1.3 非参数检验
1.3.1 二项分布的检验
对于单个总体,如果作n次试验,且成功的概率为p,则试验成功的次数X服从二项分布,即X~B(n,p).如果n次试验中有x次成功了,可用p=xn作为p的估计.
1.二项分布的近似检验
当np≥5且nq≥5(q=1-p)时,可用正态分布近似二项分布,即p~N(p,p q/n)(1.44)近似成立.所以p-pp q/n~N(0,1)(1.45)近似成立.因此,可以用标准正态分布作比值p的检验![]()
对于两个总体,如果试验次数分别为n1和n2,成功的次数分别为x1和x2,可用pi=xini作为pi(i=1,2)的估计.当nipi≥5且niqi≥5(qi=1-pi,i=1,2)时,可用正态分布近似二项分布,即p1~N(p1,p1q1/n1), p2~N(p2,p2q2/n2)(1.49)近似成立.所以当p1=p2=p(q=1-p)时,p1-p2pq1n1+1n2~N(0,1)(1.50)近似成立.因此,也可以用标准正态分布作比值差p1-p2的检验![]()
在R中,用prop.test()函数来完成二项分布的近似检验,其使用格式为 prop.test(x, n, p = NULL,
alternative = c("two.sided", "less", "greater"),
conf.level = 0.95, correct = TRUE)参数x为整数向量,表示试验成功的次数,或者为一个2列的矩阵,第1列表示成功的次数,第2列表示失败的次数.
n为整数向量,表示试验的次数,当x为矩阵时,该值无效.
p为向量,表示试验成功的概率,必须与x有相同的维数,且值在0至1之间,默认值为NULL.
alternative为备择假设选项,取"two.sided"(默认值)表示双侧检验;取"less"表示备择假设为“<”的单侧检验,取"greater"表示备择假设为“>”的单侧检验.
conf.level为0~1之间的数值(默认值为0.95),表示置信水平,它将用于计算比率p或比率差p1-p2的置信区间.
correct为逻辑变量,表示是否对统计量作连续修正,默认值为TRUE.
当Z~N(0,1)时,有Z2~χ2(1).所以,prop.test()函数没有使用正态分布作检验,而是采用χ2分布作检验,这样做的优点是,很容易将两个总体的假设检验方法推广到m(≥3)个总体的检验中.
例1.12 某医院研究乳腺癌家族史对于乳腺癌发病率的影响.假设调查了10000名50~54岁的妇女,她们的母亲曾患有乳腺癌.发现她们在某个生存期的某个时刻有400例乳腺癌,而全国在该年龄段的妇女乳腺癌的患病率为2%,这组数据能否说明乳腺癌的患病率与家族遗传有关?
解 p0=0.02,即检验H0:p=0.02, H1:p≠0.02由于是大样本,所以可以用近似检验,即可以用prop.test()函数.> prop.test(400, 10000, p = 0.02)
1-sample proportions test with continuity correction
data: 400 out of 10000, null probability 0.02
X-squared = 203.0625, df = 1, p-value < 2.2e-16
alternative hypothesis: true p is not equal to 0.02
95 percent confidence interval:
0.03628490 0.04407297
sample estimates:
p
0.04在输出中,有χ2统计量(X-squared)、自由度(df)、P值(p-value)和比率p的置信区间,以及比率p的估计值.
由于P值(=2.2×10-16)0.05,拒绝原假设,即乳腺癌的患病率不等于2%.置信区间[0.0363,0.0441]>0.02,说明p>0.02,即乳腺癌的患病率与家族遗传有关,而且是正相关的.
也可以作单侧检验H0:p≤0.02,H1:p>0.02,其结论是拒绝原假设(请尝试),即有乳腺癌家族史的人群会增加乳腺癌的患病率.
例1.13 为节约能源,某地区政府鼓励人们拼车出行,采取的措施是在指定的某些高速路段,载有两人以上的车辆减收道路通行费.为评价该项措施的效果,随机选取了未减收路费路段的车辆2000辆和减收路费路段的车辆1500辆,发现分别有652辆和576辆是两人以上的.这些数据能否说明这项措施实施后会提高合乘汽车的比率?
