问题引入
这天老鸟又开始纠缠着菜鸟:“菜鸟啊,我们最近遇到一个RDS SQL Server 2008 R2的奇怪的问题,我们的生僻字写入到RDS SQL Server中,查询结果展示出来是乱码呀?你去解决下这个问题吧。”。
“可是,鸟哥,我最近在做关于SQLTest的系列文章啊,暂时抽不出。。。。。。”。
“那个暂时先放放,这个比较紧急,尽快,立刻,马上去复盘并解决掉,Understand?”。还没等菜鸟说完,老鸟已经迫不及待的发号施令了。
复盘分析
看到老鸟为这事着急上火的样子,菜鸟已经意识到问题的严重性,于是放下手中的活,赶紧投入到这个问题的复盘分析中来。
复盘
经过一番翻云覆雨的研究后,菜鸟拿出了复盘的例子来,参见下面的代码:
use tempdb
go
IF OBJECT_ID('#temp', 'U') IS NOT NULL
DROP TABLE #temp
GO
create table #temp(
firstName varchar(10)
)
insert into #temp
select '䅇'
union all
select '库'
;
select * from #temp
查询结果如下图所示: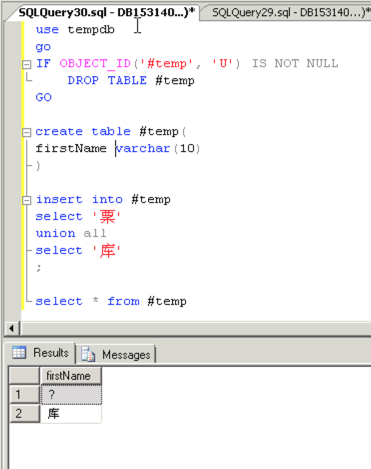
分析
从查询结果展示来看,生僻字“䅇 (su)” 的确显示为乱码问号(?)。菜鸟终于复盘了老鸟说得场景,但是他还是高兴不起来。难道RDS SQL Server 2008R2真如鸟哥所说,对生僻字不支持吗?高端大气上档次的阿里云RDS SQL Server不至于吧?随着研究的深入,菜鸟渐渐的找到问题的根本原因:
SQL Server是使用Unicode编码的数据类型来支持中文的,比如:NCHAR, NVARCHAR等数据类型,类似的语言还有拉丁语系,和包含中文在内的亚洲语言。所以,要解决这问题,我们的数据类型选择就必须是Unicode编码的数据类型,很显然复盘例子中的数据类型VARCHAR选择错误,我们只需要将这个数据类型修改为NVARCHAR,即可解决问题了。
解决问题
在正确分析了问题所在以后,解决问题就变得很简单了,参见下面的测试代码:
use tempdb
go
IF OBJECT_ID('#temp', 'U') IS NOT NULL
DROP TABLE #temp
GO
create table #temp(
firstName nvarchar(10)
)
insert into #temp
select N'䅇'
union all
select N'库'
;
select * from #temp
测试结果展示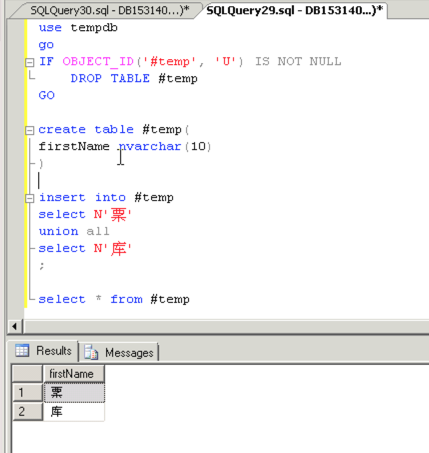
从结果展示来看,生僻字“䅇 (su)”已经可以成功展示出来了,这里需要特别强调两点,否则很有可能展示出来还是乱码:
- 数据类型选择请务必使用Unicode编码格式的类型,这里选择的是NVARCHAR。
- 在向Unicode编码格式的数据类型插入数据时,需要使用前置词N。N前置词代表的是 SQL-92标淮中的国家语言,且N必须为大写。如果您没有在Unicode字串常数前面加上N做为前置词,则SQL Server会在使用字串前,先将其转换成目前资料库的非Unicode 字码页。
写在最后
至此,菜鸟成功复盘并解决了RDS SQL Server 2008 R2遭遇生僻字乱码的问题。又开始回过头来继续SQLTest系列,革命尚未成功,同志还需努力。