本文讨论的主题是使用SSMS(SQL Server Management Studio)配合BCP命令行的方式来迁移SQL Server数据库。使用SSMS做数据库结构迁移,使用BCP命令做全量数据迁移,此方案是以本地SQL Server数据库迁移到阿里云RDS SQL Server 2012为例。
如果你觉得读取文章不够直观,请点击观看Youku视频,近25分钟的视频详细介绍来如何使用SSMS + BCP迁移SQL Server数据库上阿里云RDS SQL Server。使用SSMS+BCP迁移SQL Server数据库上阿里云RDS SQL Server
背景信息
本方法适用于SQL Server数据库结构迁移和全量数据迁移
本方法仅适用于数据全量迁移,不支持数据增量迁移
本方法适用于本地数据到本地数据库、本地数据库上云到RDS SQL Server数据库、RDS SQL Server数据库到RDS SQL Server数据库三种场景的数据库全量迁移
本文以迁移本地SQL Server 2012数据库AdventureWorks2012到阿里云RDS SQL Server 2012为例,讲述详细的迁移步骤
总体步骤
本文档详细的操作步骤和具体实施过程稍显繁琐,在详细的操作步骤之前,我们梳理下总体的思路和方法。这样可以,从大处着眼,小处着手,条理清楚,思路清晰。我们的目标是SQL Server本地数据库全量迁移或者是本地数据库上云RDS SQL Server,我们必须完成三大任务:
准备工作
对象结构迁移
数据全量迁移
准备工作
准备工作包括源端数据的准备工作和目标数据库的准备工作。
源端数据库:创建用户和断开客户端连接。
目标数据库:创建数据库、确保排序规则一致和创建用户。
对象结构迁移
微软SQL Server Management Studio(简称:SSMS)工具提供了数据库对象结构创建脚本的生成功能。所以,我们直接使用这个功能来生成源端数据库对象结构的创建脚本,然后在目标数据库中去执行。为了不遗漏任何的数据库对象,我们需要对比源端数据库和目标数据库的对象信息,确保一致。具体的步骤可以分解为以下几个小的步骤:
源端数据库获取对象创建脚本
目标数据库执行对象创建脚本
源端数据库和目标数据库获取对象信息
对象信息对比
注意:
这里需要特别提醒,为了避免数据全量迁移过程报错和提高数据导入效率,我们需要在“目标数据库”中先禁用外键、索引和触发器,数据导入完毕后,再启用这三类对象。
数据全量迁移
我们使用BCP命令行来做数据库数据的导出导入功能。为了确保数据全量迁移成功,我们需要对比源端数据库和目标数据库中表记录数是一致的。具体的操作步骤分解为:
BCP从源端数据库导出数据
BCP导入数据到目标数据库
表记录数对比
目标数据库启用外键约束、索引和触发器
准备工作
源端数据库
源端数据库的准备工作包括用户创建和断开客户端连接。
用户创建
在源端数据库创建用户登录,如果已经存在用户,并具备读写该数据库权限,请跳过该步骤。创建用户代码如下:
USE MASTER
GO
CREATE LOGIN testdbo
WITH PASSWORD = N'XXXXXXXX',CHECK_POLICY = OFF
GO
USE AdventureWorks2012
GO
CREATE USER testdbo FOR LOGIN testdbo;
EXEC sys.sp_addrolemember 'db_owner','testdbo'
GO
断开客户端连接
