赖ZooKeeper做一些分布式协调
- Consumer和ZooKeeper:Consumer会将自己注册在ZooKeeper上,同时依赖ZooKeeper进行broker发现以及将消费offset记录在ZooKeeper上
- Consumer和Broker:Consumer连接topic相关的broker进行消息的消费
4 RocketMQ和kafka的对比
4.1 消息的存储
我们知道topic是一类消息的统称,为了提高消息的写入和读取并发能力,将一个topic的消息进行拆分,可以分散到多个broker中。kafka上称为分区,而RocketMQ称为队列。
对于kafka:为了防止一个分区的消息文件过大,会拆分成一个个固定大小的文件,所以一个分区就对应了一个目录。分区与分区之间是相互隔离的。
对于RocketMQ:则是所有topic的数据混在一起进行存储,默认超过1G的话,则重新创建一个新的文件。消息的写入过程即写入该混杂的文件中,然后又有一个线程服务,在不断的读取分析该混杂文件,将消息进行分拣,然后存储在对应队列目录中(存储的是简要信息,如消息在混杂文件中的offset,消息大小等)
所以RocketMQ需要2次寻找,第一次先找队列中的消息概要信息,拿到概要信息中的offset,根据这个offset再到混杂文件中找到想要的消息。而kafka则只需要直接读取分区中的文件即可得到想要的消息。
看下这里给出的RocketMQ的日志文件图片分布式开放消息系统(RocketMQ)的原理与实践
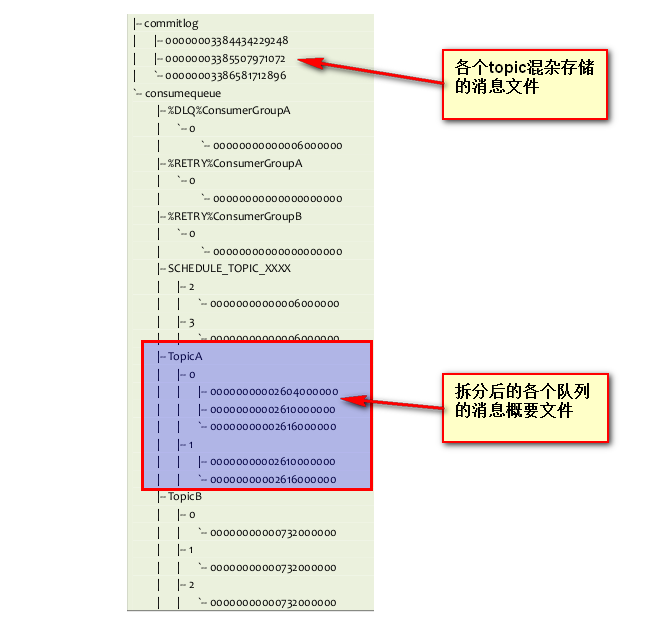
这里我自己认为RocketMQ的做法还是值得商榷的,这样的做法在同步刷盘、异步刷盘时效率相对高些(由于量大所以效率相对高些),但是全部的topic往一个文件里面写,每次写入要进行加锁控制,本来不相干的topic却相互影响,就降低的写入的效率。这个锁的粒度有点大了,我自己认为应该一个队列对应一个CommitLog,这样做就是减少锁的粒度问题。
4.1 Prdocuer端的服务发现
就是Producer端如何来发现新的broker地址。
对于kafka来说:Producer端需要配置broker的列表地址,Producer也从一个broker中来更新broker列表地址(从中发现新加入的broker)。
对于RocketMQ来说:Producer端需要Name Server的列表地址,同时还可以定时从一个HTTP地址中来获取最新的Name Server的列表地址,然后从其中的一台Name Server来获取全部的路由信息,从中发现新的broker。
4.1 消费offset的存储
对于kafka:Consumer将消费的offset定时存储到ZooKeeper上,利用ZooKeeper保障了offset的高可用问题。
对于RocketMQ:Consumer将消费的offset定时存储到broker所在的机器上,这个broker优先是master,如果master挂了的话,则会选择slave来存储,broker也是将这些offset定时刷新到本地磁盘上,同时slave会定时的访问master来获取这些offset。
4.2 consumer负载均衡
对于负载均衡,在出现分区或者队列增加或者减少的时候、Consumer增加或者减少的时候都会进行reblance操作。
对于RocketMQ:客户端自己会定时对所有的topic的进行reblance操作,对于每个topic,会从broker获取所有Consumer列表,从broker获取队列列表,按照负载均衡策略,计算各自负责哪些队列。这种就要求进行负载均衡的时候,各个Consumer获取的数据是一致的,不然不同的Consumer的reblance结果就不同。
对于kafka:kafka之前也是客户端自己进行reblance,依靠ZooKeeper的监听,来监听上述2种情况的出现,一旦出现则进行reblance。现在的版本则将这个reblance操作转移到了broker端来做,不但解决了RocketMQ上述的问题,同时减轻了客户端的操作,是的客户端更加轻量级,减少了和其他语言集成的工作量。详细见这篇文章Kafka设计解析(四):Kafka Consumer解析
4.3 Name Server和ZooKeeper
Name Server和ZooKeeper的作用大致是相同的,从宏观上来看,Name Server做的东西很少,就是保存一些运行数据,Name Server之间不互连,这就需要broker端连接所有的Name Server,运行数据的改动要发送到每一个Name Server来保证运行数据的一致性(这个一致性确实有点弱),这样就变成了Name Server很轻量级,但是broker端就要做更多的东西了。
而ZooKeeper呢,broker只需要连接其中的一台机器,运行数据分发、一致性都交给了ZooKeeper来完成。
目前先就这几个大的组件进行简单的对比,后续会对某些细节进行详细说明。