从我使用 C++ 代码完成了不同编译器的基准测试到现在,已经有一段时间了。由于我最近发布了 ETL 项目的 1.1
版(一个具有表达式模板的优化矩阵/向量计算库),所以我决定使用它作为我的基准测试的基版本。它是一个带有大量模板的 C++ 14
库。我要编译完整的测试套件(124 个测试用例)。这是直接在最新版本(1.1)的代码上完成的。我将在调试模式下编译一次,并在
release_debug(release + debug 符号和断言)下进行一次编译,并记录每个编译器的执行时间。该测试将使用支持 ETL
中的每个选项的配置进行编译,以此计算最大的编译时间。每次编译都使用四个线程(make -j4)。
我还做了一些基准测试,以了解每个编译器生成的代码间的运行时的性能差异。基准测试将编译为发布模式,并记录其编译时间。
我将测试以下编译器:
- GCC-4.9.4
- GCC-5.4.0
- GCC-6.3.0
- GCC-7.1.0
- clang-3.9.1
- clang-4.0.1
- zapcc-1.0 (商业版,基于 clang-5.0 主分支)
所有这些都是直接使用 Portage(Gentoo 软件包管理器)安装的,除了从源代码安装的 clang-4.0.1 以及没有
Gentoo 软件包的 zapcc。由于 Gentoo 上的 clang
包不支持多进程,所以我不得不从源代码中安装一个版本,从包管理器中安装另一个版本。这也是我测试较少版本的 clang 的原因,更实用点。
为了实现这些测试的目标,所有编译器都使用了完全相同的选项。通常,我在 clang 上使用比 GCC 更多不同的选项(主要是考虑到在
clang 上更严格的向量化选项)。这可能不会使得每个编译器达到最佳性能,但可以对使用默认优化级别的输出之间进行比较。以下是使用的主要选项:
- 调试模式下: -g
- 发布+调试模式下: -g -O2
- 发布模式下: -g -O3 -DNDEBUG -fomit-frame-pointer
每种情况都启用了许多警告,ETL 选项也是一样的。
所有的测试结果都是运行在 Intel Core i7-2600(Sandy Bridge ...)@ 3.4GHz 上的 Gentoo
机器上收集的,该机器具有 4 核和 8 线程、12G 的 RAM 和一个
SSD。我尽可能地从干扰项中分离出基准数据,并且我的基准代码是相当健全的,但是有些结果可能并不完全准确。此外,一些基准测试是在使用多线程,这可能会增加一些干扰和不可预测性。当我对测试结果不太确定时,我会多次运行基准测试以对此确认,并且总体而言,我对结果很有信心。
编译时间
让我们从编译器自身的性能结果开始:
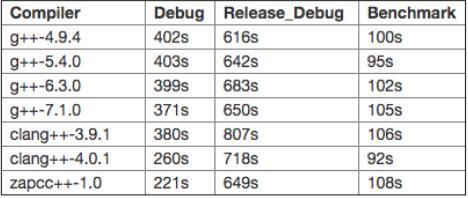
注: 在 Release_Debug 和 Benchmark,我对 zapcc 只使用了三个线程, 因为 12Go 的内存对于四个线程并不足够。
不同的编译器之间有一些非常重要的区别。总地来说,clang-4.0.1
是迄今为止调试模式下最快的免费编译器。然而,当测试代码被添加优化选项加以编译,clang
就落后了。在调试模式和发布模式下,clang-4.0.1 比 clang-3.9.1 快得多,这一点令人印象深刻。在这一点上 clang
团队干得不错!这些优化,使得 clang-4.0.1 在发布模式下几乎与 gcc-7.1 平分秋色。对于 GCC
来说,优化的成本似乎一直在显著地上升。然而, GCC 7.1 似乎使得优化加快,也使得标准编译快了许多。如果我们考虑
zapcc,这是调试模式下最快的编译器,但它的速度在发布模式下比几个 gcc 版本要慢。
总地来说,我对 clang-4.0.1 的性能印象深刻,它看起来真快!在不久的将来,我一定会用这个新版本做更多的测试。看到 g++-7.1
的编译速度确实快于 gcc-6.3,也同样令人欣慰。然而,对优化而言,最快的 gcc 版本仍然是 gcc-4.9.4 ,这已经是一个对
C++ 标准低支持的老版本。
运行时性能
现在来看看生成的代码的质量。对于一些基准测试,我已经包含了两个版本的算法。 std 是最简单的算法(原始版),vec 是手工向量化和优化的实现版本。所有的测试都是在单精度浮点上完成的。
点乘
运行的第一个基准是计算两个向量之间的点积。让我们先看看原始版的性能:

