标签(空格分隔): QCon
10.17-10.19在上海度过了Qcon的三天。今年的Qcon主题非常的散,这也是近两年无论ArchSummit还是QCon的一个特点,基本涵盖了以互联网技术为主的所有领域。
我个人主要关注还是云计算、机器学习和大数据相关的话题,因此主要参与的topic也集中于此。本文就印象深刻的一些展开一点分享。
会场第一个关注的话题,是复旦危辉教授讲的人工智能的一个概述,怎么说呢?这个topic在这个时候回看,是整个QCon我个人认为最棒的topic,偏哲学层面,主要纠正了一些大家对AI的认知,同时也再次强调了要正确认识DeepLearning。可惜这块没有PPT,真心无法传播分享其精髓了。
机器学习应用
理解为算法应用好了,其实方法论确实是大同小异,只是场景的不同,可以看出不同的技术团队在各自场景中的一些取舍。
可配置系统的性能学习
首先看一个例子——《可配置系统的性能学习》。华东理工大学的AP做了基于机器学习来调整可配置系统的参数,期望获取复杂参数系统中“最优”运行的参数组合。因为复杂的参数组合有组合爆炸的问题,在期望有较好性能的情况下能调节有效参数,对于复杂配置系统有很大帮助。具体的一个solution是通用的机器学习方法论,如下图: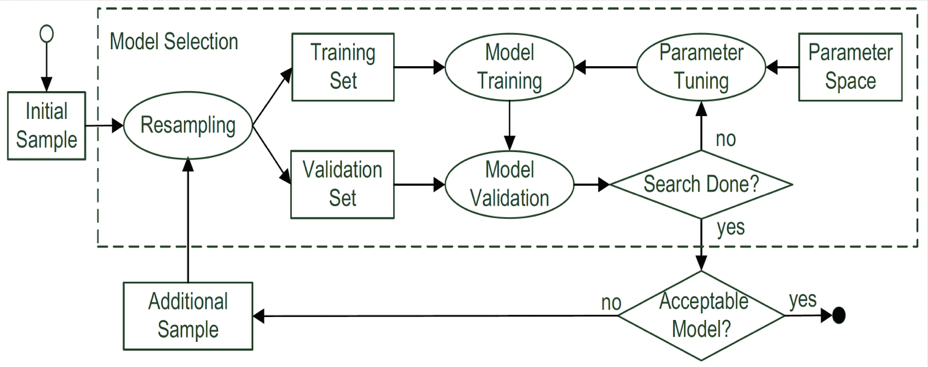
唯品金融机器学习
唯品金融的同学分享了他们的机器学习实战经验,比较贴地气。有个谈法挺朴实——没有高大上,面向业务的机器学习。
唯品金融在4大产品方向上做尝试。

当然这些也不是都实现了,分享的讲师提到了一个有意思的话题:算法平台vs算法应用,那他也展示了在唯品金融,算法应用和平台又是如何建设的。
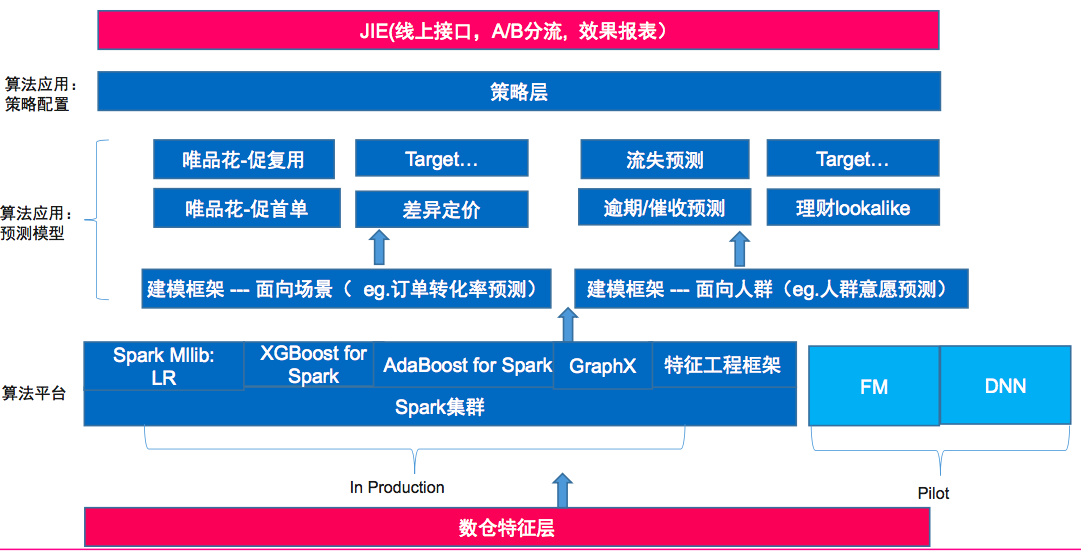
可以看到平台、应用(预测模型)和策略层(人工干预)很清晰的分层。anyway无论高大上与否,我认为这是一种正确且cost based的架构。
携程度假智能云客服平台
毕竟在客服团队,看到客服平台还是忍不住去听了一下。携程的客服场景对应于CCO体系内,业务模式其实主要对标飞猪。其现状
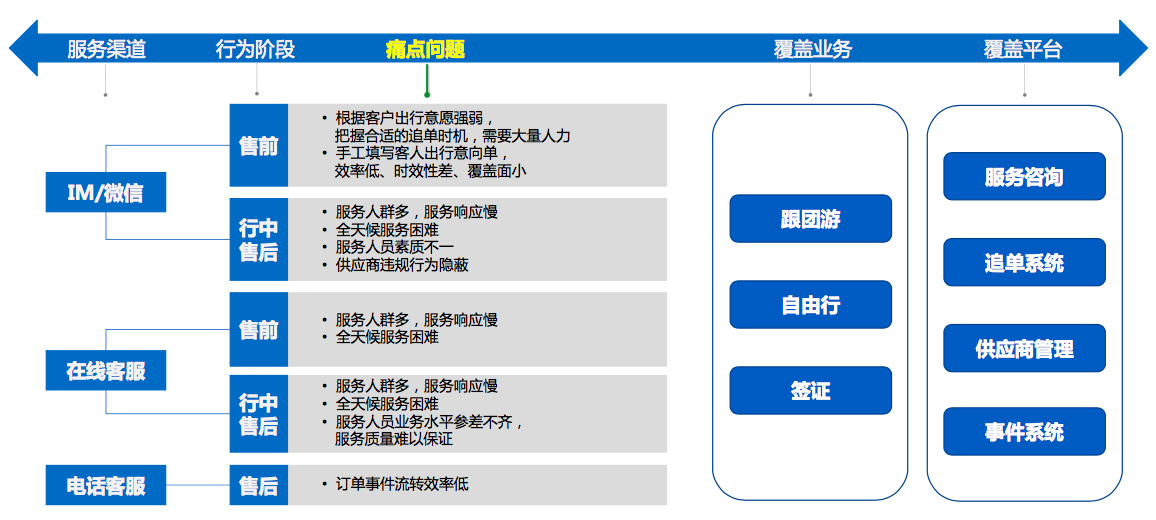