由于本文讨论的方法仅支持全量迁移,为了确保源端数据库迁移前后的数据是完全一致的,所以在开始迁移之前一定要确保源端数据库数据没有任数据变更操作。我们可以采用断开源端数据库所有的客户端连接的方式来达到这个目的:
停止相关的所有应用程序
停止源端数据库SQL Agent服务
停掉Service Broker端口(如果部署有Service Broker)
当然,你也可以采用其他方法来确保源端数据库没有数据变更操作。
目标数据库
目标数据库的准备工作包括:检查存储空间、创建数据库、确保排序规则一致和创建用户。
检查存储空间
目标数据库主机需要有充足的存储空间来存放导入的数据和因此而带来的日志文件增长,两者加起来的空间增长大概是源端数据库大小的2-3倍(如果是数据库是Full模式)。如果目标数据库是在本地自建环境,请确保宿主机有足够的存储空间,如果是阿里云RDS SQL Server,请确保已经购买了充足的存储空间。
创建数据库
创建数据库的步骤很简单,如果是本地数据库或者阿里云RDS SQL Server 2012,请参见CREATE DATABASE语句。如果是阿里云RDS SQL Server 2008R2,可以使用用户控制台创建新的数据库。这里需要确保新建数据库排序规则与源端数据库保持一致。
确保排序规则和源端数据库一致
我们需要确保目标数据库排序规则和源端数据库排序规则一致,以免数据导入失败。修改排序规则的方法如下:
-- Check Collation name
SELECT name,collation_name
FROM sys.databases
WHERE name = 'adventureworks2012'
-- change the collate if need.
USE master;
GO
ALTER DATABASE adventureworks2012
COLLATE SQL_Latin1_General_CP1_CI_AS;
GO
用户创建
如果是本地环境数据库或者RDS SQL Server 2012,请参考“源端数据库中的用户创建”部分来创建用户;如果是RDS SQL Server 2008R2,请使用用户控制台来创建具有读写权限的用户。
操作步骤
以下是SQL Server数据库结构信息和全量数据迁移的详细实现步骤。
源端数据库获取对象创建脚本
这一步是生成源端数据库对象信息创建脚本,我们使用SSMS自带的脚本生成工具。方法是
展开Databases => 右键点击相应数据库 => 选择Tasks => Generate Scripts。如下图所示: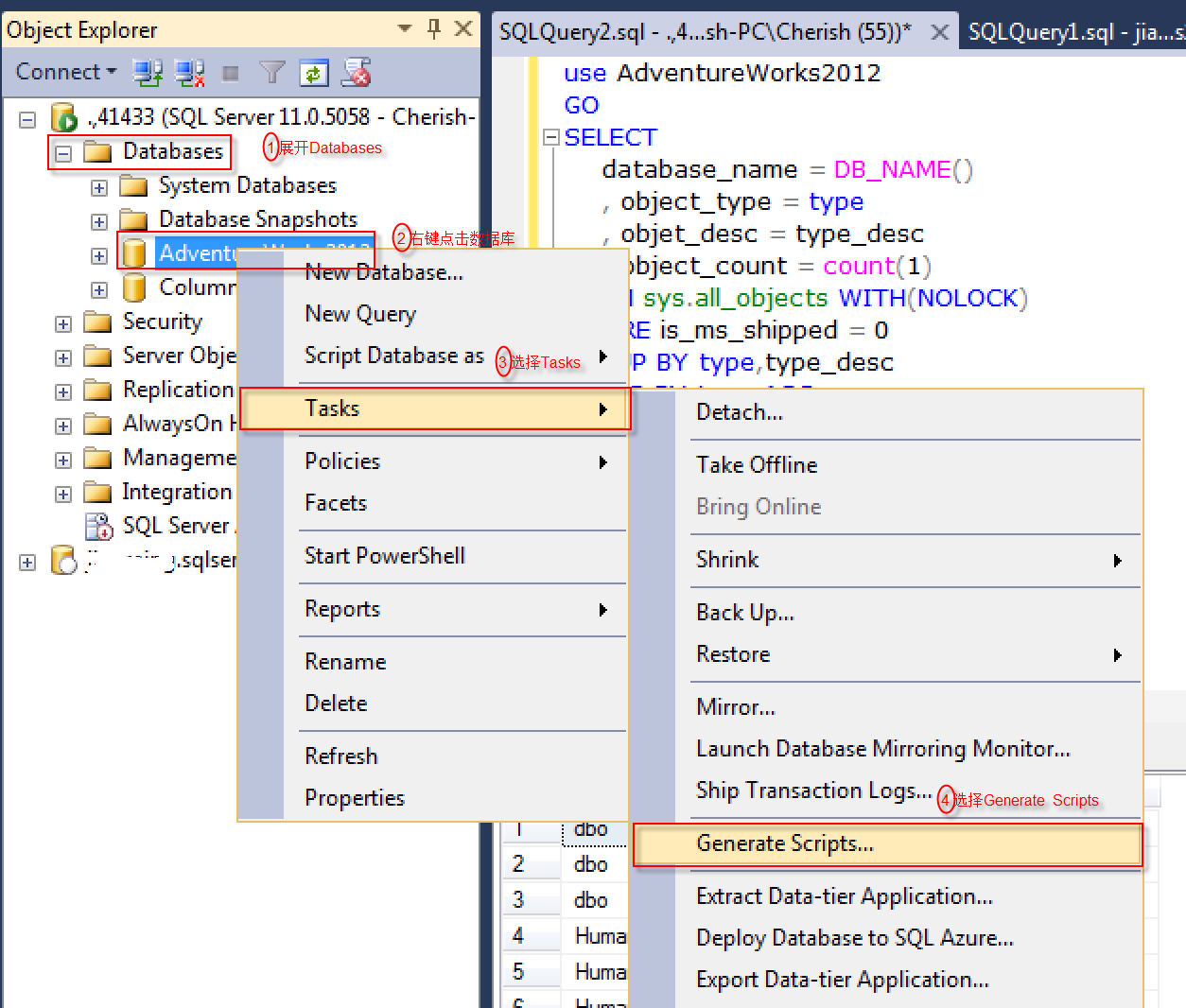
一般性介绍页面
选择要导出脚本的对象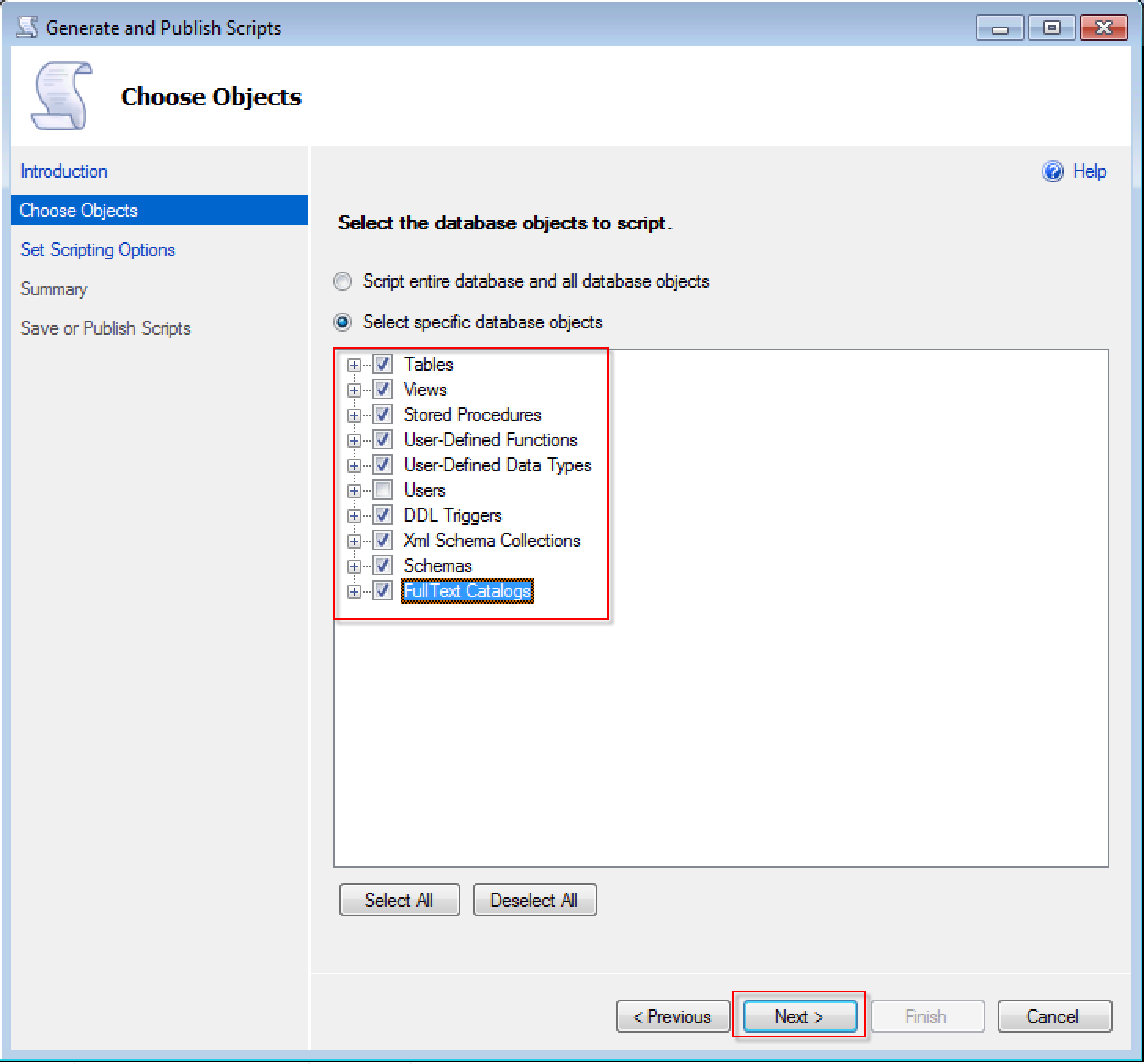
生成脚本选项设置,这一步是最关键的地方,比如:
Script for Server Version:可以选择生成脚本适用的SQL Server版本(目标数据库版本),这个选项使得不同版本间数据迁移成为可能;
Types of data to script:这里请选择Schema only,否则会生成INSERT插入数据的语句;
Table/View Options:建议全部选择True。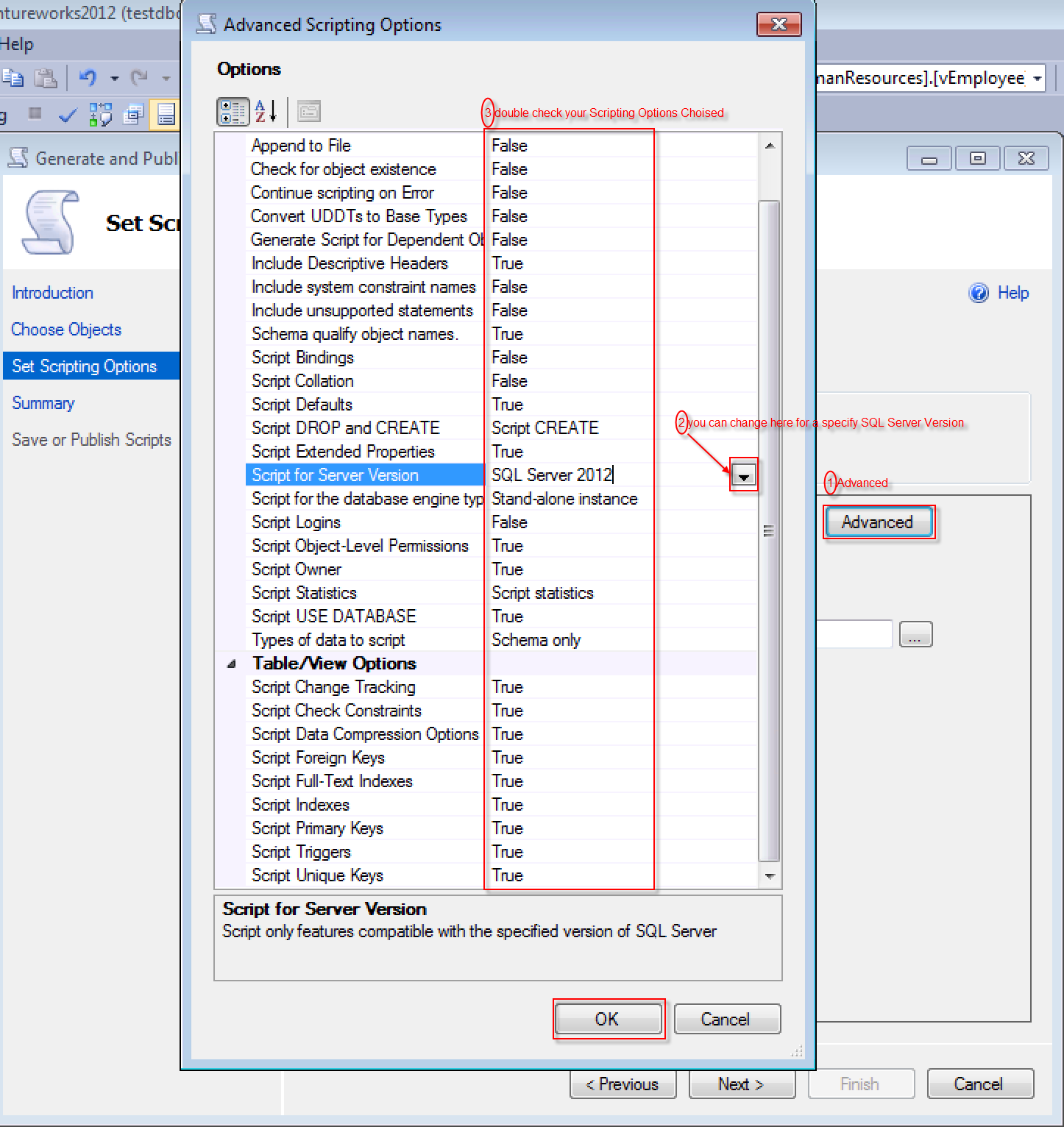
汇总信息,这里关注下生成的脚本文件目录。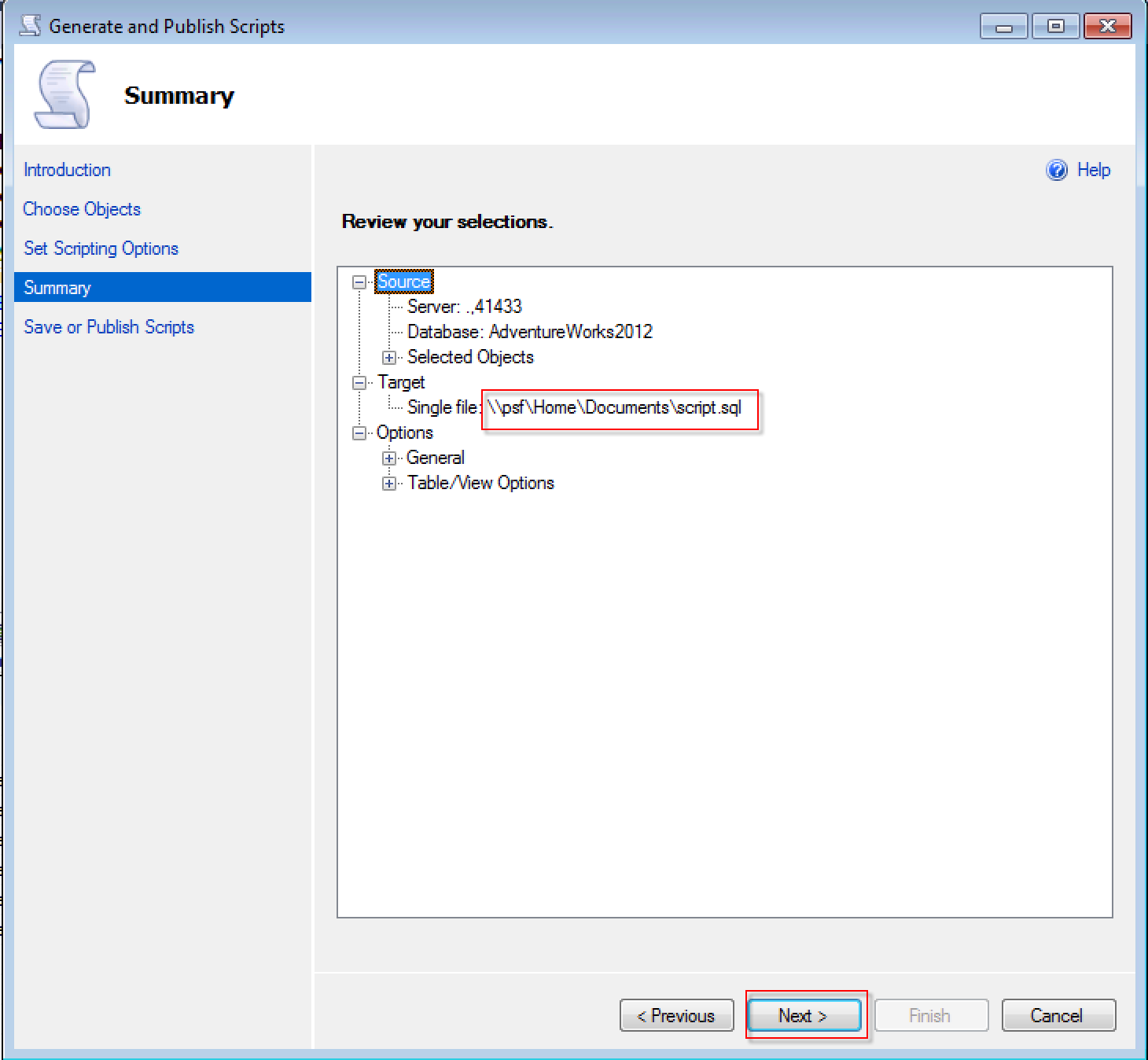
