1.5 扩展案例:考试成绩的回归分析
在接下来的案例中,我们会从头到尾进行一个简单的统计回归分析。这个例子实际上没有多少编程技术,不过它说明了如何使用前面提到的一些数据结构,包括R的S3对象。同样,它在后面的章节里也充当了编程案例的基础。
ExamsQuiz.txt文件包含了我所教班级的成绩。下面是该文件的前几行:
数字表示的是学生成绩的学分绩点。比如绩点3.3对应的就是平常所说的B+。每一行包含的是一个学生的数据,由期中考试成绩、期末考试成绩和平均小测验成绩组成。此例的兴趣点在于用期中考试成绩和平均小测验成绩来预测期末成绩。
先来读入数据文件。

这个数据文件的第一行不是记录的变量名,也就是说没有表头行,所以在函数调用中设定header=FALSE。这是前文提到过的关于默认参数的一个例子。实际上,表头参数的默认值已经是FALSE了(关于这一点,可以在R里查看函数read.table()的在线帮助),所以没必要做前面那样的设定,不过这样做会更明了。
数据现在在examsquiz中,它是数据框类的R对象。

由于缺少数据表头行,R自动把列名设置为V1、V2和V3。行号出现在每行的最左边。可能你会觉得数据文件有表头比较好,用有意义的名称(比如Exam1)来标识变量。在后面的例子中,我们通常会设定变量名。
我们来用期中考试成绩(examsquiz的第一列)预测期末考试成绩(examsquiz的第二列):
这里调用lm()函数(lm是linear model的缩写),让R拟合下面的预测方程:
期末考试成绩预测值=β0+β1×期中考试成绩
其中,β0和β1都是用本例的数据估计出来的常数。换句话说,我们用数据中的数对(期中考试成绩,期末考试成绩)拟合了一条直线。拟合过程是用经典的最小二乘法来完成的。(如果你没有相关的背景知识也不用担心。)
注意,存储在数据框第一列的期中考试成绩是用examsquiz[,1]表示,省略了第一维的下标(代表行号)表示我们引用的是数据框的一整列。期末考试也是用类似的方式引用的。这样,我们调用上面的lm()命令,利用examsquiz的第一列来预测第二列。
也可以这样写:
前面提到过,数据框是种各元素都为向量的列表。在这里,各列是列表的组件V1、V2和V3。
lm()的返回结果现在是保存于变量lma中的对象。它是lm类的一个实例。可以调用attributes()函数列出它的所有组件。
和往常一样,调用str(lma)可以得到lma的更详细说明。βi的估计值保存在lma$coefficients中。在命令提示符下键入系数的变量名就可以显示系数。
在键入组件名时也可以使用缩写形式,只要缩写后的组件名不发生混淆即可。例如,如果一个列表由组件xyz、xywa和xbcde构成,则第二个和第三个组件的名称可以分别缩写为xyw和xb。因此我们可以键入下面的命令:
因为lma$coefficients是一个向量,所以比较容易打印。但是当打印对象lma本身的时候是这样的:
为什么R只打印出这些项,而没有打印出lma的其他组件?这个问题的答案是,R在这里使用的print()函数是另一个泛型函数的例子,作为一个泛型函数,print()实际上把打印的任务交给了另一个函数——print.lm(),这个函数的功能是打印lm类的对象,即上面函数展示的内容。
可以用前面讨论过的泛型函数summary()打印输出lma的更详细的内容。它实际上在后台调用了summary.lm(),得出针对某个特定回归模型的摘要:

许多其他泛型函数都是针对这个类定义的。可以查看在线帮助来获取关于lm()的更多细节。(1.7节将讨论如何使用R的在线文档。)
要用期中考试成绩和测验成绩预测期末考试成绩,可以使用记号+。
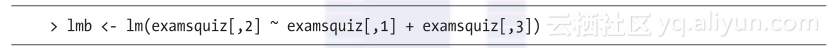
注意,+号并不表示计算两个量的和。它仅仅是预测变量(predictor variable)的分隔符。