不同的编译器之间的差异不是很大。基于 clang 的编译器似乎是生成速度最快代码的编译器。有趣的是,gcc-6.3 似乎在大数据量的容器中有一个很大的性能衰减,但在 gcc-7.1 中已经解决了。

如果我们查看优化版本的结果,其中差异更小。同样,基于 clang 的编译器生成的可执行文件是最快的,但紧随其后的是 gcc,除了 gcc-6.3 之外,我们仍然可以看到与之前相同的性能衰退。
Logistic Sigmoid
下一个测试是检查 sigmoid 操作的性能。在这种情况下,库的评估者将尝试使用并行化和向量化来计算。让我们看看不同编译器的开销如何:

有趣的是,我们可以看到,gcc-7.1 在少量数据时是最快的,而 clang-4.0
最适合生成较大数据时的代码。然而,除了最大的向量大小,差异并不是很明显。显然,zapcc(或 clang-5.0)有一个回归,因为它比
clang-4.0 慢,并与 clang-3.9 相同速度。
Y = Alpha * X + Y (axpy)
第三个基准是著名的 axpy(y = alpha * x + y)。这是完全由库中的表达式模板决定的,没有使用特定的算法。我们来看看结果:

即使是最大的 vector,一旦向量化和并行化之后,这也是一个非常快速的操作。以这种速度,观察到的一些差异可能不是很重要。再次,基于 clang 的版本是这段代码中最快的版本,但差异还是很小。在 gcc-7.1 中似乎还有一点回归,但这也是相当小的。
矩阵间的乘法 (GEMM)
下一个基准测试是测试 Matrix-Matrix 乘法的性能,这是在 BLAS 命名中被称为 GEMM 的操作。在这种情况下,我们同时测试原始的和优化的向量化实现。为了节省一些横向空间,我把表分成两部分。

这一次,不同编译器之间的性能差异非常大。clang 编译器现在是大幅度领先,其中 clang-4.0
是他们中最快的(也有不错的提升幅度)。事实上,clang-4.0.1 生成代码,平均比最好的 GCC
编译器生成的代码速度快两倍。非常有趣的是,从 GCC-5.4 开始,我们可以看到一个巨大的性能衰退,而且这种衰退还在 GCC-7.1
中。事实上,测试版本中最好的 GCC 版本依然是 GCC-4.9.4。Clang 真的在编译 GEMM 代码方面做得很好。

至于优化的版本,这两大家族是相反的。的确,GCC 在这方面做的工作比 clang
要好,尽管差距没有以前那么大了,但还是值得注意。我们还是可以观察到 GCC 版本中的一个小回归,因为 4.9 版本依然是最快的。至于
clang 版本,似乎 clang-5.0 (在 zapcc 中使用)在这个例子中有了很多的性能改进。
在这个例子中矩阵相乘,它是非常令人印象深刻的,优化与非优化代码在性能上差异非常巨大。并且,令人印象深刻的是,每种类型的编译器都有它们的长处,clang 看起来更适合处理没优化过的代码,而 GCC 更适合处理向量化的代码。
作者:佚名
来源:51CTO