最后完成脚本生成工作。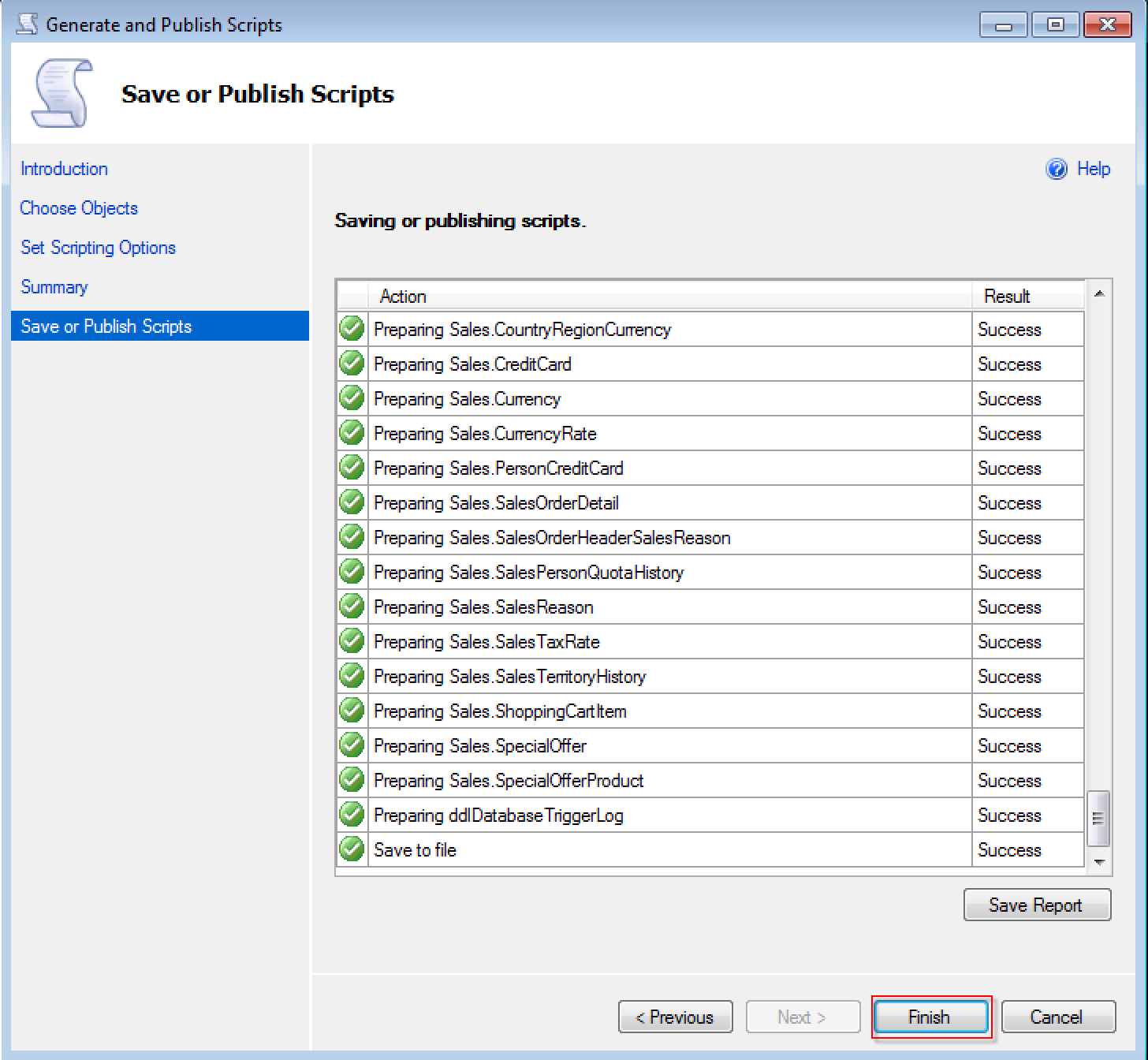
目标数据库创建对象并禁用外键、索引和触发器
在上一步,我们已经将源端数据库所有对象生成了创建的脚本文件,接下来,需要在目标数据库中执行该脚本文件来创建这些对象到目标数据库中。使用SSMS连接目标数据库实例,然后打开我们之前生成的脚本文件,并执行。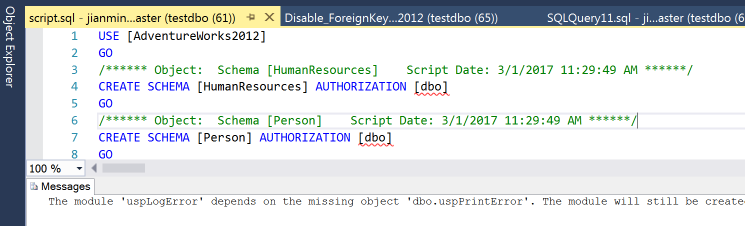
目标数据库完成对象创建以后,一个非常重要的步骤是需要禁用表外键约束、索引和触发器。因为,表外键约束的存在会导致数据导入失败,而表索引和触发器的存在会导致数据导入效率降低。为了达到这个目的,请在目标数据库中执行以下脚本。注意输入参数@is_disable = 1表示禁用外键约束、索引和触发器;@is_disable = 0表示启用外键约束、索引和触发器。
USE [adventureworks2012]
GO
--public variables: need init by users.
DECLARE
@is_disable BIT = 1 -- 1: disalbe indexes, foreign keys and triggers;
-- 0: enable indexes, foreign keys and triggers;
;
--================ Private variables
DECLARE
@sql NVARCHAR(MAX)
, @sql_index NVARCHAR(MAX)
, @tb_schema SYSNAME
, @tb_object_name SYSNAME
, @tr_schema SYSNAME
, @tr_object_name SYSNAME
, @ix_name SYSNAME
;
--================= Disable/Enable indexes on all tables
DECLARE
cur_indexes CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY
FOR
SELECT
ix_name = ix.name
, tb_schema = SCHEMA_NAME(obj.schema_id)
, tb_object_name = obj.name
FROM sys.indexes as ix
INNER JOIN sys.objects as obj
ON ix.object_id = obj.object_id
WHERE ix.type >= 2
AND obj.is_ms_shipped = 0
AND ix.is_disabled = (1 - @is_disable)
OPEN cur_indexes;
FETCH NEXT FROM cur_indexes INTO @ix_name, @tb_schema, @tb_object_name;
WHILE @@FETCH_STATUS = 0
BEGIN
SET
@sql_index = N'ALTER INDEX ' + QUOTENAME(@ix_name)
+ N' ON ' + QUOTENAME(@tb_schema) + N'.' + QUOTENAME(@tb_object_name)
+ CASE @is_disable
WHEN 1 THEN N' DISABLE;'
WHEN 0 THEN N' REBUILD; '
ELSE N''
END;