也是在解决多渠道(热线、在线)多环节(售前、行中、售后)的各种咨询和维权问题。那么面对复杂业务场景,携程度假做了一层业务抽象

可以看到,对于智能问答、智能分配、预警,与我们集团CCO的技术产品有同质性,也就是说在客服场景中,如此复杂的业务逻辑,必须通过几个核心步骤和域划分开。其中对于用户意愿的持续追踪,我觉得与我们当前团队做的主动服务以及小蜜团队的障碍预测很类似。就是要基于数据在用户动作前预知到用户的意图。具体如何做的呢?很遗憾,演讲者没有细节深入,只有一个架构图粗略的描述了整体系统的模块划分。不得不说太遗憾了。
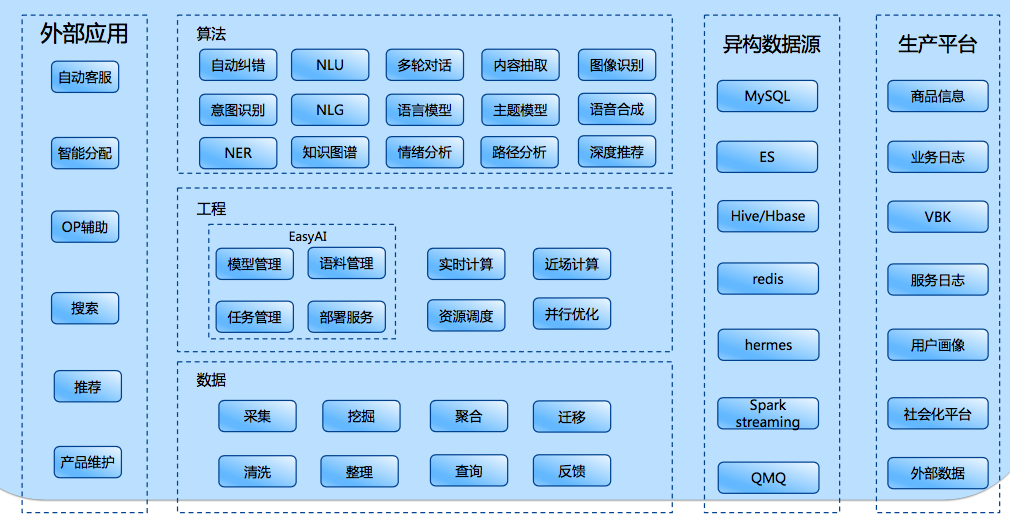
这里演讲者着重讲了携程自己做的Easy AI平台,看UI截图其实功能很简单,就是集成了标注和一些model的管理。算是工程层面的一个特色吧。
TensorFlow与深度学习
这个topic是Google Brain团队带来的,主要是TF的特性介绍,几个新特性比较吸引人,如微博上前段时间比较火的eager execution,还有auto learning的Learn2learn。我对后者比较感兴趣,这里截了一些图片简单介绍。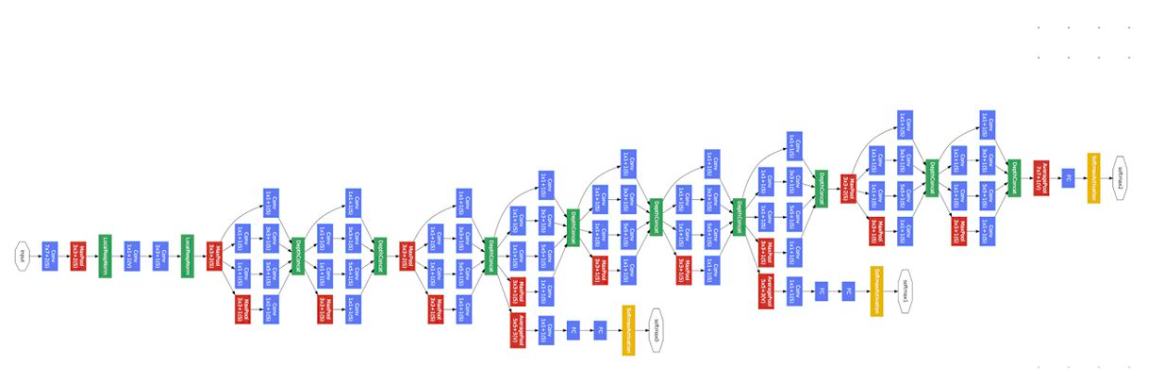
