线性回归是利用数理统计中的回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。分析按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。(这反过来又应当由多个相关的因变量预测的多元线性回归区别,[引文需要],而不是一个单一的标量变量。)
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
问题引入
假设有一个房屋销售的数据如下:
|
面积(m^2) |
销售价钱(万元) |
|
123 |
250 |
|
150 |
320 |
|
87 |
160 |
|
102 |
220 |
|
… |
… |
这个表类似于北京5环左右的房屋价钱,我们可以做出一个图,x轴是房屋的面积。y轴是房屋的售价,如下:

如果来了一个新的面积,假设在销售价钱的记录中没有的,我们怎么办呢?
我们可以用一条曲线去尽量准的拟合这些数据,然后如果有新的输入过来,我们可以在将曲线上这个点对应的值返回。如果用一条直线去拟合,可能是下面的样子:

绿色的点就是我们想要预测的点。
首先给出一些概念和常用的符号。
房屋销售记录表:训练集(training set)或者训练数据(training data), 是我们流程中的输入数据,一般称为x
房屋销售价钱:输出数据,一般称为y
拟合的函数(或者称为假设或者模型):一般写做 y = h(x)
训练数据的条目数(#training set),:一条训练数据是由一对输入数据和输出数据组成的输入数据的维度n (特征的个数,#features)
这个例子的特征是两维的,结果是一维的。然而回归方法能够解决特征多维,结果是一维多离散值或一维连续值的问题。
学习过程
下面是一个典型的机器学习的过程,首先给出一个输入数据,我们的算法会通过一系列的过程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计,也被称为构建一个模型。就如同上面的线性回归函数。
![]()
线性回归
线性回归假设特征和结果满足线性关系。其实线性关系的表达能力非常强大,每个特征对结果的影响强弱可以由前面的参数体现,而且每个特征变量可以首先映射到一个函数,然后再参与线性计算。这样就可以表达特征与结果之间的非线性关系。
我们用X1,X2..Xn 去描述feature里面的分量,比如x1=房间的面积,x2=房间的朝向,等等,我们可以做出一个估计函数:
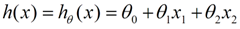
θ在这儿称为参数,在这的意思是调整feature中每个分量的影响力,就是到底是房屋的面积更重要还是房屋的地段更重要。为了如果我们令X0 = 1,就可以用向量的方式来表示了:
![]()
我们程序也需要一个机制去评估我们θ是否比较好,所以说需要对我们做出的h函数进行评估,一般这个函数称为损失函数(loss function)或者错误函数(error function),描述h函数不好的程度,在下面,我们称这个函数为J函数
在这儿我们可以认为错误函数如下:
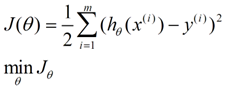
这个错误估计函数是去对x(i)的估计值与真实值y(i)差的平方和作为错误估计函数,前面乘上的1/2是为了在求导的时候,这个系数就不见了。
至于为何选择平方和作为错误估计函数,讲义后面从概率分布的角度讲解了该公式的来源。
如何调整θ以使得J(θ)取得最小值有很多方法,其中有最小二乘法(min square),是一种完全是数学描述的方法,和梯度下降法。
在这里需要理解的一个概念是斜率和截率。
斜率,亦称“角系数”,表示一条直线相对于横轴的倾斜程度。一条直线与某平面直角坐标系横轴正半轴方向的夹角的正切值即该直线相对于该坐标系的斜率。 如果直线与x轴垂直,直角的正切值无穷大,故此直线不存在斜率。 当直线L的斜率存在时,对于一次函数y=kx+b(斜截式),k即该函数图像(直线)的斜率。
斜率的计算公式为:
当直线L的斜率存在时,点斜式y2—y1=K(X2—X1),当直线L在两坐标轴上存在非零截距时,有截距式X/a+y/b=1对于任意函数上任意一点,其斜率等于其切线与x轴正方向的夹角,即tanα 斜率计算:ax+by+c=0中,k=-a/b。
2,计算过程如下: 斜率=k=(y1-y20/(x1-x2) =(-3-4)/(2-(-5)) =-1。 直线斜率公式:k=(y2-y1)/(x2-x1)
下面再具体说一下梯度下降和最小二乘法:
梯度下降法
在选定线性回归模型后,只需要确定参数θ,就可以将模型用来预测。然而θ需要在J(θ)最小的情况下才能确定。因此问题归结为求极小值问题,使用梯度下降法。梯度下降法最大的问题是求得有可能是全局极小值,这与初始点的选取有关。
梯度下降法是按下面的流程进行的:
1)首先对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量。
2)改变θ的值,使得J(θ)按梯度下降的方向进行减少。
梯度方向由J(θ)对θ的偏导数确定,由于求的是极小值,因此梯度方向是偏导数的反方向。结果为
![]()
迭代更新的方式有两种,一种是批梯度下降,也就是对全部的训练数据求得误差后再对θ进行更新,另外一种是增量梯度下降,每扫描一步都要对θ进行更新。前一种方法能够不断收敛,后一种方法结果可能不断在收敛处徘徊。
一般来说,梯度下降法收敛速度还是比较慢的。
另一种直接计算结果的方法是最小二乘法。
最小二乘法
将训练特征表示为X矩阵,结果表示成y向量,仍然是线性回归模型,误差函数不变。那么θ可以直接由下面公式得出
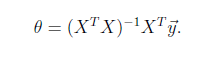
但此方法要求X是列满秩的,而且求矩阵的逆比较慢。