RAISERROR(N'%s', 10, 1, @sql_index) WITH NOWAIT;
EXEC sys.sp_executesql @sql_index
FETCH NEXT FROM cur_indexes INTO @ix_name, @tb_schema, @tb_object_name;
END
CLOSE cur_indexes;
DEALLOCATE cur_indexes;
--================= Disable/Enable foreign keys on all tables
--disable
IF @is_disable = 1
BEGIN
SELECT
@sql = N'
RAISERROR(N''ALTER TABLE ? NOCHECK CONSTRAINT ALL;'', 10, 1) WITH NOWAIT
ALTER TABLE ? NOCHECK CONSTRAINT ALL;'
;
END
ELSE --enable
BEGIN
SELECT
@sql = N'
RAISERROR(N''ALTER TABLE ? WITH CHECK CHECK CONSTRAINT ALL;'', 10, 1) WITH NOWAIT
ALTER TABLE ? WITH CHECK CHECK CONSTRAINT ALL;'
;
END
EXEC sys.sp_MSforeachtable @sql
--================= Disable/Enable triggers on all tables
DECLARE
cur_triggers CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY
FOR
SELECT
tb_schema = SCHEMA_NAME(tb.schema_id)
,tb_object_name = tb.name
,tr_schema = SCHEMA_NAME(obj.schema_id)
,tr_object_name = obj.name
FROM sys.objects as obj
INNER JOIN sys.tables as tb
ON obj.parent_object_id = tb.object_id
INNER JOIN sys.triggers as tr
ON obj.object_id = tr.object_id
WHERE obj.type = 'TR'
AND obj.is_ms_shipped = 0
AND tr.is_disabled = (1 - @is_disable)
ORDER BY tb_schema, tb_object_name
OPEN cur_triggers;
FETCH NEXT FROM cur_triggers INTO @tb_schema, @tb_object_name, @tr_schema, @tr_object_name;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @sql = CASE @is_disable
WHEN 1 THEN N'DISABLE TRIGGER '
WHEN 0 THEN N'ENABLE TRIGGER '
ELSE N''
END
+ QUOTENAME(@tr_schema) + N'.' + QUOTENAME(@tr_object_name)