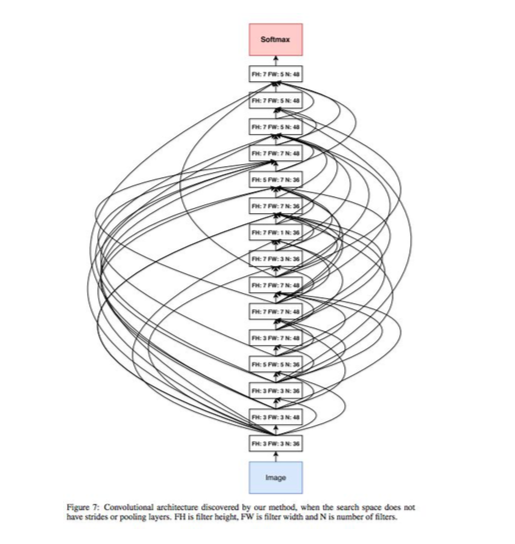
如上图这样的复杂网络,是很难炼丹完成的,那么learn2learn可以解决这类问题,一个主要方法就是迭代优选。就像去年和寿哥团队简单了解autolearning一样,基本就是需要迭代来尝试。
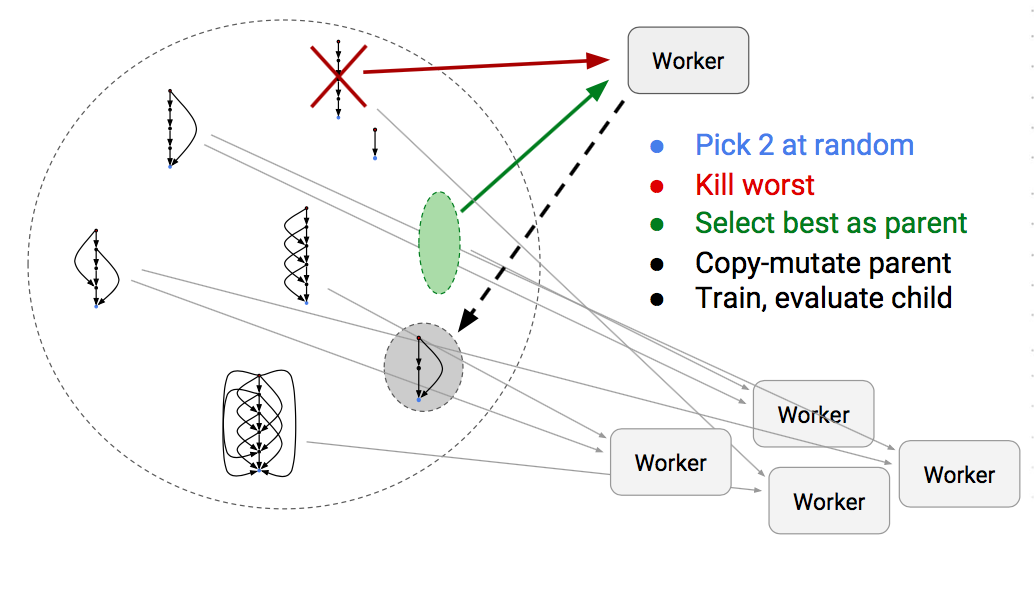
TF的learn2learn能力据说还不错,很快可以搞出一个性能不错的net。
Pinterest如何利用机器学习实现两亿月活跃用户
这是硅谷专场的一个topic,Pinterest的同学分享了一个推荐rank的系统演化。算是比较经典吧,而且进度和集团手淘的千人千面也差不多。基本上第一阶段都是规则策略,然后演化为线性模型,接下来GBDT用boost组合的方式来优化,到如今演化到DeepLearning。
其首页的推荐核心是个性化主页
核心问题是