解 检验H0:p1=p2, H1:p1≠p2仍然选用prop.test()函数.> n <- c(2000, 1500); x <- c(652, 576);
> prop.test(x, n)
2-sample test for equality of proportions with
continuity correction
data: x out of n
X-squared = 12.4068, df = 1, p-value = 0.0004278
alternative hypothesis: two.sided
95 percent confidence interval:
-0.09064286 -0.02535714
sample estimates:
prop 1 prop 2
0.326 0.384P值(=0.0004278)0.05,拒绝原假设,即这两组数据的比例不相同.置信区间[-0.0906,-0.0254]<0说明p1也可以作单侧检验H0:p1≥p2,H1:p1例1.14 视频工程师使用时间压缩技术来缩短播放广告节目所需要的时间,但对较短的广告是否有效?为回答这个问题,将200名大学生随机地分成三组:第1组(57名学生)观看一个包含30s广告的电视节目录像带;第2组(74名学生)观看同样的录像带,但是是24s时间压缩版的广告;第3组(69名学生)观看20s时间压缩版的广告.观看录像带两天之后,询问这三组学生广告中品牌的名称.表1.4给出每组学生回答情况的人数.试分析三种类型广告的播放效果是否有显著差异?![]()
解 如果三种类型的广告无显著差异,那么能回忆起品牌名称的比例应该是相同的,所以检验H0:p1=p2=p3, H1:p1,p2,p3不全相同程序(程序名:exam01`javascript
14.R)为X <- matrix(c(15, 32, 10, 42, 42, 59), nrow=2, byrow=T)
colnames(X) <- c("30s", "24s", "20s")
rownames(X) <- c("Yes", "No")
X.yes <- X["Yes", ]; X.total <- margin.table(X, 2)
prop.test(X.yes, X.total)在程序中, matrix()函数将向量转换成矩阵,得到的X就是表1.4中的数据矩阵,margin.table()函数的功能是计算表格的边缘表,也就是表1.4中的合计,这里计算的是测试者的总数.计算结果如下: 3-sample```javascript
test for equality of proportions
without continuity correction
data: X.yes out of X.total
X-squared = 14.6705, df = 2, p-value = 0.0006521
alternative hypothesis: two.sided
sample estimates:
prop 1 prop 2 prop 3
0.2631579 0.4324324 0.1449275P值(= 0.0006521)0.05,拒绝原假设,说明三种类型的广告播放效果是有差异的.但从得到的比率来看,采用压缩版本1(24s)的效果最好.
2.二项分布的精确检验
对于小样本数据不能用正态分布作近似检验,而需要直接用二项分布作精确检验.
在R中,用binom.test()函数完成二项分布的精确检验,其使用格式为binom.test(x, n, p = 0.5,
alternative = c("two.sided", "less", "greater"),
conf.level = 0.95)参数x为正整数,表示试验成功的次数,或者为二维向量,第1个分量表示成功的次数,第2个分量表示失败的次数.
n为正整数,表示试验次数,当x为向量时,该值无效.
p为假设中试验成功的概率,即p0,默认值为0.5.
alternative为备择假设选项,取"two.sided"(默认值)表示双侧检验,取"less"表示备择假设为“<”的单侧检验,取"greater"表示备择假设为“>”的单侧检验.
conf.level为0~1之间的数值(默认值为0.95),表示置信水平,它将用于计算比率p的置信区间.
例1.15 设某工厂生产的一批产品的次品率p是未知的.按规定,若p≤0.01,则这批产品为可接受的;否则为不可接受的.假定从这批数据很大的产品中随机地抽取100件样品,发现其中有3件次品,那么是否接受这批产品?
解 考虑最坏情况,p0=0.01,所以检验H0:p=0.01, H1:p≠0.01此时的数据不满足np≥5的条件,所以使用精确检验.> binom.test(3, 100, p=0.01)
Exact binomial test
data: 3 and 100
number of successes = 3, number of trials = 100, p-value = 0.07937
alternative hypothesis:true probability of success is not equal to 0.01
95 percent confidence interval:
0.006229972 0.085176053
sample estimates:
probability of success
0.03在输出中,有P值(p-value)、比率p的置信区间,以及p的估计值.
P值(=0.07937)>0.05,无法拒绝原假设,不能认为这批产品不合格.置信区间包含0.01,也说明同样的结论.
1.3.2 符号检验
所谓符号检验就是利用样本的正负号的个数来做的检验.事实上,符号检验本质上就是二项分布检验,因为样本取正或负就相当于试验成功或失败,而且成功或失败的概率为1/2.
从前面的介绍可知,大家可根据样本数目,使用正态近似计算(prop.test函数),或者使用二项分布精确计算(binom.test函数).