+ N' ON '
+ QUOTENAME(@tb_schema) + N'.' + QUOTENAME(@tb_object_name)
;
RAISERROR(N'%s', 10, 1, @sql) WITH NOWAIT;
EXEC sys.sp_executesql @sql;
FETCH NEXT FROM cur_triggers INTO @tb_schema, @tb_object_name, @tr_schema, @tr_object_name;
END
CLOSE cur_triggers;
DEALLOCATE cur_triggers;
GO
源端和目标数据库获取对象信息并比较
对象信息是指数据库下存在的各种对象信息,包含但不仅限于表、视图、函数、触发器、约束和索引等。请在源端和目标数据库中分别执行以下代码,获取数据库的对象汇总信息。
USE AdventureWorks2012
GO
;WITH objs
AS(
-- check objects
SELECT
database_name = LOWER(DB_NAME())
, object_type = type
, objet_desc = type_desc
, object_count = COUNT(1)
FROM sys.all_objects WITH(NOLOCK)
WHERE is_ms_shipped = 0
GROUP BY type,type_desc
UNION ALL
--check indexes
SELECT
database_name = LOWER(DB_NAME())
, object_type = CAST(ix.type AS VARCHAR)
, objet_desc = ix.type_desc
, object_count = COUNT(1)
FROM sys.indexes as ix
INNER JOIN sys.objects as obj
ON ix.object_id = obj.object_id
WHERE obj.is_ms_shipped = 0
GROUP BY ix.type,ix.type_desc
)
SELECT * FROM objs
ORDER BY object_type
源端和目标数据库对象信息获取完毕后,接下来是比较汇总信息。为了方便对比和避免人眼观察带来的人为错误,我们建议使用对比工具来对比对象汇总信息,推荐使用的是:Araxis Merge 2001 v6.0 Professional这款对比工具。
首先,我们将源端数据库获取到的对象汇总信息复制到对比工具左侧窗口中,复制方法如下图所示: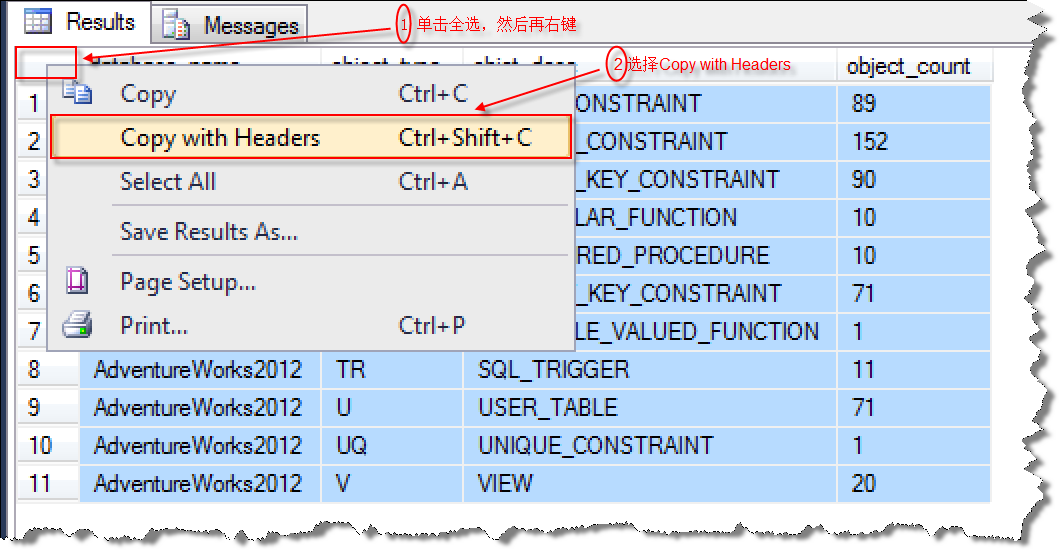
然后,将目标数据库对象汇总信息复制到对比工具右侧窗口中。
接下来,由于阿里云RDS SQL Server目标数据库名称仅支持小写字母,而源数据库名可能含有大写字母,所以我们需要修改对比工具的设置,忽略字母大小写。方法如下:
View => Options => 选中”Ignore differences in character case”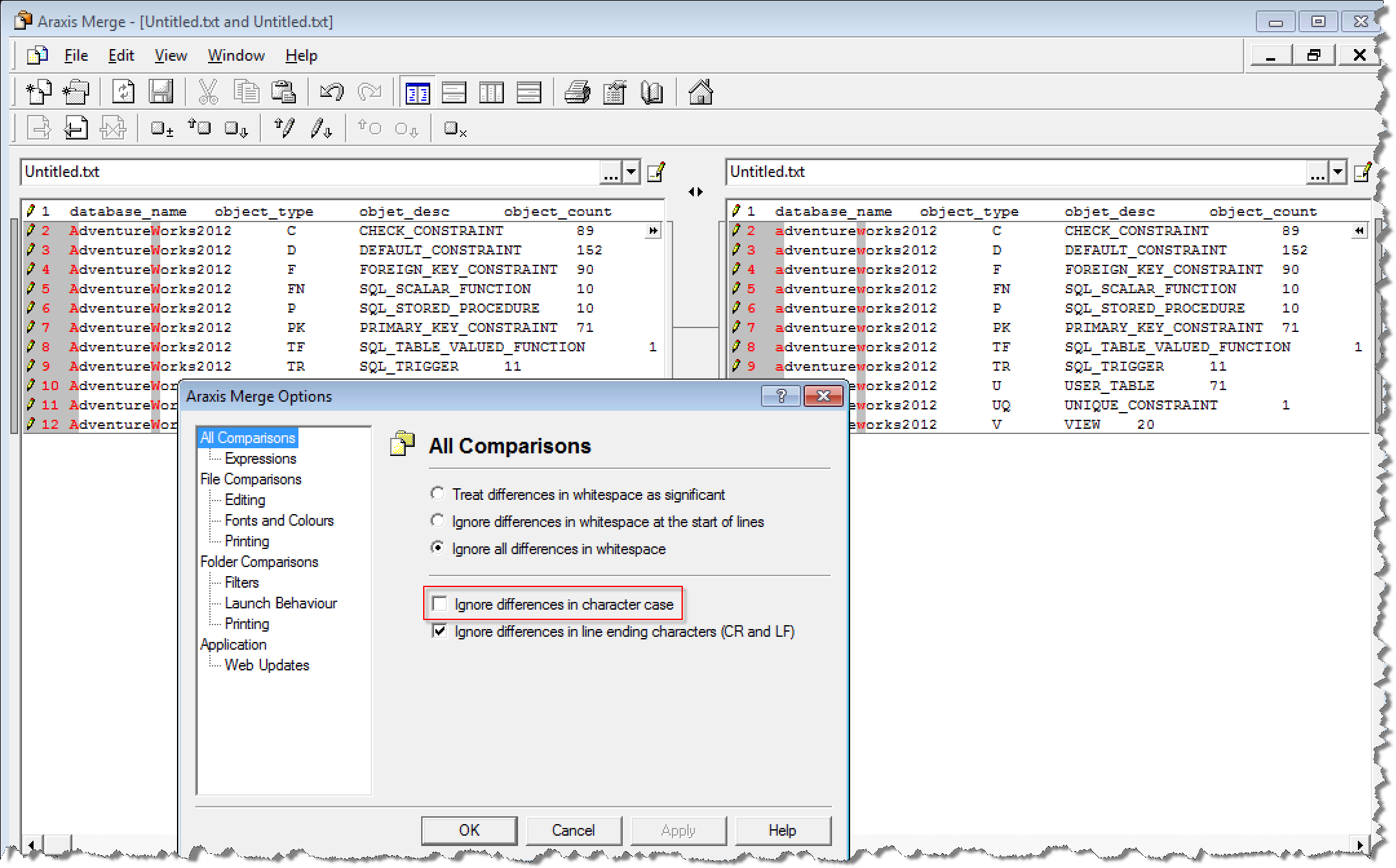
修改设置之前,对比工具认为左右两边窗口的信息是不一样的,对比工具已经高亮显示了不同的地方;修改设置忽略大小写之后,对比工具显示左右窗口中的信息已经完全一样了。因此,我们可以认为所有的对象信息已经从源数据库迁移到了目标数据库。这是我们在下一步导入数据到目标数据库开始之前一定要确保成功的。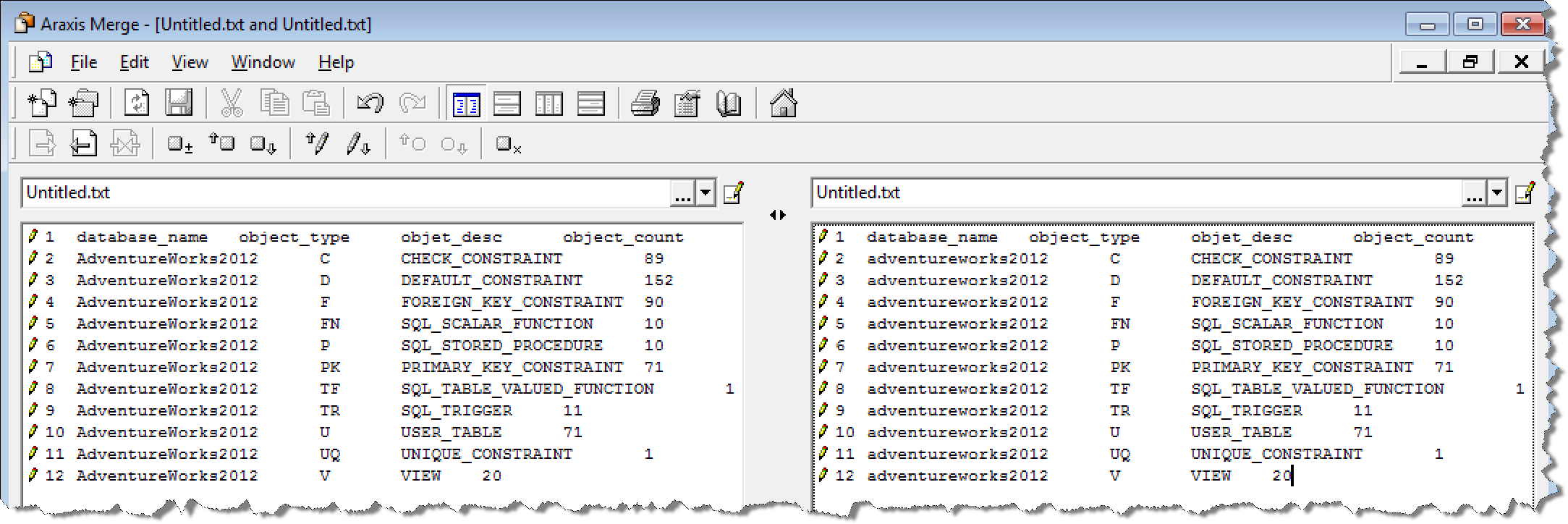