系统演化刚开始的规则(基于时间)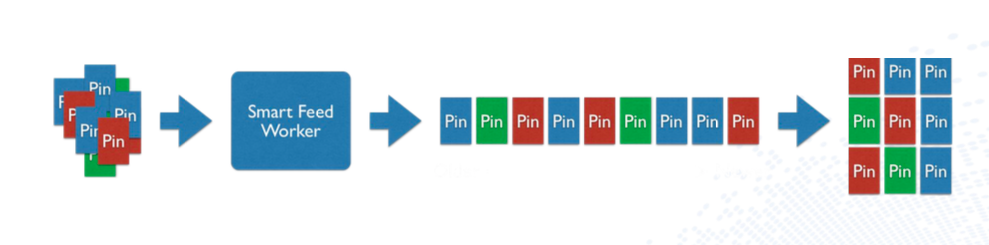
线性预测(LR、500+稀疏特征)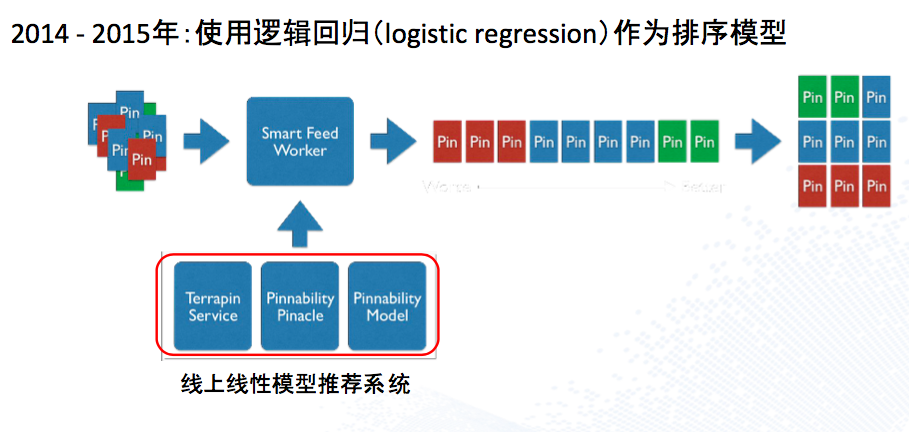
GBDT(XGboost、深度7、700+特征)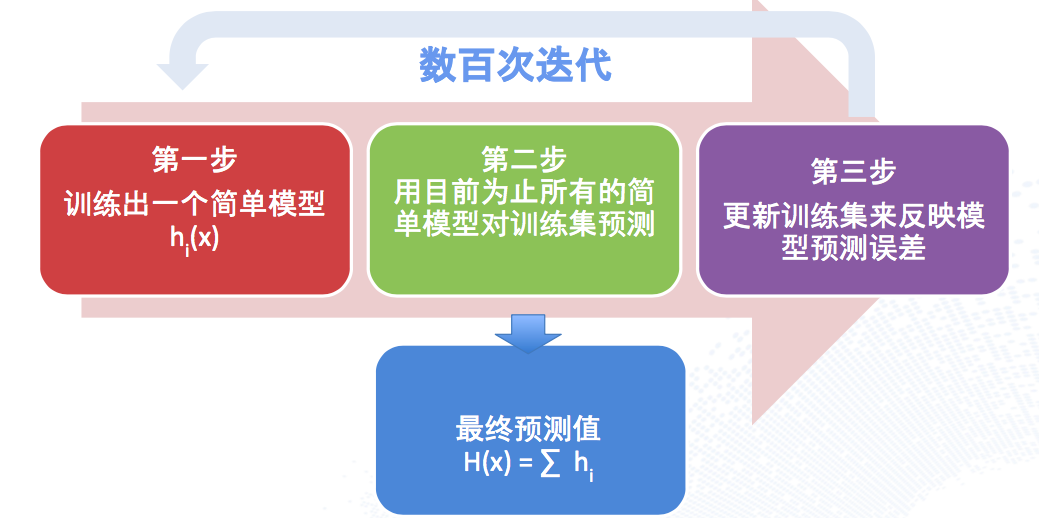
DL(TensorFlow、1层embeding+4层全连接的神经网络、ReLu+SigmoidGate混合神经元)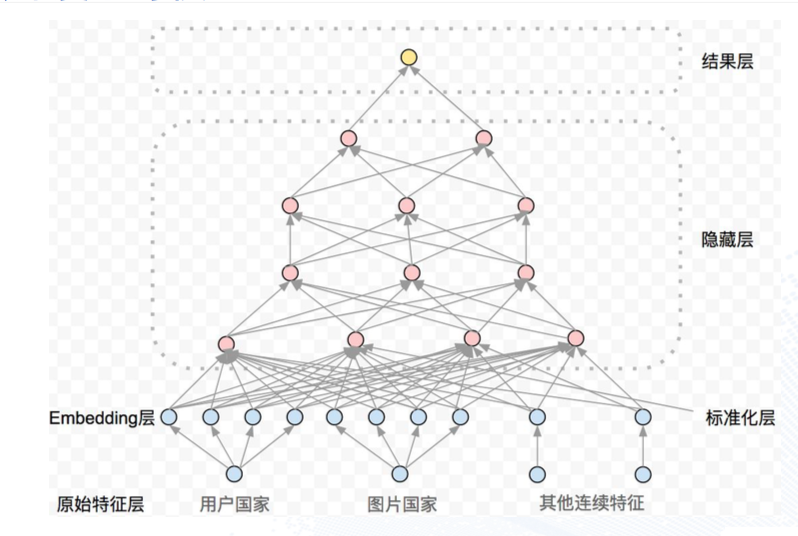
系统演化
最后的总结还是不错的。线性模型不能很好的利用高维复杂特征,另外cross feature都要手工做,同时用户特征(年龄、性别等)对于模型无意义,因为不同的user-item pair,user维度是一致的。那GBDT其实是演讲者最推崇的一个模型,因为这个模型对于性能的提升是巨大的,且有效的探索和丰富了特征空间,能做特征分析的算法,我个人也倾向于应该是一种合理的算法(符合人类直觉),我相信如果不是DEEPLearning太火,Pinterest的首页推荐应该就是GBDT了。因为讲者自己也说了,GBDT的离散特征处理不足的问题,也可以通过加embedding解决。