例1.16 某饮料店为了解顾客对饮料的爱好情况,进一步改进工作,对顾客喜欢咖啡还是喜欢奶茶,或者两者同样爱好进行了调查.该店在某日随机地抽取了13名顾客进行了调查,顾客喜欢咖啡超过奶茶用正号表示,喜欢奶茶超过咖啡用负号表示,两者同样爱好用0表示.现将调查的结果列在表1.5中.试分析顾客是喜欢咖啡还是喜欢奶茶.![]()
解 根据题意可检验如下假设:H0:顾客喜欢咖啡等于喜欢奶茶; H1:顾客喜欢咖啡超过喜欢奶茶以上资料中有1人(即6号顾客)表示对咖啡和奶茶有同样爱好,用0表示,因而在样本容量中不加计算,所以实际上n=12.由于n的值较小,所以选择精确二项分布检验,显著性水平取α=0.10.> binom.test(3, 12, al`javascript
="l", conf.level = 0.90)
Exact binomial test
data: 3 and 12
number of successes =3, number of trials =12, p-value =0.073
alternative hypothesis:true probability of success is less than 0.5
90 percent confidence interval:
0.0000000 0.4752663
sample estimates:
probability of success
0.25P值(=0.073)<0.10,且区间估计为[0,0.475],因此拒绝原假设,认为喜欢咖啡的人超过喜欢奶茶的人.
如果显著性水平定在α=0.05,则不能拒绝原假设,只能认为喜欢咖啡和奶茶的人一样多.
可以用符号检验作单个总体的中位数检验,即H0:M=M0, H1:M≠M0用样本观察值减去总体中位数M0,得出的正、负差额分别用正(+)、负(-)号加以表示.如果H0成立,那么,样本观察值在中位数上、下的数目应各占一半,即正号或负号的概率各为1/2.
例1.17 联合国人员在世界上66个大城市的生活花费指数(以纽约市1996年12月为100)按自小至大的次序排列如下(这里北京的指数为99):
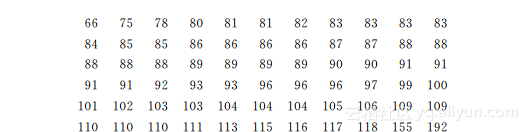
假设这个样本是从世界许多大城市中随机抽样得到的.试用符号检验分析北京的生活花费指数是在中位数之上还是在中位数之下.
解 样本的中位数(M)作为城市生活水平的中间值,因此,需要检验H0:M=99, H1:M≠99将样本值>99的个数作为成功的个数,由于总样本量为66,可以用近似检验.
将数据保存在纯文本文件exam0117.data中,使用scan()函数读取数据,调用pr```javascript
op.test()函数计算.> X <- scan("exam0117.data")
> prop.test(sum(X > 99), length(X))
1-sample proportions test with continuity correction
data: sum(X > 99) out of length(X), null probability 0.5
X-squared = 5.4697, df = 1, p-value = 0.01935
alternative hypothesis: true p is not equal to 0.5
95 percent confidence interval:
0.2381467 0.4765554
sample estimates:
p
0.3484848P值(=0.01935)<0.05,拒绝原假设.并由置信区间[0.238,0.477]<0.5,说明生活花费指数超过北京的城市数小于12,也就是说,北京是在中位数之上.
1.3.3 符号秩检验与秩和检验
由于符号检验只考虑样本的正负号,不考虑数值的大小,因此会损失一定的信息.秩检验在某种程度上可以克服符号检验的不足,所谓秩就是样本的排序.
设X1,X2,…,Xn为一组样本(不必取自同一总体),将X1,X2,…,Xn从小到大排成一列,Xi(i=1,2,…,n)在上述排列中的位置号记为Ri,称R1,R2,…,Rn为样本X1,X2,…,Xn产生的秩统计量.
1.单个总体的Wilcoxon符号秩检验
Wilcoxon符号秩检验是作单个总体X的中位数检验,即H0:M=M0, H1:M≠M0 (双侧检验)(1.54)
H0:M≥M0, H1:MH0:M≤M0, H1:M>M0 (单侧检验)(1.56)设X1,X2,…,Xn是来自总体X的样本,这里假定X的分布是连续的,且关于中位数M0是对称的.这样,将Xi-M0得到的差额按递增次序排列,并根据差额的次序给出相应的秩次Ri.定义Xi-M0>0为正秩次,Xi-M0<0为负秩次.然后按照正秩次之和进行检验,这就是秩次和检验.这种方法首先由Wilcoxon提出的,所以称为Wilcoxon符号秩检验.
如果原观察值的数目为n′,减去Xi=M0的样本后,其样本数为n.用R(+)i表示正秩次,W表示正秩次的和,则Wilcoxon统计量为W=∑ni=1R(+)i(1.57)因为n个整数1,2,…,n的总和用n(n+1)/2计算,而正秩次总和可以在区间(0,n(n+1)/2)内变动,如果观察值来自中位数为M0的某个总体的假设为真,那么Wilcoxon检验统计量的取值将是秩次和的平均数,即μW=n(n+1)/4的左右变动.如果该假设不成立,则W的取值将向秩次和的两头数值靠近.这样,在一定的显著性水平下,便可进行秩次和检验.