使用BCP做数据全量迁移
上一个步骤,我们已经确保了源端数据库和目标数据库对象信息已经保持一致了。接下来需要将源端数据库中所有表的所有数据导入到目标数据库对应的表中。这个动作我们使用SQL Server自带的BCP命令行工具,方法如下:
SQL 脚本生成BCP OUT和BCP IN
USE AdventureWorks2012
GO
-- declare public variables, need to init by user
DECLARE
@source_Instance sysname
, @source_Database sysname
, @source_User sysname
, @source_Passwd sysname
, @destination_Instance sysname
, @destination_Database sysname
, @destination_User sysname
, @destination_Passwd sysname
, @batch_Size int
, @transfer_table_list nvarchar(max)
;
-- Public variables init.
SELECT
@source_Instance = @@SERVERNAME -- Source Instance Name
, @source_Database = DB_NAME() -- Source Database is current database.
, @source_User = 'XXX' -- Source Instance Connect User Name
, @source_Passwd = N'XXX' -- Source Instance User Password
, @destination_Instance = N'XXXX.sqlserver.rds.aliyuncs.com,3433' -- Destination Instance Name
, @destination_Database = N'' -- Destination Database name: NULL/empty: Keep the same as source db
, @destination_User = 'XXX' -- Destination Instance User Name
, @destination_Passwd = N'XXX' -- Destination Instance User Password
, @transfer_table_list = N'' --NULL/empty: ALL Tables are needed to be transfered.
, @batch_Size = 50000 -- BCP IN Batch Size, by default, it is 50000. Must between 1 and 50000.
;
-- Private variables, there is no need to init.
DECLARE
@transfer_table_list_xml xml
, @timestamp char(14)
;
-- correct the variables init by user.