大数据
最后还是要谈回大数据,之前archsummit思考里就讲过离线计算的大数据架构已经是一个稳态架构,果然在2017大家已经不谈了,实时计算出现了稳定的专场占据着大数据专场的一个固定席位。今年的实时主要是阿里的介绍为主,包含Blink Sql和毅行的Porshe,因为内部有更多机会了解,因此没去。主要听了一个talkingData的内存计算和Linkedin的系统分享。
基于内存的分布式计算
这个话题扯的太大了,其实TalkingData就是在做我4年前在无线和一群小伙伴做的事,实时计算uv。他们提到的架构主要是用bitmap来去重,而bitmap又是以blob的结构存mysql的,导致binlog巨大。因此提出一个改进的方案在内存中分布式的存储来计算。大体流程是这样:

这个blade就是核心的内存计算框架,大体集群包含
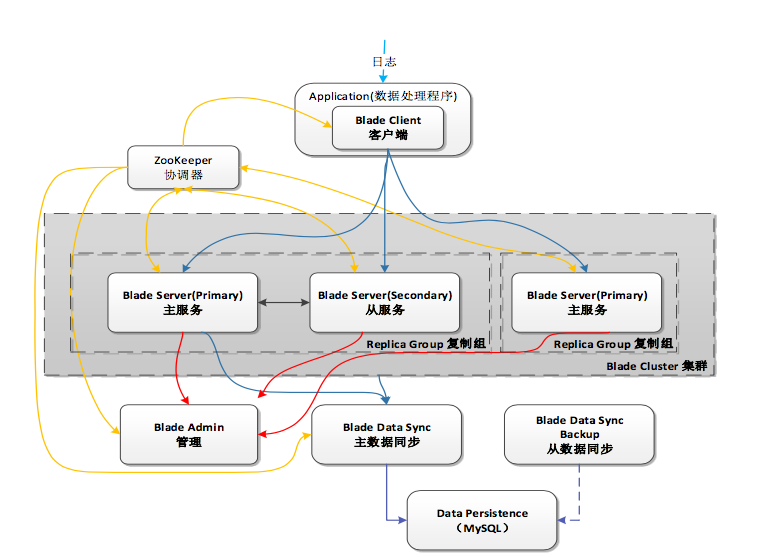