2.两个总体的Wilcoxon秩和检验
Wilcoxon秩和检验是作两个总体X和Y中位数差的检验H0:M1-M2=0, H1:M1-M2≠0 (双侧检验)(1.58)
H0:M1-M2≥0, H1:M1-M2<0 (单侧检验)(1.59)
H0:M1-M2≤0, H1:M1-M2>0 (单侧检验)(1.60)假定X1,X2,…,Xn1是来自总体X的样本,Y1,Y2,…,Yn2是来自总体Y的样本.将样本的观察值排在一起,X1,X2,…,Xn1,Y1,Y2,…,Yn2,仍设r1,r2,…,rn1为由X1,X2,…,Xn1产生的秩统计量,R1,R2,…,Rn2为由Y1,Y2,…,Yn2产生的秩统计量,则Wilcoxon-Mann-Whitney统计量定义为U=n1n2+n2(n2+1)2-∑n2i=1Ri(1.61)与单一总体的Wilcoxon符号检验一样,可以通过统计量U进行检验,该检验称为Wilcoxon秩和检验.
- wilcox.test函数
在R中,wilcox.test()函数完成Wilcoxon符号秩检验与秩和检验,其使用格式为`javascript
wilcox.test(x, y = NULL,
alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, exact = NULL, correct = TRUE,
conf.int = FALSE, conf.level = 0.95, ...)参数x和y分别为样本构成的数值向量.如果只有x,则完成单个总体样本的Wilcoxon符号秩检验;否则, 完成两个总体样本的Wilcoxon秩和检验.
alternative为备择假设选项,取"two.sided"(默认值)表示双侧检验,取"less"表示备择假设为“<”的单侧检验,取"greater"表示备择假设为“>”的单侧检验.mu为参数M0,默认值为0.
paired为逻辑变量,用于说明是否完成配对(或成对)数据的检验.当数据是成对数据时,此参数取TRUE;否则取FALSE(默认值).
exact为逻辑变量,表示是否精确计算P值.此参数只对小样本数据起作用,当样本量较大时,软件采用正态分布近似计算P值.
correct是逻辑变量,表示是否对统计量作连续性修正,默认值为TRUE.
conf.int为逻辑变量,表示是否计算中位数的置信区间,默认值为FALSE.
conf.level为置信水平,默认值为0.95,它将用于计算中位数的置信区间.
...为附加参数.
另一种使用格式是公式形式,其使用格式为wilcox.test(formula, data, subset, na.action, ...)用于两总体样本的检验,参数formula为形如value ~ group的公式,其中value为数据,group为数据的分组情况,通常是因子向量.
data为矩阵或数据框.subset为可选向量,表示使用样本的子集.
na.action为函数,表示样本中出现缺失值(NA)的处理方法,默认值为函数getOption("na.action").
...为附加参数.
例1.18 试用Wilcoxon符号秩检验分析例1.17,北京的生活花费指数是在中位数之上还是在中位数之下?
解 设M为中位数,北京的生活花费指数是99,所以检验H0:M≥99 H1:M<99```javascript
> wilcox.test(X, mu = 99, al = "l")
Wilcoxon signed rank test with continuity correction
data: X
V = 679, p-value = 0.005091
alternative hypothesis: true location is less than 99P值(=0.005091)<0.05,
拒```
绝原假设,说明M<99,即北京的生活花费指数是在中位数之上.
例1.19 为了了解新的数学教学方法的效果是否比原来方法的效果有所提高,从水平相当的10名学生中随机地各选5名接受新方法和原方法的教学试验.充分长一段时间后,由专家通过各种方式(如考试提问等)对10名学生的数学能力予以综合评估(为公正起见,假定专家对各个学生属于哪一组并不知道),并按其数学能力由弱到强排序,结果如表1.6所示.对α=0.05,检验新方法是否比原方法显著地提高了教学效果.

5,无法拒绝原假设,即不能认为新方法的教学效果显著优于原方法.
例1.20 某医院用某种药物治疗两型慢性支气管炎患者共216例,疗效如表1.7所示.试分析该药物对两型慢性支气管炎的治疗效果是否相同.

解 可以想象,各病人的疗效用4个不同的值表示(1表示最好,4表示最差),这样就可以对216名病人排序,因此,可用Wilcoxon秩和检验来分析问题.> x <- rep```javascript
(1:4, c(62, 41, 14, 11))
> y <- rep(1:4, c(20, 37, 16, 15))
> wilcox.test(x, y)
Wilcoxon rank sum test with continuity correction
data: x and y
W = 3994, p-value = 0.0001242
alternative hypothesis: true location shift is not equal to 0P值(=0.0001242)
<```
0.05,拒绝原假设,即认为该药物对两型慢性支气管炎的治疗效果是不相同的.