SELECT
@source_Instance = RTRIM( LTRIM(@source_Instance) )
, @source_User = RTRIM( LTRIM( @source_User ) )
, @source_Passwd = RTRIM( LTRIM( @source_Passwd ) )
, @destination_Instance = RTRIM( LTRIM( @destination_Instance ) )
, @destination_Database = CASE
WHEN ISNULL(@destination_Database, N'') = N'' THEN @source_Database
ELSE @destination_Database
END
, @destination_User = RTRIM( LTRIM( @destination_User ) )
, @destination_Passwd = RTRIM( LTRIM( @destination_Passwd ) )
, @batch_Size = CASE
WHEN (@batch_Size>0 AND @batch_Size<=50000) THEN @batch_Size
ELSE 50000
END
, @transfer_table_list_xml = '<V><![CDATA[' + REPLACE(
REPLACE(
REPLACE(
@transfer_table_list,CHAR(10),']]></V><V><![CDATA['
),',',']]></V><V><![CDATA['
),CHAR(13),']]></V><V><![CDATA['
) + ']]></V>'
, @timestamp =
REPLACE(
REPLACE(
REPLACE(
CONVERT(CHAR(19), GETDATE(), 120), N'-', '')
, N':', N'')
, CHAR(32), N'')
;
IF OBJECT_ID('tempdb..#tb_list', 'U') IS NOT NULL
DROP TABLE #tb_list
CREATE TABLE #tb_list(
RowID INT IDENTITY(1, 1) NOT NULL PRIMARY KEY
,Table_name SYSNAME NOT NULL
)
IF ISNULL(@transfer_table_list, '') = ''
BEGIN
INSERT INTO #tb_list
SELECT name
FROM sys.tables AS tb
WHERE tb.is_ms_shipped = 0
END
ELSE
BEGIN
INSERT INTO #tb_list
SELECT table_name = T.C.value('(./text())[1]','sysname')
FROM @transfer_table_list_xml.nodes('./V') AS T(C)
WHERE T.C.value('(./text())[1]','sysname') IS NOT NULL
END
;
SELECT
BCP_OUT = N'BCP ' + @source_Database + '.' + sch.name + '.' + tb.name
+ N' Out '
+ QUOTENAME( REPLACE(@source_Instance, N'\', N'_')+ '.' + @source_Database + '.' + sch.name + '.' + tb.name, '"')
+ N' /N /U ' + @source_User +N' /P ' + @source_Passwd +N' /S ' + @source_Instance
+ N' >> BCPOUT_' + @timestamp +N'.txt'
,BCP_IN = N'BCP ' + @destination_Database + '.' + sch.name + '.' + tb.name
+ N' In '
+ QUOTENAME( REPLACE(@source_Instance, N'\', N'_')+ '.' + @source_Database + '.' + sch.name + '.' + tb.name, '"')