这里主从是双写的,也无法解决完全的高可用,只能是相比老系统提高。这里当时会场有很多人有疑问,不过没有深入细究。
Building Invisible Data Infrastructure at LinkedIn
linkedin的这个topic话题很大,不过主要介绍了两个开源的系统:Helix和Nuage。
topic开始先普及了一下分布式系统,介绍了一些难点:
Helix主要是负责做分布式的集群管理,而Nuage则关注云平台。Helix的抽象主要面向Node和机器,管理的资源就是Database和Job。主要的资源状态包括master、slave、online和offline。核心通过zk来协调,有个spectator负责做资源mapping。细节比如如何高可用的利用zk,没有仔细讲。主要架构简图如下:
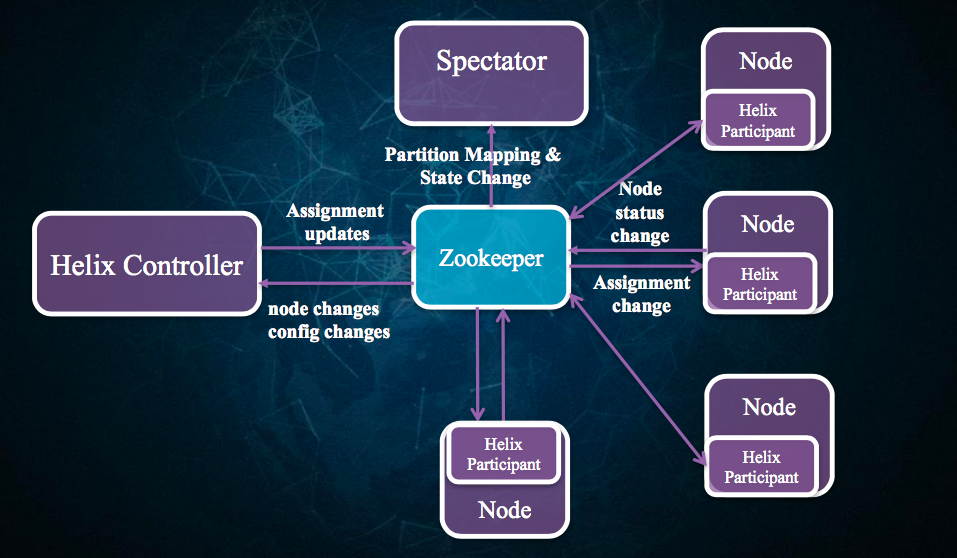
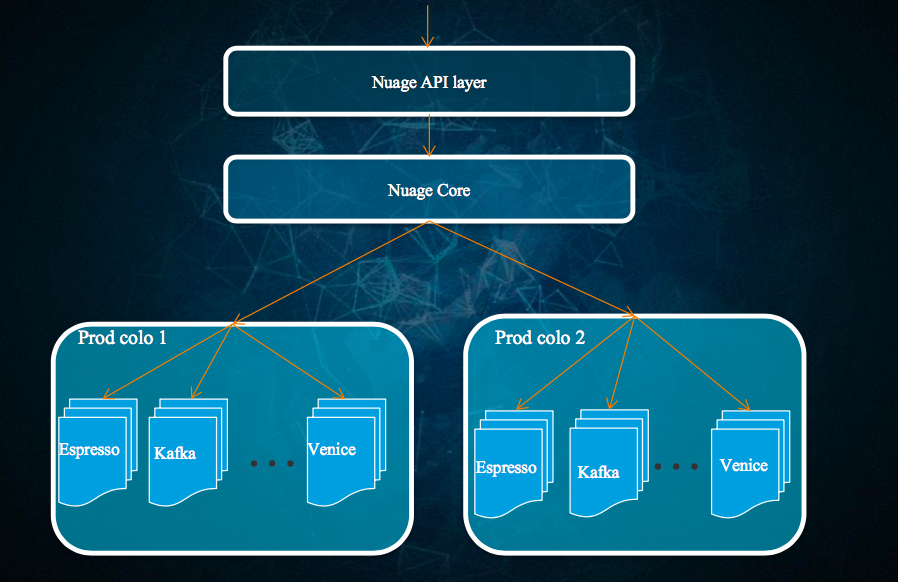
