2.2.3 集群启动关闭与监控
启动集群,只需要在master节点(NameNode服务所在节点)直接进入Hadoop安装目录,分别执行如代码清单2-16所示的命令即可。
代码清单2-16 启动Hadoop集群
cd $HADOOP_HOME // 进入Hadoop安装目录
bin/start-dfs.sh // 启动HDFS相关服务
bin/start-yarn.sh // 启动YARN相关服务
bin/mr-jobhistory-daemon.sh start historyserver // 启动日志相关服务
关闭集群,同样只需要在master节点(NameNode服务所在节点)直接进入Hadoop安装目录,分别执行如代码清单2-17所示的命令即可(注意关闭顺序)。
代码清单2-17 关闭Hadoop集群
cd $HADOOP_HOME // 进入Hadoop安装目录
bin/stop-yarn.sh // 关闭YARN相关服务
bin/stop-dfs.sh // 关闭HDFS相关服务
bin/mr-jobhistory-daemon.sh stop historyserver // 关闭日志相关服务
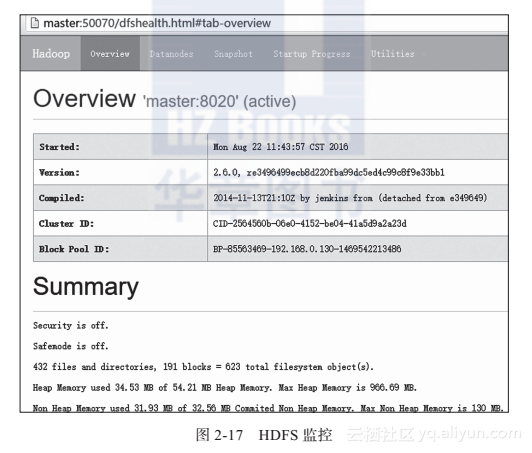
Hadoop集群相关服务监控如表2-2所示,其监控示意分别如图2-17、图2-18、图2-19所示。
表2-2 Hadoop集群监控相关端口
服 务 Web接口 默 认 端 口
NameNode http://namenode_host:port/ 50070
ResourceManager http://resourcemanager_host:port/ 8088
MapReduce JobHistory Server http://jobhistoryserver_host:port/ 19888
时间: 2024-08-29 10:57:19