+ N' /N /E /q /k /U ' + @destination_User + N' /P ' + @destination_Passwd + N' /b '
+ CAST(@batch_Size as varchar) + N' /S ' + @destination_Instance
+ N' >> BCPIN_' + @timestamp + N'.txt'
--,*
FROM sys.tables as tb
LEFT JOIN sys.schemas as sch
ON tb.schema_id = sch.schema_id
WHERE tb.is_ms_shipped = 0
AND tb.name IN (SELECT Table_name FROM #tb_list)
在源端数据库执行上面的脚本
请参照下面截图中的说明修改两个红色框中部分。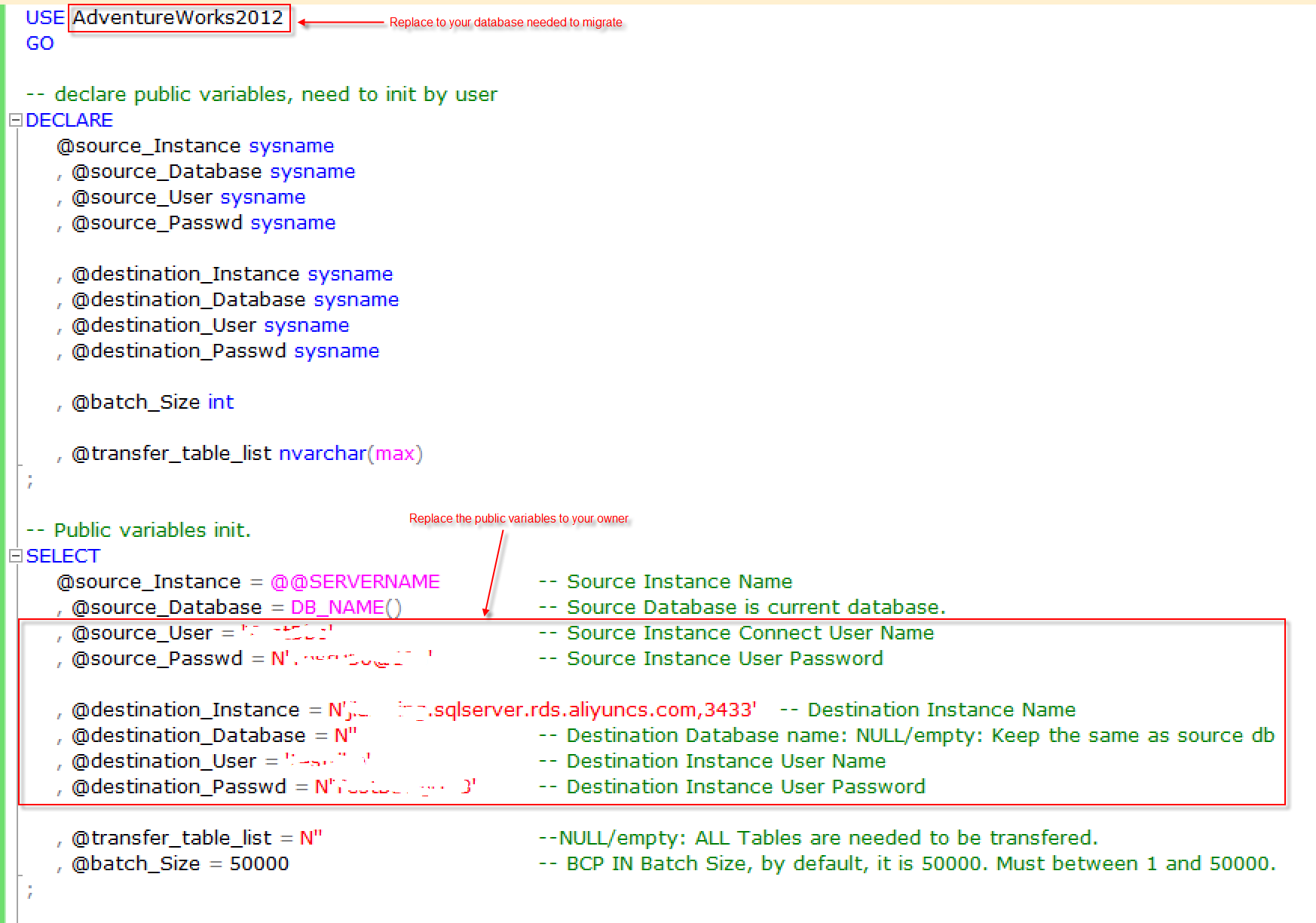
保存执行结果中BCP_OUT列所有内容到文件BCPOUT.bat
保存执行结果中BCP_IN列所有内容到文件BCPIN.bat
执行BCPOUT.bat文件
检查BCPOUT.bat执行的日志文件
BCPOUT.bat批处理文件执行后会生成一个日志文件,日志文件的命名格式是:BCPOUT_YYYYMMDDHHMMSS.txt,比如:BCPOUT_20170123113408.txt。
执行BCPIN.bat文件
检查BCPIN.bat执行的日志文件
BCPIN.bat批处理文件执行后会生成一个日志文件,日志文件的命名格式是:BCPIN_YYYYMMDDHHMMSS.txt,比如:BCPIN_20170123113408.txt。
删除BCP导出的中间临时文件
如果确保数据已经从源端数据库导入到目标数据,磁盘上的这些中间临时文件就可以删除了。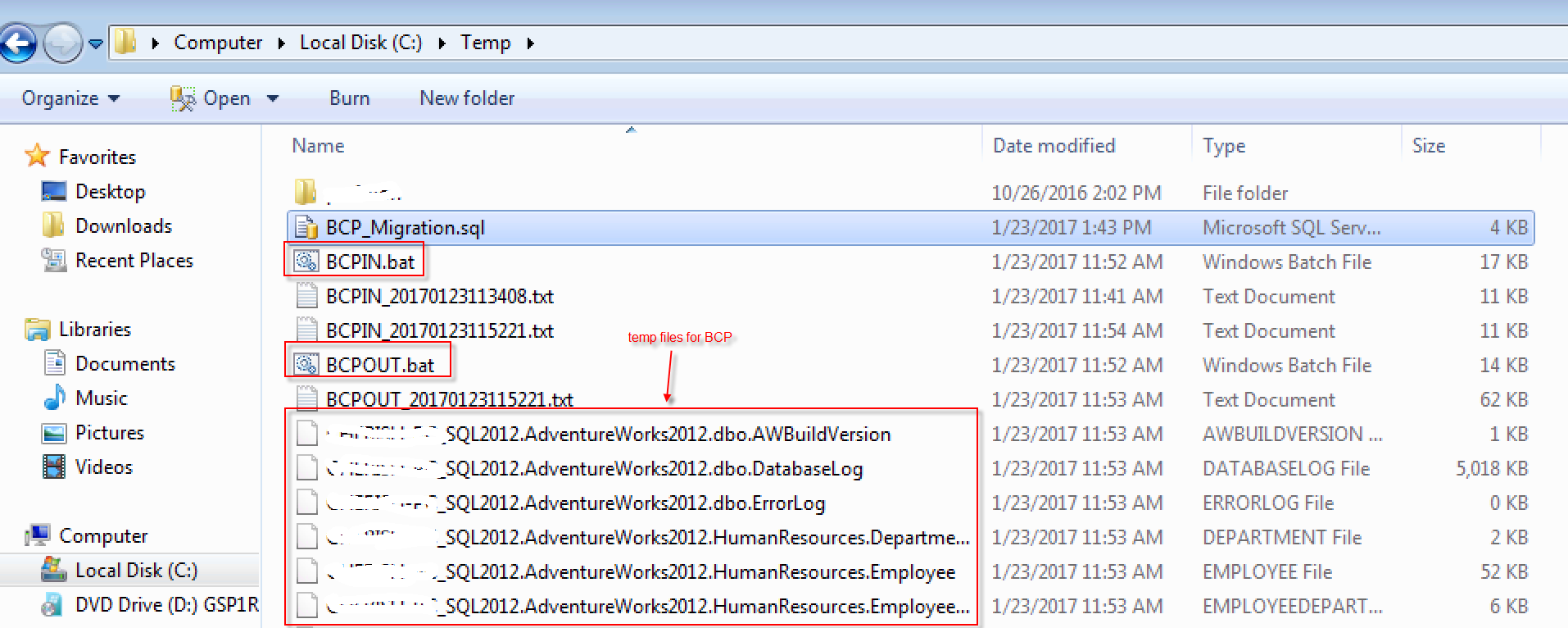
表记录数对比
在源端数据库和目的端数据库分别执行下面的语句,统计每个表总共存在的记录总数。然后参照“源端和目标数据库获取对象信息并比较”中对比工具使用方法,对比执行结果,最终来确保源端数据库和目标数据库数据保持一致。
USE AdventureWorks2012
GO
SELECT
schema_name = SCHEMA_NAME(tb.schema_id)
,table_name = OBJECT_NAME(tb.object_id)
,row_count = SUM(CASE WHEN ps.index_id < 2 THEN ps.row_count ELSE 0 END)
FROM sys.dm_db_partition_stats as ps WITH(NOLOCK)
INNER JOIN sys.tables as tb WITH(NOLOCK)
ON ps.object_id = tb.object_id
WHERE tb.is_ms_shipped = 0
GROUP BY tb.object_id,tb.schema_id
ORDER BY schema_name,table_name
源端数据库和目标数据库所有表记录总数相同,对比结果如下图所示: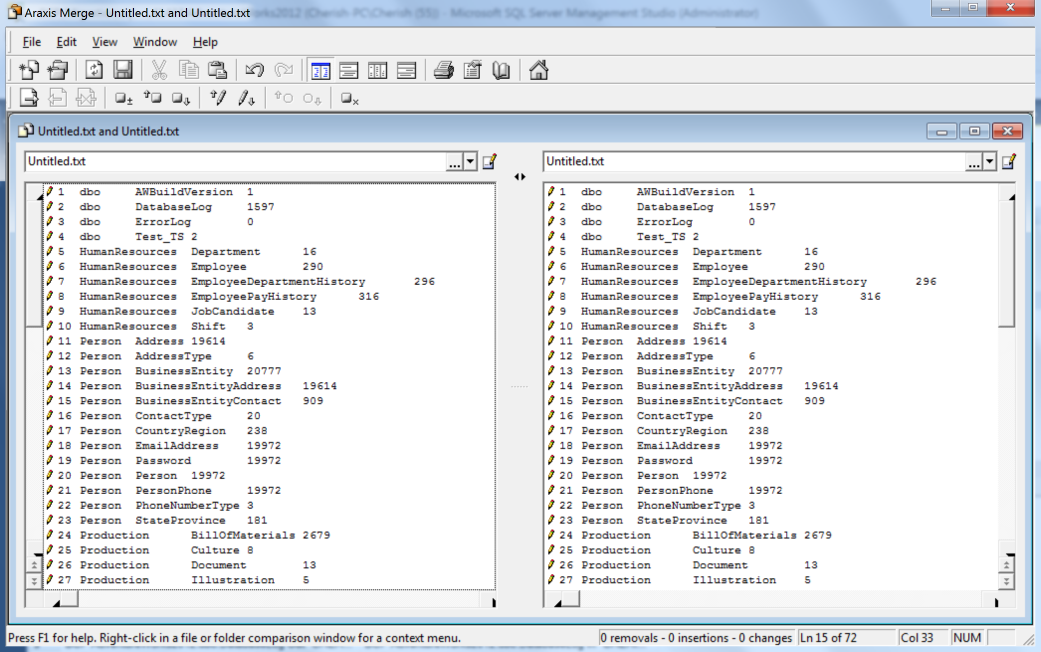
目标数据库启用表外键、索引和触发器
在确保目标数据库表的所有数据已经导入完毕以后,最后一个步骤是启动目标数据库中所有表的外键约束、索引和触发器。这个步骤操作非常简单,只需要将“目标数据库创建对象并禁用外键、索引和触发器”中的脚本输入参数设置为@is_disable = 0,执行脚本即可。这个脚本可能会运行比较长的时间,请不要惊慌或者手动终止,因为脚本会做表索引的重建工作,具体运行时间视数据量大小而定,你可以通过Messages窗口查看当前进度。
注意
排序规则的一致性
在目标数据库创建的时候,一定要确保目标数据库排序规则和源端数据库保持一致,否则很可能会导致全量数据迁移失败。
注意外键、索引和触发器
为了防止数据全量迁移过程报错,需要在“目标数据库”中禁用外键、索引和触发器,然后再启用,以此来避免错误发生和提高数据导入效率。
时间戳列和计算列
BCP导出的数据文件中针对计算列或 timestamp 列,BCP导入时这些列值将被忽略,SQL Server 将自动分配该列的值。
如果遭遇错误
因为难免考虑不周,如果您在参照这个过程遇到任何问题或者错误,请联系阿里云,以便我们及时纠正错误并竭诚为您服务。