Helix照演讲者介绍来看,基本管理了linkedin的全部db资源,不仅是关系数据库,包括文档数据库、kv数据库、OLAP数据库都是通过helix管理的。而Nuage更像一个管理平台,Nuage本意就是法语的cloud的意思。其提出两个核心概念——Automation、Self-service,这个听起来很好。而Nuage的目标也是做这样的事情。让开发和运维过程更自动化和自服务,降低犯错的可能性,统一审批和安全流程、一致的监控和告警、做容量预估,anyway,这样的管理平台可想象的空间真的很大。这两年看到集团内部这么多的基础运维平台出现,如果打包合并,就是Ali的Nuage。智能自动化运维不是梦。
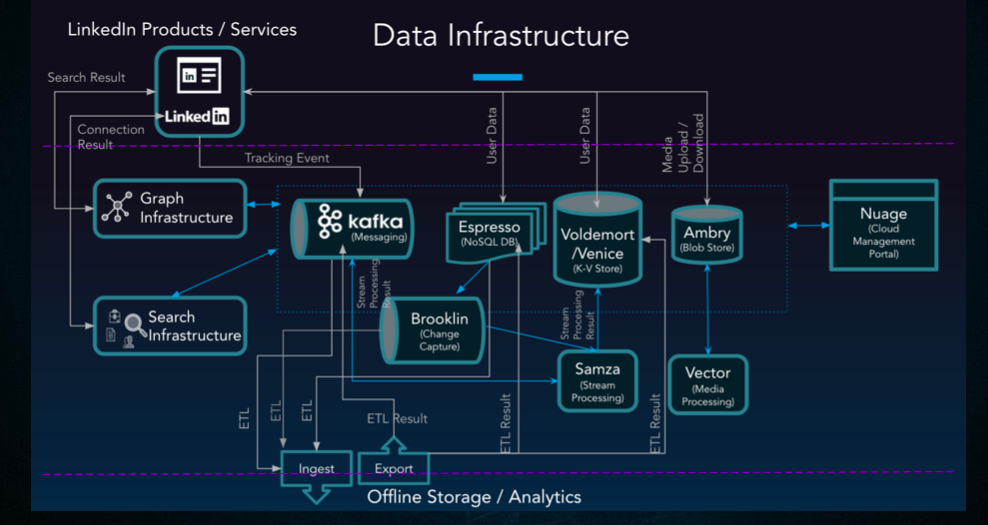
最后附一个LinkedIn的data infrastructure图结束。外加一句总结:大数据离线&实时架构稳定了、高可用高并发互联网架构稳定了、机器学习的套路也算固定了,后面会是什么呢?我非常看好Robotics,including chatbot。
Reference
- 会议大多数ppt的下载地址:http://ppt.geekbang.org/qconsh2017